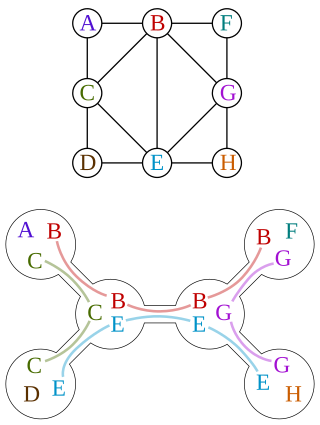
In backtrackingalgorithms, backjumping is a technique that reduces search space, therefore increasing efficiency. While backtracking always goes up one level in the search tree when all values for a variable have been tested, backjumping may go up more levels. In this article, a fixed order of evaluation of variables is used, but the same considerations apply to a dynamic order of evaluation.
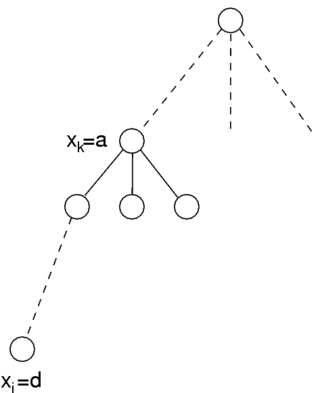
Whenever backtracking has tried all values for a variable without finding any solution, it reconsiders the last of the previously assigned variables, changing its value or further backtracking if no other values are to be tried. If is the current partial assignment and all values for have been tried without finding a solution, backtracking concludes that no solution extending exists. The algorithm then "goes up" to , changing 's value if possible, backtracking again otherwise.
The partial assignment is not always necessary in full to prove that no value of leads to a solution. In particular, a prefix of the partial assignment may have the same property, that is, there exists an index such that cannot be extended to form a solution with whatever value for . If the algorithm can prove this fact, it can directly consider a different value for instead of reconsidering as it would normally do.
An example in which the current assignment to has been unsuccessfully tried with every possible value of . Backtracking goes back to , trying to assign it a new value.
Instead of backtracking, the algorithm makes some further elaboration, proving that the evaluations , , and are not part of any solution.
As a result, the current evaluation of is not part of any solution, and the algorithm can directly backjump to , trying a new value for it.
The efficiency of a backjumping algorithm depends on how high it is able to backjump. Ideally, the algorithm could jump from to whichever variable is such that the current assignment to cannot be extended to form a solution with any value of . If this is the case, is called a safe jump.
Establishing whether a jump is safe is not always feasible, as safe jumps are defined in terms of the set of solutions, which is what the algorithm is trying to find. In practice, backjumping algorithms use the lowest index they can efficiently prove to be a safe jump. Different algorithms use different methods for determining whether a jump is safe. These methods have different costs, but a higher cost of finding a higher safe jump may be traded off a reduced amount of search due to skipping parts of the search tree.
Backjumping at leaf nodes
The simplest condition in which backjumping is possible is when all values of a variable have been proved inconsistent without further branching. In constraint satisfaction, a partial evaluation is consistent if and only if it satisfies all constraints involving the assigned variables, and inconsistent otherwise. It might be the case that a consistent partial solution cannot be extended to a consistent complete solution because some of the unassigned variables may not be assigned without violating other constraints.
The condition in which all values of a given variable are inconsistent with the current partial solution is called a leaf dead end. This happens exactly when the variable is a leaf of the search tree (which correspond to nodes having only leaves as children in the figures of this article.)
The backjumping algorithm by John Gaschnig does a backjump only in leaf dead ends. In other words, it works differently from backtracking only when every possible value of has been tested and resulted inconsistent without the need of branching over another variable.
A safe jump can be found by simply evaluating, for every value , the shortest prefix of inconsistent with . In other words, if is a possible value for , the algorithm checks the consistency of the following evaluations:
...
...
...
The smallest index (lowest the listing) for which evaluations are inconsistent would be a safe jump if were the only possible value for . Since every variable can usually take more than one value, the maximal index that comes out from the check for each value is a safe jump, and is the point where John Gaschnig's algorithm jumps.
In practice, the algorithm can check the evaluations above at the same time it is checking the consistency of .
Backjumping at internal nodes
The previous algorithm only backjumps when the values of a variable can be shown inconsistent with the current partial solution without further branching. In other words, it allows for a backjump only at leaf nodes in the search tree.
