
In computer science, a binary search tree (BST), also called an ordered or sorted binary tree, is a rooted binary tree data structure with the key of each internal node being greater than all the keys in the respective node's left subtree and less than the ones in its right subtree. The time complexity of operations on the binary search tree is linear with respect to the height of the tree.

In computer science, heapsort is a comparison-based sorting algorithm which can be thought of as "an implementation of selection sort using the right data structure." Like selection sort, heapsort divides its input into a sorted and an unsorted region, and it iteratively shrinks the unsorted region by extracting the largest element from it and inserting it into the sorted region. Unlike selection sort, heapsort does not waste time with a linear-time scan of the unsorted region; rather, heap sort maintains the unsorted region in a heap data structure to efficiently find the largest element in each step.

In computer science, a heap is a specialized tree-based data structure that satisfies the heap property: In a max heap, for any given node C, if P is a parent node of C, then the key of P is greater than or equal to the key of C. In a min heap, the key of P is less than or equal to the key of C. The node at the "top" of the heap is called the root node.

In computer science, merge sort is an efficient, general-purpose, and comparison-based sorting algorithm. Most implementations produce a stable sort, which means that the relative order of equal elements is the same in the input and output. Merge sort is a divide-and-conquer algorithm that was invented by John von Neumann in 1945. A detailed description and analysis of bottom-up merge sort appeared in a report by Goldstine and von Neumann as early as 1948.

A binary heap is a heap data structure that takes the form of a binary tree. Binary heaps are a common way of implementing priority queues. The binary heap was introduced by J. W. J. Williams in 1964, as a data structure for heapsort.
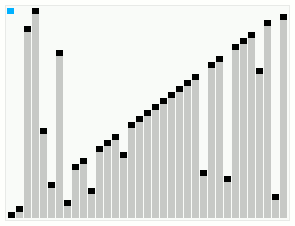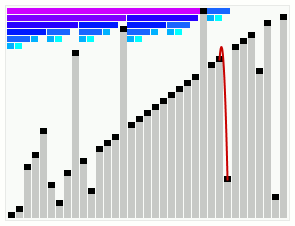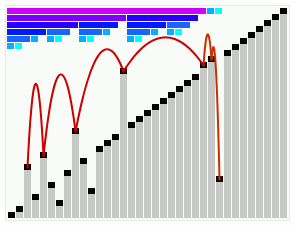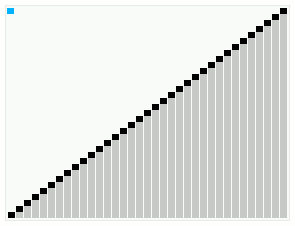
In computer science, smoothsort is a comparison-based sorting algorithm. A variant of heapsort, it was invented and published by Edsger Dijkstra in 1981. Like heapsort, smoothsort is an in-place algorithm with an upper bound of O(n log n) operations (see big O notation), but it is not a stable sort. The advantage of smoothsort is that it comes closer to O(n) time if the input is already sorted to some degree, whereas heapsort averages O(n log n) regardless of the initial sorted state.

In computer science, the treap and the randomized binary search tree are two closely related forms of binary search tree data structures that maintain a dynamic set of ordered keys and allow binary searches among the keys. After any sequence of insertions and deletions of keys, the shape of the tree is a random variable with the same probability distribution as a random binary tree; in particular, with high probability its height is proportional to the logarithm of the number of keys, so that each search, insertion, or deletion operation takes logarithmic time to perform.

In computer science, a self-balancing binary search tree (BST) is any node-based binary search tree that automatically keeps its height small in the face of arbitrary item insertions and deletions. These operations when designed for a self-balancing binary search tree, contain precautionary measures against boundlessly increasing tree height, so that these abstract data structures receive the attribute "self-balancing".
In computer science, a selection algorithm is an algorithm for finding the th smallest value in a collection of ordered values, such as numbers. The value that it finds is called the th order statistic. Selection includes as special cases the problems of finding the minimum, median, and maximum element in the collection. Selection algorithms include quickselect, and the median of medians algorithm. When applied to a collection of values, these algorithms take linear time, as expressed using big O notation. For data that is already structured, faster algorithms may be possible; as an extreme case, selection in an already-sorted array takes time .

In computer science, a k-d tree is a space-partitioning data structure for organizing points in a k-dimensional space. K-dimensional is that which concerns exactly k orthogonal axes or a space of any number of dimensions. k-d trees are a useful data structure for several applications, such as:

A comparison sort is a type of sorting algorithm that only reads the list elements through a single abstract comparison operation that determines which of two elements should occur first in the final sorted list. The only requirement is that the operator forms a total preorder over the data, with:
- if a ≤ b and b ≤ c then a ≤ c (transitivity)
- for all a and b, a ≤ b or b ≤ a (connexity).
A sorting algorithm falls into the adaptive sort family if it takes advantage of existing order in its input. It benefits from the presortedness in the input sequence – or a limited amount of disorder for various definitions of measures of disorder – and sorts faster. Adaptive sorting is usually performed by modifying existing sorting algorithms.
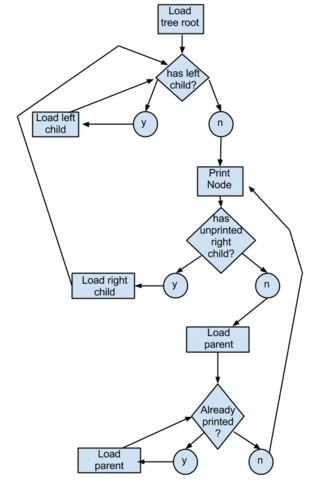
A tree sort is a sort algorithm that builds a binary search tree from the elements to be sorted, and then traverses the tree (in-order) so that the elements come out in sorted order. Its typical use is sorting elements online: after each insertion, the set of elements seen so far is available in sorted order.
The d-ary heap or d-heap is a priority queue data structure, a generalization of the binary heap in which the nodes have d children instead of 2. Thus, a binary heap is a 2-heap, and a ternary heap is a 3-heap. According to Tarjan and Jensen et al., d-ary heaps were invented by Donald B. Johnson in 1975.

In computer science, the segment tree is a data structure used for storing information about intervals or segments. It allows querying which of the stored segments contain a given point. A similar data structure is the interval tree.

In computer science, a Cartesian tree is a binary tree derived from a sequence of distinct numbers. To construct the Cartesian tree, set its root to be the minimum number in the sequence, and recursively construct its left and right subtrees from the subsequences before and after this number. It is uniquely defined as a min-heap whose symmetric (in-order) traversal returns the original sequence.
In computer science, a min-max heap is a complete binary tree data structure which combines the usefulness of both a min-heap and a max-heap, that is, it provides constant time retrieval and logarithmic time removal of both the minimum and maximum elements in it. This makes the min-max heap a very useful data structure to implement a double-ended priority queue. Like binary min-heaps and max-heaps, min-max heaps support logarithmic insertion and deletion and can be built in linear time. Min-max heaps are often represented implicitly in an array; hence it's referred to as an implicit data structure.
In computer science, an optimal binary search tree (Optimal BST), sometimes called a weight-balanced binary tree, is a binary search tree which provides the smallest possible search time (or expected search time) for a given sequence of accesses (or access probabilities). Optimal BSTs are generally divided into two types: static and dynamic.
In computer science, a weak heap is a data structure for priority queues, combining features of the binary heap and binomial heap. It can be stored in an array as an implicit binary tree like a binary heap, and has the efficiency guarantees of binomial heaps.





