"Source coding" redirects here. For the term in computer programming, see Source code.
"Decompression software" redirects here. For the code for calculation of diving decompression schedules, see Decompression algorithm.
In information theory, data compression, source coding,[1] or bit-rate reduction is the process of encoding information using fewer bits than the original representation.[2] Any particular compression is either lossy or lossless. Lossless compression reduces bits by identifying and eliminating statistical redundancy. No information is lost in lossless compression. Lossy compression reduces bits by removing unnecessary or less important information.[3] Typically, a device that performs data compression is referred to as an encoder, and one that performs the reversal of the process (decompression) as a decoder.
The process of reducing the size of a data file is often referred to as data compression. In the context of data transmission, it is called source coding: encoding is done at the source of the data before it is stored or transmitted.[4] Source coding should not be confused with channel coding, for error detection and correction or line coding, the means for mapping data onto a signal.
Data compression algorithms present a space–time complexity trade-off between the bytes needed to store or transmit information, and the computational resources needed to perform the encoding and decoding. The design of data compression schemes involves balancing the degree of compression, the amount of distortion introduced (when using lossy data compression), and the computational resources or time required to compress and decompress the data.[5]
Lossless data compression algorithms usually exploit statistical redundancy to represent data without losing any information, so that the process is reversible. Lossless compression is possible because most real-world data exhibits statistical redundancy. For example, an image may have areas of color that do not change over several pixels; instead of coding "red pixel, red pixel, ..." the data may be encoded as "279 red pixels". This is a basic example of run-length encoding; there are many schemes to reduce file size by eliminating redundancy.
The Lempel–Ziv (LZ) compression methods are among the most popular algorithms for lossless storage.[6]DEFLATE is a variation on LZ optimized for decompression speed and compression ratio,[7] but compression can be slow. In the mid-1980s, following work by Terry Welch, the Lempel–Ziv–Welch (LZW) algorithm rapidly became the method of choice for most general-purpose compression systems. LZW is used in GIF images, programs such as PKZIP, and hardware devices such as modems.[8] LZ methods use a table-based compression model where table entries are substituted for repeated strings of data. For most LZ methods, this table is generated dynamically from earlier data in the input. The table itself is often Huffman encoded. Grammar-based codes like this can compress highly repetitive input extremely effectively, for instance, a biological data collection of the same or closely related species, a huge versioned document collection, internet archival, etc. The basic task of grammar-based codes is constructing a context-free grammar deriving a single string. Other practical grammar compression algorithms include Sequitur and Re-Pair.
The strongest modern lossless compressors use probabilistic models, such as prediction by partial matching. The Burrows–Wheeler transform can also be viewed as an indirect form of statistical modelling.[citation needed] In a further refinement of the direct use of probabilistic modelling, statistical estimates can be coupled to an algorithm called arithmetic coding. Arithmetic coding is a more modern coding technique that uses the mathematical calculations of a finite-state machine to produce a string of encoded bits from a series of input data symbols. It can achieve superior compression compared to other techniques such as the better-known Huffman algorithm. It uses an internal memory state to avoid the need to perform a one-to-one mapping of individual input symbols to distinct representations that use an integer number of bits, and it clears out the internal memory only after encoding the entire string of data symbols. Arithmetic coding applies especially well to adaptive data compression tasks where the statistics vary and are context-dependent, as it can be easily coupled with an adaptive model of the probability distribution of the input data. An early example of the use of arithmetic coding was in an optional (but not widely used) feature of the JPEG image coding standard.[9] It has since been applied in various other designs including H.263, H.264/MPEG-4 AVC and HEVC for video coding.[10]
Archive software typically has the ability to adjust the "dictionary size", where a larger size demands more random-access memory during compression and decompression, but compresses stronger, especially on repeating patterns in files' content.[11][12]
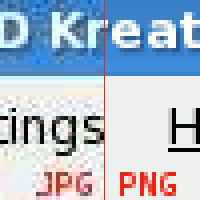
Composite image showing JPG and PNG image compression. Left side of the image is from a JPEG image, showing lossy artifacts; the right side is from a PNG image.