An internal node of the search tree represents an assignment of a variable that is consistent with the previous ones. If no solution extends this assignment, the previous algorithm always backtracks: no backjump is done in this case.
Backjumping at internal nodes cannot be done as for leaf nodes. Indeed, if some evaluations of required branching, it is because they are consistent with the current assignment. As a result, searching for a prefix that is inconsistent with these values of the last variable does not succeed.
In such cases, what proved an evaluation not to be part of a solution with the current partial evaluation is the recursive search. In particular, the algorithm "knows" that no solution exists from this point on because it comes back to this node instead of stopping after having found a solution.
This return is due to a number of dead ends, points where the algorithm has proved a partial solution inconsistent. In order to further backjump, the algorithm has to take into account that the impossibility of finding solutions is due to these dead ends. In particular, the safe jumps are indexes of prefixes that still make these dead ends to be inconsistent partial solutions.
In this example, the algorithm come back to , after trying all its possible values, because of the three crossed points of inconsistency.
The second point remains inconsistent even if the values of and are removed from its partial evaluation (note that the values of a variable are in its children)
The other inconsistent evaluations remains so even without , , and
The algorithm can backjump to since this is the lowest variables that maintains all inconsistencies. A new value for will be tried.
In other words, when all values of have been tried, the algorithm can backjump to a previous variable provided that the current truth evaluation of is inconsistent with all the truth evaluations of in the leaf nodes that are descendants of the node .
Simplifications
While looking for a possible backjump for or one its ancestors, all nodes in the shaded area can be ignored.
Due to the potentially high number of nodes that are in the subtree of , the information that is necessary to safely backjump from is collected during the visit of its subtree. Finding a safe jump can be simplified by two considerations. The first is that the algorithm needs a safe jump, but still works with a jump that is not the highest possible safe jump.
The second simplification is that nodes in the subtree of that have been skipped by a backjump can be ignored while looking for a backjump for . More precisely, all nodes skipped by a backjump from node up to node are irrelevant to the subtree rooted at , and also irrelevant are their other subtrees.
Indeed, if an algorithm went down from node to via a path but backjumps in its way back, then it could have gone directly from to instead. Indeed, the backjump indicates that the nodes between and are irrelevant to the subtree rooted at . In other words, a backjump indicates that the visit of a region of the search tree had been a mistake. This part of the search tree can therefore be ignored when considering a possible backjump from or from one of its ancestors.
Variables whose values are sufficient to prove unsatisfiability in the subtree rooted at a node are collected in the node and sent (after removing the variable of the node) to the node above when retracting.
This fact can be exploited by collecting, in each node, a set of previously assigned variables whose evaluation suffices to prove that no solution exists in the subtree rooted at the node. This set is built during the execution of the algorithm. When retracting from a node, this set is removed the variable of the node and collected in the set of the destination of backtracking or backjumping. Since nodes that are skipped from backjumping are never retracted from, their sets are automatically ignored.
Graph-based backjumping
The rationale of graph-based backjumping is that a safe jump can be found by checking which of the variables are in a constraint with the variables that are instantiated in leaf nodes. For every leaf node and every variable of index that is instantiated there, the indexes less than or equal to whose variable is in a constraint with can be used to find safe jumps. In particular, when all values for have been tried, this set contains the indexes of the variables whose evaluations allow proving that no solution can be found by visiting the subtree rooted at . As a result, the algorithm can backjump to the highest index in this set.
The fact that nodes skipped by backjumping can be ignored when considering a further backjump can be exploited by the following algorithm. When retracting from a leaf node, the set of variables that are in constraint with it is created and "sent back" to its parent, or ancestor in case of backjumping. At every internal node, a set of variables is maintained. Every time a set of variables is received from one of its children or descendants, their variables are added to the maintained set. When further backtracking or backjumping from the node, the variable of the node is removed from this set, and the set is sent to the node that is the destination of backtracking or backjumping. This algorithm works because the set maintained in a node collects all variables that are relevant to prove unsatisfiability in the leaves that are descendants of this node. Since sets of variables are only sent when retracing from nodes, the sets collected at nodes skipped by backjumping are automatically ignored.
