CDR coding is in fact a fairly general idea; whenever a data object A ends in a reference to another data structure B, we can instead place the structure B itself there, overlapping and running off the end of A. By doing this we free the space required by the reference, which can add up if done many times, and also improve locality of reference, enhancing performance on modern machines. The transformation is especially effective for the cons-based lists it was created for; we free about half of the space for each node we perform this transformation on.
It is not always possible to perform this substitution, because there might not be a large enough chunk of free space beyond the end of A. Thus, some objects will end in a real reference, and some with the referenced object, and the machine must be able to tell by reading the final cell which one it is. This can be accomplished with some inefficiency in software by the use of tagged pointers, which allow a pointer in a final position to be specifically tagged as such, but is best done in hardware.
In the presence of mutable objects, CDR coding becomes more complex. If a reference is updated to point to another object, but currently has an object stored in that field, the object must be relocated, along with any other pointers to it. Not only are such moves typically expensive or impossible, but over time they cause fragmentation of the store. This problem is typically avoided by using CDR coding only on immutable data structures.
External links
Mark Kantrowitz; Barry Margolin (eds.). "(2-9) What is CDR-coding?". FAQ: Lisp Frequently Asked Questions. Advameg, Inc. Retrieved 2011-10-09.
L. Peter Deutsch: A LISP Machine with Very Compact Programs. IJCAI 1973, Pages 697 - 703
Greenblatt, R., LISP Machine Progress Report, memo 444, A.I.Lab., M.I.T., Cambridge, Mass., Aug. 1977.
L. Peter Deutsch: Experience with a microprogrammed Interlisp system. MICRO 11: Proceedings of the 11th annual workshop on Microprogramming, November 1978, Pages 128–129
Allen, John (1978). The Anatomy of Lisp. McGraw-Hill. Pages 399-401
Common Lisp (CL) is a dialect of the Lisp programming language, published in American National Standards Institute (ANSI) standard document ANSI INCITS 226-1994 (S2018). The Common Lisp HyperSpec, a hyperlinked HTML version, has been derived from the ANSI Common Lisp standard.
In computer science, garbage collection (GC) is a form of automatic memory management. The garbage collector attempts to reclaim memory that was allocated by the program, but is no longer referenced; such memory is called garbage. Garbage collection was invented by American computer scientist John McCarthy around 1959 to simplify manual memory management in Lisp.
Lisp is a family of programming languages with a long history and a distinctive, fully parenthesized prefix notation. Originally specified in the late 1950s, it is the second-oldest high-level programming language still in common use, after Fortran. Lisp has changed since its early days, and many dialects have existed over its history. Today, the best-known general-purpose Lisp dialects are Common Lisp, Scheme, Racket, and Clojure.
Lisp machines are general-purpose computers designed to efficiently run Lisp as their main software and programming language, usually via hardware support. They are an example of a high-level language computer architecture. In a sense, they were the first commercial single-user workstations. Despite being modest in number Lisp machines commercially pioneered many now-commonplace technologies, including effective garbage collection, laser printing, windowing systems, computer mice, high-resolution bit-mapped raster graphics, computer graphic rendering, and networking innovations such as Chaosnet. Several firms built and sold Lisp machines in the 1980s: Symbolics, Lisp Machines Incorporated, Texas Instruments, and Xerox. The operating systems were written in Lisp Machine Lisp, Interlisp (Xerox), and later partly in Common Lisp.
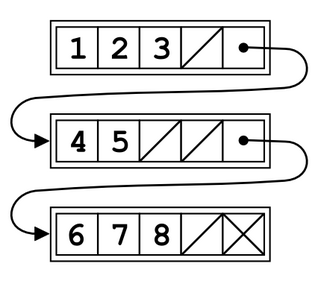
In computer science, a linked list is a linear collection of data elements whose order is not given by their physical placement in memory. Instead, each element points to the next. It is a data structure consisting of a collection of nodes which together represent a sequence. In its most basic form, each node contains data, and a reference to the next node in the sequence. This structure allows for efficient insertion or removal of elements from any position in the sequence during iteration. More complex variants add additional links, allowing more efficient insertion or removal of nodes at arbitrary positions. A drawback of linked lists is that data access time is linear in respect to the number of nodes in the list. Because nodes are serially linked, accessing any node requires that the prior node be accessed beforehand. Faster access, such as random access, is not feasible. Arrays have better cache locality compared to linked lists.
Symbolics, Inc., was a privately held American computer manufacturer that acquired the assets of the former company and continues to sell and maintain the Open Genera Lisp system and the Macsyma computer algebra system.
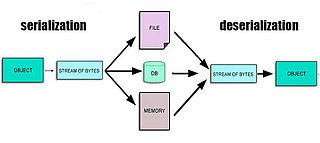
In computing, serialization is the process of translating a data structure or object state into a format that can be stored or transmitted and reconstructed later. When the resulting series of bits is reread according to the serialization format, it can be used to create a semantically identical clone of the original object. For many complex objects, such as those that make extensive use of references, this process is not straightforward. Serialization of objects does not include any of their associated methods with which they were previously linked.