In the late 1980s, digital images became more common, and standards for lossless image compression emerged. In the early 1990s, lossy compression methods began to be widely used.[13] In these schemes, some loss of information is accepted as dropping nonessential detail can save storage space. There is a corresponding trade-off between preserving information and reducing size. Lossy data compression schemes are designed by research on how people perceive the data in question. For example, the human eye is more sensitive to subtle variations in luminance than it is to the variations in color. JPEG image compression works in part by rounding off nonessential bits of information.[14] A number of popular compression formats exploit these perceptual differences, including psychoacoustics for sound, and psychovisuals for images and video.
Most forms of lossy compression are based on transform coding, especially the discrete cosine transform (DCT). It was first proposed in 1972 by Nasir Ahmed, who then developed a working algorithm with T. Natarajan and K. R. Rao in 1973, before introducing it in January 1974.[15][16] DCT is the most widely used lossy compression method, and is used in multimedia formats for images (such as JPEG and HEIF),[17]video (such as MPEG, AVC and HEVC) and audio (such as MP3, AAC and Vorbis).
In lossy audio compression, methods of psychoacoustics are used to remove non-audible (or less audible) components of the audio signal. Compression of human speech is often performed with even more specialized techniques; speech coding is distinguished as a separate discipline from general-purpose audio compression. Speech coding is used in internet telephony, for example, audio compression is used for CD ripping and is decoded by the audio players.[citation needed]
There is a close connection between machine learning and compression. A system that predicts the posterior probabilities of a sequence given its entire history can be used for optimal data compression (by using arithmetic coding on the output distribution). Conversely, an optimal compressor can be used for prediction (by finding the symbol that compresses best, given the previous history). This equivalence has been used as a justification for using data compression as a benchmark for "general intelligence".[19][20][21]
An alternative view can show compression algorithms implicitly map strings into implicit feature space vectors, and compression-based similarity measures compute similarity within these feature spaces. For each compressor C(.) we define an associated vector space ℵ, such that C(.) maps an input string x, corresponding to the vector norm ||~x||. An exhaustive examination of the feature spaces underlying all compression algorithms is precluded by space; instead, feature vectors chooses to examine three representative lossless compression methods, LZW, LZ77, and PPM.[22]
According to AIXI theory, a connection more directly explained in Hutter Prize, the best possible compression of x is the smallest possible software that generates x. For example, in that model, a zip file's compressed size includes both the zip file and the unzipping software, since you can not unzip it without both, but there may be an even smaller combined form.
Examples of AI-powered audio/video compression software include NVIDIA Maxine, AIVC.[23] Examples of software that can perform AI-powered image compression include OpenCV, TensorFlow, MATLAB's Image Processing Toolbox (IPT) and High-Fidelity Generative Image Compression.[24]
In unsupervised machine learning, k-means clustering can be utilized to compress data by grouping similar data points into clusters. This technique simplifies handling extensive datasets that lack predefined labels and finds widespread use in fields such as image compression.[25]
Data compression aims to reduce the size of data files, enhancing storage efficiency and speeding up data transmission. K-means clustering, an unsupervised machine learning algorithm, is employed to partition a dataset into a specified number of clusters, k, each represented by the centroid of its points. This process condenses extensive datasets into a more compact set of representative points. Particularly beneficial in image and signal processing, k-means clustering aids in data reduction by replacing groups of data points with their centroids, thereby preserving the core information of the original data while significantly decreasing the required storage space.[26]
Large language models (LLMs) are also efficient lossless data compressors on some data sets, as demonstrated by DeepMind's research with the Chinchilla 70B model. Developed by DeepMind, Chinchilla 70B effectively compressed data, outperforming conventional methods such as Portable Network Graphics (PNG) for images and Free Lossless Audio Codec (FLAC) for audio. It achieved compression of image and audio data to 43.4% and 16.4% of their original sizes, respectively. There is, however, some reason to be concerned that the data set used for testing overlaps the LLM training data set, making it possible that the Chinchilla 70B model is only an efficient compression tool on data it has already been trained on.[27][28]
Data compression can be viewed as a special case of data differencing.[29][30] Data differencing consists of producing a difference given a source and a target, with patching reproducing the target given a source and a difference. Since there is no separate source and target in data compression, one can consider data compression as data differencing with empty source data, the compressed file corresponding to a difference from nothing. This is the same as considering absolute entropy (corresponding to data compression) as a special case of relative entropy (corresponding to data differencing) with no initial data.