Conflict-based backjumping
Conflict-based backjumping (a.k.a. conflict-directed backjumping) is a more refined algorithm and sometimes able to achieve larger backjumps. It is based on checking not only the common presence of two variables in the same constraint but also on whether the constraint actually caused any inconsistency. In particular, this algorithm collects one of the violated constraints in every leaf. At every node, the highest index of a variable that is in one of the constraints collected at the leaves is a safe jump.
While the violated constraint chosen in each leaf does not affect the safety of the resulting jump, choosing constraints of highest possible indices increases the highness of the jump. For this reason, conflict-based backjumping orders constraints in such a way that constraints over lower indices variables are preferred over constraints on higher index variables.
Formally, a constraint is preferred over another one if the highest index of a variable in but not in is lower than the highest index of a variable in but not in . In other words, excluding common variables, the constraint that has the all lower indices is preferred.
In a leaf node, the algorithm chooses the lowest index such that is inconsistent with the last variable evaluated in the leaf. Among the constraints that are violated in this evaluation, it chooses the most preferred one, and collects all its indices less than . This way, when the algorithm comes back to the variable , the lowest collected index identifies a safe jump.
In practice, this algorithm is simplified by collecting all indices in a single set, instead of creating a set for every value of . In particular, the algorithm collects, in each node, all sets coming from its descendants that have not been skipped by backjumping. When retracting from this node, this set is removed the variable of the node and collected into the destination of backtracking or backjumping.
In graph theory, a tree decomposition is a mapping of a graph into a tree that can be used to define the treewidth of the graph and speed up solving certain computational problems on the graph.
Constraint programming (CP) is a paradigm for solving combinatorial problems that draws on a wide range of techniques from artificial intelligence, computer science, and operations research. In constraint programming, users declaratively state the constraints on the feasible solutions for a set of decision variables. Constraints differ from the common primitives of imperative programming languages in that they do not specify a step or sequence of steps to execute, but rather the properties of a solution to be found. In addition to constraints, users also need to specify a method to solve these constraints. This typically draws upon standard methods like chronological backtracking and constraint propagation, but may use customized code like a problem-specific branching heuristic.
Constraint satisfaction problems (CSPs) are mathematical questions defined as a set of objects whose state must satisfy a number of constraints or limitations. CSPs represent the entities in a problem as a homogeneous collection of finite constraints over variables, which is solved by constraint satisfaction methods. CSPs are the subject of research in both artificial intelligence and operations research, since the regularity in their formulation provides a common basis to analyze and solve problems of many seemingly unrelated families. CSPs often exhibit high complexity, requiring a combination of heuristics and combinatorial search methods to be solved in a reasonable time. Constraint programming (CP) is the field of research that specifically focuses on tackling these kinds of problems. Additionally, the Boolean satisfiability problem (SAT), satisfiability modulo theories (SMT), mixed integer programming (MIP) and answer set programming (ASP) are all fields of research focusing on the resolution of particular forms of the constraint satisfaction problem.
Backtracking is a class of algorithms for finding solutions to some computational problems, notably constraint satisfaction problems, that incrementally builds candidates to the solutions, and abandons a candidate ("backtracks") as soon as it determines that the candidate cannot possibly be completed to a valid solution.
In computer science, the treap and the randomized binary search tree are two closely related forms of binary search tree data structures that maintain a dynamic set of ordered keys and allow binary searches among the keys. After any sequence of insertions and deletions of keys, the shape of the tree is a random variable with the same probability distribution as a random binary tree; in particular, with high probability its height is proportional to the logarithm of the number of keys, so that each search, insertion, or deletion operation takes logarithmic time to perform.
In computer science, corecursion is a type of operation that is dual to recursion. Whereas recursion works analytically, starting on data further from a base case and breaking it down into smaller data and repeating until one reaches a base case, corecursion works synthetically, starting from a base case and building it up, iteratively producing data further removed from a base case. Put simply, corecursive algorithms use the data that they themselves produce, bit by bit, as they become available, and needed, to produce further bits of data. A similar but distinct concept is generative recursion, which may lack a definite "direction" inherent in corecursion and recursion.
In constraint satisfaction, local consistency conditions are properties of constraint satisfaction problems related to the consistency of subsets of variables or constraints. They can be used to reduce the search space and make the problem easier to solve. Various kinds of local consistency conditions are leveraged, including node consistency, arc consistency, and path consistency.
In constraint satisfaction, backmarking is a variant of the backtracking algorithm.
