Related Research Articles
Flann is both an English surname and an Irish masculine given name, but has also been used as a feminine given name. It might refer to:
Computational geometry is a branch of computer science devoted to the study of algorithms which can be stated in terms of geometry. Some purely geometrical problems arise out of the study of computational geometric algorithms, and such problems are also considered to be part of computational geometry. While modern computational geometry is a recent development, it is one of the oldest fields of computing with a history stretching back to antiquity.

Nonlinear dimensionality reduction, also known as manifold learning, refers to various related techniques that aim to project high-dimensional data onto lower-dimensional latent manifolds, with the goal of either visualizing the data in the low-dimensional space, or learning the mapping itself. The techniques described below can be understood as generalizations of linear decomposition methods used for dimensionality reduction, such as singular value decomposition and principal component analysis.

An octree is a tree data structure in which each internal node has exactly eight children. Octrees are most often used to partition a three-dimensional space by recursively subdividing it into eight octants. Octrees are the three-dimensional analog of quadtrees. The word is derived from oct + tree. Octrees are often used in 3D graphics and 3D game engines.

R-trees are tree data structures used for spatial access methods, i.e., for indexing multi-dimensional information such as geographical coordinates, rectangles or polygons. The R-tree was proposed by Antonin Guttman in 1984 and has found significant use in both theoretical and applied contexts. A common real-world usage for an R-tree might be to store spatial objects such as restaurant locations or the polygons that typical maps are made of: streets, buildings, outlines of lakes, coastlines, etc. and then find answers quickly to queries such as "Find all museums within 2 km of my current location", "retrieve all road segments within 2 km of my location" or "find the nearest gas station". The R-tree can also accelerate nearest neighbor search for various distance metrics, including great-circle distance.
The scale-invariant feature transform (SIFT) is a computer vision algorithm to detect, describe, and match local features in images, invented by David Lowe in 1999. Applications include object recognition, robotic mapping and navigation, image stitching, 3D modeling, gesture recognition, video tracking, individual identification of wildlife and match moving.

In computer science, a k-d tree is a space-partitioning data structure for organizing points in a k-dimensional space. k-d trees are a useful data structure for several applications, such as searches involving a multidimensional search key and creating point clouds. k-d trees are a special case of binary space partitioning trees.
In statistics, the k-nearest neighbors algorithm (k-NN) is a non-parametric supervised learning method first developed by Evelyn Fix and Joseph Hodges in 1951, and later expanded by Thomas Cover. It is used for classification and regression. In both cases, the input consists of the k closest training examples in a data set. The output depends on whether k-NN is used for classification or regression:
A vantage-point tree is a metric tree that segregates data in a metric space by choosing a position in the space and partitioning the data points into two parts: those points that are nearer to the vantage point than a threshold, and those points that are not. By recursively applying this procedure to partition the data into smaller and smaller sets, a tree data structure is created where neighbors in the tree are likely to be neighbors in the space.
A metric tree is any tree data structure specialized to index data in metric spaces. Metric trees exploit properties of metric spaces such as the triangle inequality to make accesses to the data more efficient. Examples include the M-tree, vp-trees, cover trees, MVP trees, and BK-trees.
Nearest neighbor search (NNS), as a form of proximity search, is the optimization problem of finding the point in a given set that is closest to a given point. Closeness is typically expressed in terms of a dissimilarity function: the less similar the objects, the larger the function values.