The term differential compression is used to emphasize the data differencing connection.
An important image compression technique is the discrete cosine transform (DCT), a technique developed in the early 1970s.[15] DCT is the basis for JPEG, a lossy compression format which was introduced by the Joint Photographic Experts Group (JPEG) in 1992.[34] JPEG greatly reduces the amount of data required to represent an image at the cost of a relatively small reduction in image quality and has become the most widely used image file format.[35][36] Its highly efficient DCT-based compression algorithm was largely responsible for the wide proliferation of digital images and digital photos.[37]
Lossy audio compression algorithms provide higher compression and are used in numerous audio applications including Vorbis and MP3. These algorithms almost all rely on psychoacoustics to eliminate or reduce fidelity of less audible sounds, thereby reducing the space required to store or transmit them.[2][46]
The acceptable trade-off between loss of audio quality and transmission or storage size depends upon the application. For example, one 640 MB compact disc (CD) holds approximately one hour of uncompressed high fidelity music, less than 2 hours of music compressed losslessly, or 7 hours of music compressed in the MP3 format at a medium bit rate. A digital sound recorder can typically store around 200 hours of clearly intelligible speech in 640 MB.[47]
Lossless audio compression produces a representation of digital data that can be decoded to an exact digital duplicate of the original. Compression ratios are around 50–60% of the original size,[48] which is similar to those for generic lossless data compression. Lossless codecs use curve fitting or linear prediction as a basis for estimating the signal. Parameters describing the estimation and the difference between the estimation and the actual signal are coded separately.[49]
Some audio file formats feature a combination of a lossy format and a lossless correction; this allows stripping the correction to easily obtain a lossy file. Such formats include MPEG-4 SLS (Scalable to Lossless), WavPack, and OptimFROG DualStream.
When audio files are to be processed, either by further compression or for editing, it is desirable to work from an unchanged original (uncompressed or losslessly compressed). Processing of a lossily compressed file for some purpose usually produces a final result inferior to the creation of the same compressed file from an uncompressed original. In addition to sound editing or mixing, lossless audio compression is often used for archival storage, or as master copies.
Lossy audio compression
Comparison of spectrograms of audio in an uncompressed format and several lossy formats. The lossy spectrograms show bandlimiting of higher frequencies, a common technique associated with lossy audio compression.
Lossy audio compression is used in a wide range of applications. In addition to standalone audio-only applications of file playback in MP3 players or computers, digitally compressed audio streams are used in most video DVDs, digital television, streaming media on the Internet, satellite and cable radio, and increasingly in terrestrial radio broadcasts. Lossy compression typically achieves far greater compression than lossless compression, by discarding less-critical data based on psychoacoustic optimizations.[50]
Psychoacoustics recognizes that not all data in an audio stream can be perceived by the human auditory system. Most lossy compression reduces redundancy by first identifying perceptually irrelevant sounds, that is, sounds that are very hard to hear. Typical examples include high frequencies or sounds that occur at the same time as louder sounds. Those irrelevant sounds are coded with decreased accuracy or not at all.
Due to the nature of lossy algorithms, audio quality suffers a digital generation loss when a file is decompressed and recompressed. This makes lossy compression unsuitable for storing the intermediate results in professional audio engineering applications, such as sound editing and multitrack recording. However, lossy formats such as MP3 are very popular with end-users as the file size is reduced to 5-20% of the original size and a megabyte can store about a minute's worth of music at adequate quality.
Several proprietary lossy compression algorithms have been developed that provide higher quality audio performance by using a combination of lossless and lossy algorithms with adaptive bit rates and lower compression ratios. Examples include aptX, LDAC, LHDC, MQA and SCL6.