In backtracking algorithms, look ahead is the generic term for a subprocedure that attempts to foresee the effects of choosing a branching variable to evaluate one of its values. The two main aims of look-ahead are to choose a variable to evaluate next and to choose the order of values to assign to it.
In constraint satisfaction backtracking algorithms, constraint learning is a technique for improving efficiency. It works by recording new constraints whenever an inconsistency is found. This new constraint may reduce the search space, as future partial evaluations may be found inconsistent without further search. Clause learning is the name of this technique when applied to propositional satisfiability.
In constraint satisfaction, local search is an incomplete method for finding a solution to a problem. It is based on iteratively improving an assignment of the variables until all constraints are satisfied. In particular, local search algorithms typically modify the value of a variable in an assignment at each step. The new assignment is close to the previous one in the space of assignment, hence the name local search.
In mathematical optimization, constrained optimization is the process of optimizing an objective function with respect to some variables in the presence of constraints on those variables. The objective function is either a cost function or energy function, which is to be minimized, or a reward function or utility function, which is to be maximized. Constraints can be either hard constraints, which set conditions for the variables that are required to be satisfied, or soft constraints, which have some variable values that are penalized in the objective function if, and based on the extent that, the conditions on the variables are not satisfied.
Within artificial intelligence and operations research for constraint satisfaction a hybrid algorithm solves a constraint satisfaction problem by the combination of two different methods, for example variable conditioning and constraint inference
Constraint logic programming is a form of constraint programming, in which logic programming is extended to include concepts from constraint satisfaction. A constraint logic program is a logic program that contains constraints in the body of clauses. An example of a clause including a constraint is A(X,Y):-X+Y>0,B(X),C(Y). In this clause, X+Y>0 is a constraint; A(X,Y), B(X), and C(Y) are literals as in regular logic programming. This clause states one condition under which the statement A(X,Y) holds: X+Y is greater than zero and both B(X) and C(Y) are true.
The complexity of constraint satisfaction is the application of computational complexity theory to constraint satisfaction. It has mainly been studied for discriminating between tractable and intractable classes of constraint satisfaction problems on finite domains.
In constraint satisfaction, a decomposition method translates a constraint satisfaction problem into another constraint satisfaction problem that is binary and acyclic. Decomposition methods work by grouping variables into sets, and solving a subproblem for each set. These translations are done because solving binary acyclic problems is a tractable problem.
In artificial intelligence and operations research, a Weighted Constraint Satisfaction Problem (WCSP), also known as Valued Constraint Satisfaction Problem (VCSP), is a generalization of a constraint satisfaction problem (CSP) where some of the constraints can be violated and in which preferences among solutions can be expressed. This generalization makes it possible to represent more real-world problems, in particular those that are over-constrained, or those where we want to find a minimal-cost solution among multiple possible solutions.
In computer science, conflict-driven clause learning (CDCL) is an algorithm for solving the Boolean satisfiability problem (SAT). Given a Boolean formula, the SAT problem asks for an assignment of variables so that the entire formula evaluates to true. The internal workings of CDCL SAT solvers were inspired by DPLL solvers. The main difference between CDCL and DPLL is that CDCL's backjumping is non-chronological.
In computer science, an interchangeability algorithm is a technique used to more efficiently solve constraint satisfaction problems (CSP). A CSP is a mathematical problem in which objects, represented by variables, are subject to constraints on the values of those variables; the goal in a CSP is to assign values to the variables that are consistent with the constraints. If two variables A and B in a CSP may be swapped for each other without changing the nature of the problem or its solutions, then A and B are interchangeable variables. Interchangeable variables represent a symmetry of the CSP and by exploiting that symmetry, the search space for solutions to a CSP problem may be reduced. For example, if solutions with A=1 and B=2 have been tried, then by interchange symmetry, solutions with B=1 and A=2 need not be investigated.
In computer science, parallel tree contraction is a broadly applicable technique for the parallel solution of a large number of tree problems, and is used as an algorithm design technique for the design of a large number of parallel graph algorithms. Parallel tree contraction was introduced by Gary L. Miller and John H. Reif, and has subsequently been modified to improve efficiency by X. He and Y. Yesha, Hillel Gazit, Gary L. Miller and Shang-Hua Teng and many others.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.

 A search tree visited by regular backtracking
A search tree visited by regular backtracking A backjump: the grey node is not visited
A backjump: the grey node is not visited