The SECD machine is a highly influential virtual machine and abstract machine intended as a target for functional programming language compilers. The letters stand for Stack, Environment, Control, Dump—the internal registers of the machine. The registers Stack, Control, and Dump point to stacks, and Environment points to an associative array.
Maclisp is a programming language, a dialect of the language Lisp. It originated at the Massachusetts Institute of Technology's (MIT) Project MAC in the late 1960s and was based on Lisp 1.5. Richard Greenblatt was the main developer of the original codebase for the PDP-6; Jon L. White was responsible for its later maintenance and development. The name Maclisp began being used in the early 1970s to distinguish it from other forks of PDP-6 Lisp, notably BBN Lisp.
In computer programming, an S-expression is an expression in a like-named notation for nested list (tree-structured) data. S-expressions were invented for and popularized by the programming language Lisp, which uses them for source code as well as data.
In computer science, an interpreter is a computer program that directly executes instructions written in a programming or scripting language, without requiring them previously to have been compiled into a machine language program. An interpreter generally uses one of the following strategies for program execution:
Parse the source code and perform its behavior directly;
Translate source code into some efficient intermediate representation or object code and immediately execute that;
Explicitly execute stored precompiled bytecode made by a compiler and matched with the interpreter's virtual machine.
In computer science, an abstract machine is a theoretical model that allows for a detailed and precise analysis of how a computer system functions. It is similar to a mathematical function in that it receives inputs and produces outputs based on predefined rules. Abstract machines vary from literal machines in that they are expected to perform correctly and independently of hardware. Abstract machines are "machines" because they allow step-by-step execution of programmes; they are "abstract" because they ignore many aspects of actual (hardware) machines. A typical abstract machine consists of a definition in terms of input, output, and the set of allowable operations used to turn the former into the latter. They can be used for purely theoretical reasons as well as models for real-world computer systems. In the theory of computation, abstract machines are often used in thought experiments regarding computability or to analyse the complexity of algorithms. This use of abstract machines is fundamental to the field of computational complexity theory, such as finite state machines, Mealy machines, push-down automata, and Turing machines.
In programming languages, a closure, also lexical closure or function closure, is a technique for implementing lexically scoped name binding in a language with first-class functions. Operationally, a closure is a record storing a function together with an environment. The environment is a mapping associating each free variable of the function with the value or reference to which the name was bound when the closure was created. Unlike a plain function, a closure allows the function to access those captured variables through the closure's copies of their values or references, even when the function is invoked outside their scope.
In computer programming, CAR (car) and CDR (cdr) are primitive operations on cons cells introduced in the Lisp programming language. A cons cell is composed of two pointers; the car operation extracts the first pointer, and the cdr operation extracts the second.
In computer science, a list or sequence is collection of items that are finite in number and in a particular order. An instance of a list is a computer representation of the mathematical concept of a tuple or finite sequence.
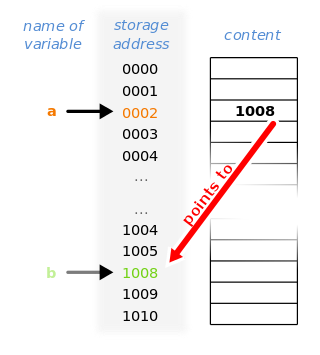
In computer programming, a reference is a value that enables a program to indirectly access a particular datum, such as a variable's value or a record, in the computer's memory or in some other storage device. The reference is said to refer to the datum, and accessing the datum is called dereferencing the reference. A reference is distinct from the datum itself.
In computer science, a pointer is an object in many programming languages that stores a memory address. This can be that of another value located in computer memory, or in some cases, that of memory-mapped computer hardware. A pointer references a location in memory, and obtaining the value stored at that location is known as dereferencing the pointer. As an analogy, a page number in a book's index could be considered a pointer to the corresponding page; dereferencing such a pointer would be done by flipping to the page with the given page number and reading the text found on that page. The actual format and content of a pointer variable is dependent on the underlying computer architecture.
In computer programming, an unrolled linked list is a variation on the linked list which stores multiple elements in each node. It can dramatically increase cache performance, while decreasing the memory overhead associated with storing list metadata such as references. It is related to the B-tree.
In computing, a null pointer or null reference is a value saved for indicating that the pointer or reference does not refer to a valid object. Programs routinely use null pointers to represent conditions such as the end of a list of unknown length or the failure to perform some action; this use of null pointers can be compared to nullable types and to the Nothing value in an option type.
In computer science, a tagged pointer is a pointer with additional data associated with it, such as an indirection bit or reference count. This additional data is often "folded" into the pointer, meaning stored inline in the data representing the address, taking advantage of certain properties of memory addressing. The name comes from "tagged architecture" systems, which reserved bits at the hardware level to indicate the significance of each word; the additional data is called a "tag" or "tags", though strictly speaking "tag" refers to data specifying a type, not other data; however, the usage "tagged pointer" is ubiquitous.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.