Related Research Articles

The client–server model is a distributed application structure that partitions tasks or workloads between the providers of a resource or service, called servers, and service requesters, called clients. Often clients and servers communicate over a computer network on separate hardware, but both client and server may be on the same device. A server host runs one or more server programs, which share their resources with clients. A client usually does not share any of its resources, but it requests content or service from a server. Clients, therefore, initiate communication sessions with servers, which await incoming requests. Examples of computer applications that use the client–server model are email, network printing, and the World Wide Web.

Peer-to-peer (P2P) computing or networking is a distributed application architecture that partitions tasks or workloads between peers. Peers are equally privileged, equipotent participants in the network, forming a peer-to-peer network of nodes. In addition, a personal area network (PAN) is also in nature a type of decentralized peer-to-peer network typically between two devices.
In telecommunications, provisioning involves the process of preparing and equipping a network to allow it to provide new services to its users. In National Security/Emergency Preparedness telecommunications services, "provisioning" equates to "initiation" and includes altering the state of an existing priority service or capability.

A web hosting service is a type of Internet hosting service that hosts websites for clients, i.e. it offers the facilities required for them to create and maintain a site and makes it accessible on the World Wide Web. Companies providing web hosting services are sometimes called web hosts.
Hypermedia, an extension of hypertext, is a nonlinear medium of information that includes graphics, audio, video, plain text and hyperlinks. This designation contrasts with the broader term multimedia, which may include non-interactive linear presentations as well as hypermedia. The term was first used in a 1965 article written by Ted Nelson. Hypermedia is a type of multimedia that features interactive elements, such as hypertext, buttons, or interactive images and videos, allowing users to navigate and engage with content in a non-linear manner.

Image sharing, or photo sharing, is the publishing or transfer of digital photos online. Image sharing websites offer services such as uploading, hosting, managing and sharing of photos. This function is provided through both websites and applications that facilitate the upload and display of images. The term can also be loosely applied to the use of online photo galleries that are set up and managed by individual users, including photoblogs. Sharing means that other users can view but not necessarily download images, and users can select different copyright options for their images.
Datagram Transport Layer Security (DTLS) is a communications protocol providing security to datagram-based applications by allowing them to communicate in a way designed to prevent eavesdropping, tampering, or message forgery. The DTLS protocol is based on the stream-oriented Transport Layer Security (TLS) protocol and is intended to provide similar security guarantees. The DTLS protocol datagram preserves the semantics of the underlying transport—the application does not suffer from the delays associated with stream protocols, but because it uses User Datagram Protocol (UDP) or Stream Control Transmission Protocol (SCTP), the application has to deal with packet reordering, loss of datagram and data larger than the size of a datagram network packet. Because DTLS uses UDP or SCTP rather than TCP it avoids the TCP meltdown problem when being used to create a VPN tunnel.
A semantic web service, like conventional web services, is the server end of a client–server system for machine-to-machine interaction via the World Wide Web. Semantic services are a component of the semantic web because they use markup which makes data machine-readable in a detailed and sophisticated way.

