ATC software
| | This section is empty. You can help by adding to it. (August 2023) |
Automatic taxonomy construction (ATC) is the use of software programs to generate taxonomical classifications from a body of texts called a corpus. ATC is a branch of natural language processing, which in turn is a branch of artificial intelligence.
A taxonomy (or taxonomical classification) is a scheme of classification, especially, a hierarchical classification, in which things are organized into groups or types. [1] [2] [3] [4] [5] [6] Among other things, a taxonomy can be used to organize and index knowledge (stored as documents, articles, videos, etc.), such as in the form of a library classification system, or a search engine taxonomy, so that users can more easily find the information they are searching for. Many taxonomies are hierarchies (and thus, have an intrinsic tree structure), but not all are.
Manually developing and maintaining a taxonomy is a labor-intensive task requiring significant time and resources, including familiarity of or expertise in the taxonomy's domain (scope, subject, or field), which drives the costs and limits the scope of such projects. Also, domain modelers have their own points of view which inevitably, even if unintentionally, work their way into the taxonomy. ATC uses artificial intelligence techniques to quickly automatically generate a taxonomy for a domain in order to avoid these problems and remove limitations.
There are several approaches to ATC. One approach is to use rules to detect patterns in the corpus and use those patterns to infer relations such as hyponymy. Other approaches use machine learning techniques such as Bayesian inferencing and Artificial Neural Networks. [7]
One approach to building a taxonomy is to automatically gather the keywords from a domain using keyword extraction, then analyze the relationships between them (see Hyponymy, below), and then arrange them as a taxonomy based on those relationships.
In ATC programs, one of the most important tasks is the discovery of hypernym and hyponym relations among words. One way to do that from a body of text is to search for certain phrases like "is a" and "such as".
In linguistics, is-a relations are called hyponymy. Words that describe categories are called hypernyms and words that are examples of categories are hyponyms. For example, dog is a hypernym and Fido is one of its hyponyms. A word can be both a hyponym and a hypernym. So, dog is a hyponym of mammal and also a hypernym of Fido.
Taxonomies are often represented as is-a hierarchies where each level is more specific than (in mathematical language "a subset of") the level above it. For example, a basic biology taxonomy would have concepts such as mammal, which is a subset of animal, and dogs and cats, which are subsets of mammal. This kind of taxonomy is called an is-a model because the specific objects are considered instances of a concept. For example, Fido is-a instance of the concept dog and Fluffy is-a cat. [8]
ATC can be used to build taxonomies for search engines, to improve search results.
ATC systems are a key component of ontology learning (also known as automatic ontology construction), and have been used to automatically generate large ontologies for domains such as insurance and finance. They have also been used to enhance existing large networks such as Wordnet to make them more complete and consistent. [9] [10] [11]
| | This section is empty. You can help by adding to it. (August 2023) |
Other names for automatic taxonomy construction include:

A semantic network, or frame network is a knowledge base that represents semantic relations between concepts in a network. This is often used as a form of knowledge representation. It is a directed or undirected graph consisting of vertices, which represent concepts, and edges, which represent semantic relations between concepts, mapping or connecting semantic fields. A semantic network may be instantiated as, for example, a graph database or a concept map. Typical standardized semantic networks are expressed as semantic triples.
WordNet is a lexical database of semantic relations between words that links words into semantic relations including synonyms, hyponyms, and meronyms. The synonyms are grouped into synsets with short definitions and usage examples. It can thus be seen as a combination and extension of a dictionary and thesaurus. While it is accessible to human users via a web browser, its primary use is in automatic text analysis and artificial intelligence applications. It was first created in the English language and the English WordNet database and software tools have been released under a BSD style license and are freely available for download from that WordNet website. There are now WordNets in more than 200 languages.
In information science, an ontology encompasses a representation, formal naming, and definitions of the categories, properties, and relations between the concepts, data, or entities that pertain to one, many, or all domains of discourse. More simply, an ontology is a way of showing the properties of a subject area and how they are related, by defining a set of terms and relational expressions that represent the entities in that subject area. The field which studies ontologies so conceived is sometimes referred to as applied ontology.

A synonym is a word, morpheme, or phrase that means exactly or nearly the same as another word, morpheme, or phrase in a given language. For example, in the English language, the words begin, start, commence, and initiate are all synonyms of one another: they are synonymous. The standard test for synonymy is substitution: one form can be replaced by another in a sentence without changing its meaning. Words are considered synonymous in only one particular sense: for example, long and extended in the context long time or extended time are synonymous, but long cannot be used in the phrase extended family. Synonyms with exactly the same meaning share a seme or denotational sememe, whereas those with inexactly similar meanings share a broader denotational or connotational sememe and thus overlap within a semantic field. The former are sometimes called cognitive synonyms and the latter, near-synonyms, plesionyms or poecilonyms.

