In grammar, a noun is a word that represents a concrete or abstract thing, such as living creatures, places, actions, qualities, states of existence, and ideas. A noun may serve as an object or subject within a phrase, clause, or sentence.

Bradford's law is a pattern first described by Samuel C. Bradford in 1934 that estimates the exponentially diminishing returns of searching for references in science journals. One formulation is that if journals in a field are sorted by number of articles into three groups, each with about one-third of all articles, then the number of journals in each group will be proportional to 1:n:n2. There are a number of related formulations of the principle.
Automatic summarization is the process of shortening a set of data computationally, to create a subset that represents the most important or relevant information within the original content. Artificial intelligence algorithms are commonly developed and employed to achieve this, specialized for different types of data.
A document-term matrix is a mathematical matrix that describes the frequency of terms that occur in a each document in a collection. In a document-term matrix, rows correspond to documents in the collection and columns correspond to terms. This matrix is a specific instance of a document-feature matrix where "features" may refer to other properties of a document besides terms. It is also common to encounter the transpose, or term-document matrix where documents are the columns and terms are the rows. They are useful in the field of natural language processing and computational text analysis.
Wiyot or Soulatluk (lit. 'your jaw') is an Algic language spoken by the Wiyot people of Humboldt Bay, California. The language's last native speaker, Della Prince, died in 1962.
In linguistics, a grammatical category or grammatical feature is a property of items within the grammar of a language. Within each category there are two or more possible values, which are normally mutually exclusive. Frequently encountered grammatical categories include:
In linguistics, coreference, sometimes written co-reference, occurs when two or more expressions refer to the same person or thing; they have the same referent. For example, in Bill said Alice would arrive soon, and she did, the words Alice and she refer to the same person.
In the field of information retrieval, divergence from randomness, one of the first models, is one type of probabilistic model. It is basically used to test the amount of information carried in the documents. It is based on Harter's 2-Poisson indexing-model. The 2-Poisson model has a hypothesis that the level of the documents is related to a set of documents which contains words occur relatively greater than the rest of the documents. It is not a 'model', but a framework for weighting terms using probabilistic methods, and it has a special relationship for term weighting based on notion of eliteness.
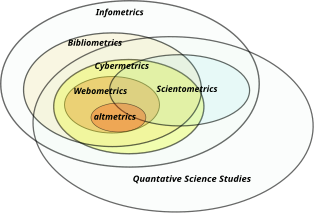
Informetrics is the study of quantitative aspects of information, it is an extension and evolution of traditional bibliometrics and scientometrics. Informetrics uses bibliometrics and scientometrics methods to study mainly the problems of literature information management and evaluation of science and technology. Informetrics is an independent discipline that uses quantitative methods from mathematics and statistics to study the process, phenomena, and law of informetrics. Informetrics has gained more attention as it is a common scientific method for academic evaluation, research hotspots in discipline, and trend analysis.
Argobba is an Ethiopian Semitic language spoken in several districts of Afar, Amhara, and Oromia regions of Ethiopia by the Argobba people. It belongs to the South Ethiopic languages subgroup, and is closely related to Amharic.
In information retrieval, tf–idf, short for term frequency–inverse document frequency, is a measure of importance of a word to a document in a collection or corpus, adjusted for the fact that some words appear more frequently in general. It was often used as a weighting factor in searches of information retrieval, text mining, and user modeling. A survey conducted in 2015 showed that 83% of text-based recommender systems in digital libraries used tf–idf.
Dissociated press is a parody generator. The generated text is based on another text using the Markov chain technique. The name is a play on "Associated Press" and the psychological term dissociation.
In information retrieval, an index term is a term that captures the essence of the topic of a document. Index terms make up a controlled vocabulary for use in bibliographic records. They are an integral part of bibliographic control, which is the function by which libraries collect, organize and disseminate documents. They are used as keywords to retrieve documents in an information system, for instance, a catalog or a search engine. A popular form of keywords on the web are tags, which are directly visible and can be assigned by non-experts. Index terms can consist of a word, phrase, or alphanumerical term. They are created by analyzing the document either manually with subject indexing or automatically with automatic indexing or more sophisticated methods of keyword extraction. Index terms can either come from a controlled vocabulary or be freely assigned.
A reciprocal pronoun is a pronoun that indicates a reciprocal relationship. A reciprocal pronoun can be used for one of the participants of a reciprocal construction, i.e. a clause in which two participants are in a mutual relationship. The reciprocal pronouns of English are one another and each other, and they form the category of anaphors along with reflexive pronouns.
Subject indexing is the act of describing or classifying a document by index terms, keywords, or other symbols in order to indicate what different documents are about, to summarize their contents or to increase findability. In other words, it is about identifying and describing the subject of documents. Indexes are constructed, separately, on three distinct levels: terms in a document such as a book; objects in a collection such as a library; and documents within a field of knowledge.
Document clustering is the application of cluster analysis to textual documents. It has applications in automatic document organization, topic extraction and fast information retrieval or filtering.

In systemic functional grammar (SFG), a nominal group is a group of words that represents or describes an entity, for example The nice old English police inspector who was sitting at the table with Mr Morse. Grammatically, the wording "The nice old English police inspector who was sitting at the table with Mr Morse" can be understood as a nominal group, which functions as the subject of the information exchange and as the person being identified as "Mr Morse".

Co-occurrence network, sometimes referred to as a semantic network, is a method to analyze text that includes a graphic visualization of potential relationships between people, organizations, concepts, biological organisms like bacteria or other entities represented within written material. The generation and visualization of co-occurrence networks has become practical with the advent of electronically stored text compliant to text mining.
Coupled Pattern Learner (CPL) is a machine learning algorithm which couples the semi-supervised learning of categories and relations to forestall the problem of semantic drift associated with boot-strap learning methods.

Jad (Dzad), also known as Bhotia and Tchhongsa, is a language spoken by a community of about 300 in the states of Uttarakhand and Himachal Pradesh, in India. It is spoken in several villages, and the three major villages are Jadhang, Nelang and Pulam Sumda in the Harsil sub-division of the Uttarkashi District. Jad is closely related to the Lahuli–Spiti language, which is another Tibetic language. Jad is spoken alongside Garhwali and Hindi. Code switching between Jad and Garhwali is very common. The language borrows some vocabulary from both Hindi and Garhwali. It is primarily a spoken language.