The closest pair of points problem or closest pair problem is a problem of computational geometry: given points in metric space, find a pair of points with the smallest distance between them. The closest pair problem for points in the Euclidean plane was among the first geometric problems that were treated at the origins of the systematic study of the computational complexity of geometric algorithms.
In computer science, locality-sensitive hashing (LSH) is an algorithmic technique that hashes similar input items into the same "buckets" with high probability. Since similar items end up in the same buckets, this technique can be used for data clustering and nearest neighbor search. It differs from conventional hashing techniques in that hash collisions are maximized, not minimized. Alternatively, the technique can be seen as a way to reduce the dimensionality of high-dimensional data; high-dimensional input items can be reduced to low-dimensional versions while preserving relative distances between items.
Similarity search is the most general term used for a range of mechanisms which share the principle of searching spaces of objects where the only available comparator is the similarity between any pair of objects. This is becoming increasingly important in an age of large information repositories where the objects contained do not possess any natural order, for example large collections of images, sounds and other sophisticated digital objects.
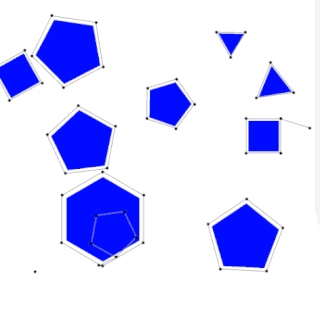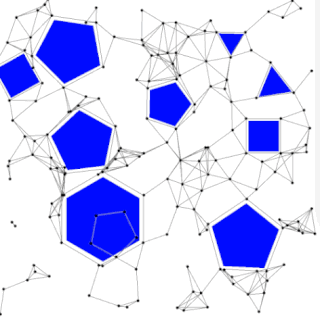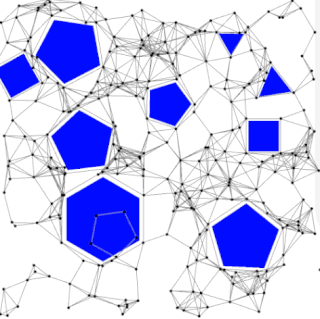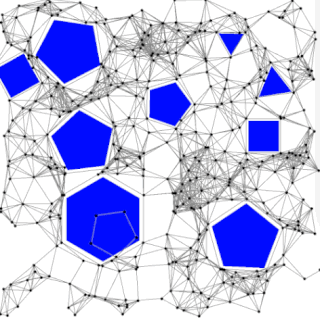
The probabilistic roadmap planner is a motion planning algorithm in robotics, which solves the problem of determining a path between a starting configuration of the robot and a goal configuration while avoiding collisions.
In pattern recognition, the iDistance is an indexing and query processing technique for k-nearest neighbor queries on point data in multi-dimensional metric spaces. The kNN query is one of the hardest problems on multi-dimensional data, especially when the dimensionality of the data is high. The iDistance is designed to process kNN queries in high-dimensional spaces efficiently and it is especially good for skewed data distributions, which usually occur in real-life data sets. The iDistance can be augmented with machine learning models to learn the data distributions for searching and storing the multi-dimensional data.
David Mount is a professor at the University of Maryland, College Park department of computer science whose research is in computational geometry.
In computer science, a ball tree, balltree or metric tree, is a space partitioning data structure for organizing points in a multi-dimensional space. The ball tree gets its name from the fact that it partitions data points into a nested set of intersecting hyperspheres known as "balls". The resulting data structure has characteristics that make it useful for a number of applications, most notably nearest neighbor search.
(1+ε)-approximate nearest neighbor search is a variant of the nearest neighbor search problem. A solution to the -approximate nearest neighbor search is a point or multiple points within distance R from a query point, where R is the distance between the query point and its true nearest neighbor.
In computer science, the cell-probe model is a model of computation similar to the random-access machine, except that all operations are free except memory access. This model is useful for proving lower bounds of algorithms for data structure problems.
References
- ↑ Beis, J.; Lowe, D. G. (1997). Shape indexing using approximate nearest-neighbour search in high-dimensional spaces. Conference on Computer Vision and Pattern Recognition. Puerto Rico. pp. 1000–1006. CiteSeerX 10.1.1.23.9493 .
- ↑ Shape Indexing Using Approximate Nearest-Neighbour Search in High-Dimensional Spaces, pp. 4-5
| | This algorithms or data structures-related article is a stub. You can help Wikipedia by expanding it. |