A glossary, also known as a vocabulary or clavis, is an alphabetical list of terms in a particular domain of knowledge with the definitions for those terms. Traditionally, a glossary appears at the end of a book and includes terms within that book that are either newly introduced, uncommon, or specialized. While glossaries are most commonly associated with non-fiction books, in some cases, fiction novels sometimes include a glossary for unfamiliar terms.
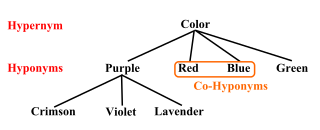
Hyponymy and hypernymy are semantic relations between a term belonging in a set that is defined by another term and the latter. In other words, the relationship of a subtype (hyponym) and the supertype. The semantic field of the hyponym is included within that of the hypernym. For example, pigeon, crow, and eagle are all hyponyms of bird, their hypernym.
Semantic similarity is a metric defined over a set of documents or terms, where the idea of distance between items is based on the likeness of their meaning or semantic content as opposed to lexicographical similarity. These are mathematical tools used to estimate the strength of the semantic relationship between units of language, concepts or instances, through a numerical description obtained according to the comparison of information supporting their meaning or describing their nature. The term semantic similarity is often confused with semantic relatedness. Semantic relatedness includes any relation between two terms, while semantic similarity only includes "is a" relations. For example, "car" is similar to "bus", but is also related to "road" and "driving".

Automatic image annotation is the process by which a computer system automatically assigns metadata in the form of captioning or keywords to a digital image. This application of computer vision techniques is used in image retrieval systems to organize and locate images of interest from a database.
In information science and ontology, a classification scheme is the product of arranging things into kinds of things (classes) or into groups of classes; this bears similarity to categorization, but with perhaps a more theoretical bent, as classification can be applied over a wide semantic spectrum.
Terminology extraction is a subtask of information extraction. The goal of terminology extraction is to automatically extract relevant terms from a given corpus.
The concept of the Social Semantic Web subsumes developments in which social interactions on the Web lead to the creation of explicit and semantically rich knowledge representations. The Social Semantic Web can be seen as a Web of collective knowledge systems, which are able to provide useful information based on human contributions and which get better as more people participate. The Social Semantic Web combines technologies, strategies and methodologies from the Semantic Web, social software and the Web 2.0.

Ontology learning is the automatic or semi-automatic creation of ontologies, including extracting the corresponding domain's terms and the relationships between the concepts that these terms represent from a corpus of natural language text, and encoding them with an ontology language for easy retrieval. As building ontologies manually is extremely labor-intensive and time-consuming, there is great motivation to automate the process.
A relationship extraction task requires the detection and classification of semantic relationship mentions within a set of artifacts, typically from text or XML documents. The task is very similar to that of information extraction (IE), but IE additionally requires the removal of repeated relations (disambiguation) and generally refers to the extraction of many different relationships.

In computer science, information science and systems engineering, ontology engineering is a field which studies the methods and methodologies for building ontologies, which encompasses a representation, formal naming and definition of the categories, properties and relations between the concepts, data and entities of a given domain of interest. In a broader sense, this field also includes a knowledge construction of the domain using formal ontology representations such as OWL/RDF. A large-scale representation of abstract concepts such as actions, time, physical objects and beliefs would be an example of ontological engineering. Ontology engineering is one of the areas of applied ontology, and can be seen as an application of philosophical ontology. Core ideas and objectives of ontology engineering are also central in conceptual modeling.
Knowledge extraction is the creation of knowledge from structured and unstructured sources. The resulting knowledge needs to be in a machine-readable and machine-interpretable format and must represent knowledge in a manner that facilitates inferencing. Although it is methodically similar to information extraction (NLP) and ETL, the main criterion is that the extraction result goes beyond the creation of structured information or the transformation into a relational schema. It requires either the reuse of existing formal knowledge or the generation of a schema based on the source data.
In natural language processing, semantic compression is a process of compacting a lexicon used to build a textual document by reducing language heterogeneity, while maintaining text semantics. As a result, the same ideas can be represented using a smaller set of words.
Taxonomy is the practice and science of categorization or classification.
The following outline is provided as an overview of and topical guide to natural-language processing:
Taxonomy for search engines refers to classification methods that improve relevance in vertical search. Taxonomies of entities are tree structures whose nodes are labelled with entities likely to occur in a web search query. Searches use these trees to match keywords from a search query to keywords from answers.
The Computer Science Ontology (CSO) is an automatically generated taxonomy of research topics in the field of Computer Science. It was produced by the Open University in collaboration with Springer Nature by running an information extraction system over a large corpus of scientific articles. Several branches were manually improved by domain experts. The current version includes about 14K research topics and 160K semantic relationships.
{{cite journal}}: Cite journal requires |journal= (help)