Edge computing is a distributed computing model that brings computation and data storage closer to the sources of data. More broadly, it refers to any design that pushes computation physically closer to a user, so as to reduce the latency compared to when an application runs on a centralized data centre.
Amit Sheth is a computer scientist at University of South Carolina in Columbia, South Carolina. He is the founding Director of the Artificial Intelligence Institute, and a professor of Computer Science and Engineering. From 2007 to June 2019, he was the Lexis Nexis Ohio Eminent Scholar, director of the Ohio Center of Excellence in Knowledge-enabled Computing, and a professor of Computer Science at Wright State University. Sheth's work has been cited by over 48,800 publications. He has an h-index of 117, which puts him among the top 100 computer scientists with the highest h-index. Prior to founding the Kno.e.sis Center, he served as the director of the Large Scale Distributed Information Systems Lab at the University of Georgia in Athens, Georgia.
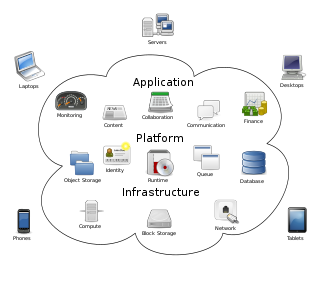
"Cloud computing is a paradigm for enabling network access to a scalable and elastic pool of shareable physical or virtual resources with self-service provisioning and administration on-demand." according to ISO.
Peer-to-peer web hosting is using peer-to-peer networking to distribute access to webpages. This is differentiated from the client–server model which involves the distribution of web data between dedicated web servers and user-end client computers. Peer-to-peer web hosting may also take the form of P2P web caches and content delivery networks.
CL-HTTP is a web server, client and proxy written in Common Lisp. It is based on its own web application framework. It was written by John C. Mallery "in about 10 days" starting in 1994 on a Symbolics Lisp Machine. In the same year a port to Macintosh Common Lisp was done. In 1996 CL-HTTP became the first web server to support the HTTP 1.1 protocol. It runs on Unix, Linux, BSD variants, Mac OS X, Solaris, Symbolics Genera and Microsoft Windows.
WebRTC is a free and open-source project providing web browsers and mobile applications with real-time communication (RTC) via application programming interfaces (APIs). It allows audio and video communication and streaming to work inside web pages by allowing direct peer-to-peer communication, eliminating the need to install plugins or download native apps.
A distributed file system for cloud is a file system that allows many clients to have access to data and supports operations on that data. Each data file may be partitioned into several parts called chunks. Each chunk may be stored on different remote machines, facilitating the parallel execution of applications. Typically, data is stored in files in a hierarchical tree, where the nodes represent directories. There are several ways to share files in a distributed architecture: each solution must be suitable for a certain type of application, depending on how complex the application is. Meanwhile, the security of the system must be ensured. Confidentiality, availability and integrity are the main keys for a secure system.
Web Tasking is a set of web user interactions in hypermedia purposefully conducted for the performance of tasks. Web tasking is a term coined intentionally to contrast web browsing.
The InterPlanetary File System (IPFS) is a protocol, hypermedia and file sharing peer-to-peer network for storing and sharing data in a distributed hash table. By using content addressing, IPFS uniquely identifies each file in a global namespace that connects IPFS hosts, creating a resilient system of file storage and sharing.
Social navigation is a form of social computing introduced by Paul Dourish and Matthew Chalmers in 1994, who defined it as when "movement from one item to another is provoked as an artifact of the activity of another or a group of others". According to later research in 2002, "social navigation exploits the knowledge and experience of peer users of information resources" to guide users in the information space, and that it is becoming more difficult to navigate and search efficiently with all the digital information available from the World Wide Web and other sources. Studying others' navigational trails and understanding their behavior can help improve one's own search strategy by guiding them to make more informed decisions based on the actions of others.
Dew computing is an information technology (IT) paradigm that combines the core concept of cloud computing with the capabilities of end devices. It is used to enhance the experience for the end user in comparison to only using cloud computing. Dew computing attempts to solve major problems related to cloud computing technology, such as reliance on internet access. Dropbox is an example of the dew computing paradigm, as it provides access to the files and folders in the cloud in addition to keeping copies on local devices. This allows the user to access files during times without an internet connection; when a connection is established again, files and folders are synchronized back to the cloud server.
Beaker is a discontinued free and open-source web browser developed by Blue Link Labs. Beaker Browser peer-to-peer technology allows users to self-publish websites and web apps directly from the browser, without the need to set up and administrate a separate web server or host their content on a third-party server. All files and websites are transferred using Dat, a hypermedia peer-to-peer protocol, which allows files to be shared and hosted by several users. The browser also supports the HTTP protocol to connect to traditional servers.
References
- ↑ Furmanski W (1997). "Petaops and Exaops: Super-computing on the Web". IEEE Internet Computing. 1 (2): 38–46. doi:10.1109/4236.601097.
- ↑ Fox G (2001). "Introduction to Web computing". Computing in Science & Engineering. 3 (2): 52–53. doi:10.1109/mcise.2001.909002.
- ↑ Wilkinson SR, Almeida JS (2014). "QMachine: commodity supercomputing in web browsers". BMC Bioinformatics. 15: 176. doi: 10.1186/1471-2105-15-176 . PMC 4063228 . PMID 24913605.
- ↑ Verborgh R (2014). "Serendipitous web applications through semantic hypermedia" (PDF). Sort. 100.
- ↑ "WebRTC". WebRTC.org.