Coding methods
To determine what information in an audio signal is perceptually irrelevant, most lossy compression algorithms use transforms such as the modified discrete cosine transform (MDCT) to convert time domain sampled waveforms into a transform domain, typically the frequency domain. Once transformed, component frequencies can be prioritized according to how audible they are. Audibility of spectral components is assessed using the absolute threshold of hearing and the principles of simultaneous masking—the phenomenon wherein a signal is masked by another signal separated by frequency—and, in some cases, temporal masking—where a signal is masked by another signal separated by time. Equal-loudness contours may also be used to weigh the perceptual importance of components. Models of the human ear-brain combination incorporating such effects are often called psychoacoustic models.[51]
Other types of lossy compressors, such as the linear predictive coding (LPC) used with speech, are source-based coders. LPC uses a model of the human vocal tract to analyze speech sounds and infer the parameters used by the model to produce them moment to moment. These changing parameters are transmitted or stored and used to drive another model in the decoder which reproduces the sound.
Lossy formats are often used for the distribution of streaming audio or interactive communication (such as in cell phone networks). In such applications, the data must be decompressed as the data flows, rather than after the entire data stream has been transmitted. Not all audio codecs can be used for streaming applications.[50]
Latency is introduced by the methods used to encode and decode the data. Some codecs will analyze a longer segment, called a frame, of the data to optimize efficiency, and then code it in a manner that requires a larger segment of data at one time to decode. The inherent latency of the coding algorithm can be critical; for example, when there is a two-way transmission of data, such as with a telephone conversation, significant delays may seriously degrade the perceived quality.
In contrast to the speed of compression, which is proportional to the number of operations required by the algorithm, here latency refers to the number of samples that must be analyzed before a block of audio is processed. In the minimum case, latency is zero samples (e.g., if the coder/decoder simply reduces the number of bits used to quantize the signal). Time domain algorithms such as LPC also often have low latencies, hence their popularity in speech coding for telephony. In algorithms such as MP3, however, a large number of samples have to be analyzed to implement a psychoacoustic model in the frequency domain, and latency is on the order of 23ms.
Speech encoding
Speech encoding is an important category of audio data compression. The perceptual models used to estimate what aspects of speech a human ear can hear are generally somewhat different from those used for music. The range of frequencies needed to convey the sounds of a human voice is normally far narrower than that needed for music, and the sound is normally less complex. As a result, speech can be encoded at high quality using a relatively low bit rate.
This is accomplished, in general, by some combination of two approaches:
Only encoding sounds that could be made by a single human voice.
Throwing away more of the data in the signal—keeping just enough to reconstruct an "intelligible" voice rather than the full frequency range of human hearing.
The earliest algorithms used in speech encoding (and audio data compression in general) were the A-law algorithm and the μ-law algorithm.
History
Solidyne 922: The world's first commercial audio bit compression sound card for PC, 1990
A literature compendium for a large variety of audio coding systems was published in the IEEE's Journal on Selected Areas in Communications (JSAC), in February 1988. While there were some papers from before that time, this collection documented an entire variety of finished, working audio coders, nearly all of them using perceptual techniques and some kind of frequency analysis and back-end noiseless coding.[66]
The two key video compression techniques used in video coding standards are the DCT and motion compensation (MC). Most video coding standards, such as the H.26x and MPEG formats, typically use motion-compensated DCT video coding (block motion compensation).[68][69]
Most video codecs are used alongside audio compression techniques to store the separate but complementary data streams as one combined package using so-called container formats.[70]
Encoding theory
Video data may be represented as a series of still image frames. Such data usually contains abundant amounts of spatial and temporal redundancy. Video compression algorithms attempt to reduce redundancy and store information more compactly.
Most video compression formats and codecs exploit both spatial and temporal redundancy (e.g. through difference coding with motion compensation). Similarities can be encoded by only storing differences between e.g. temporally adjacent frames (inter-frame coding) or spatially adjacent pixels (intra-frame coding). Inter-frame compression (a temporal delta encoding) (re)uses data from one or more earlier or later frames in a sequence to describe the current frame. Intra-frame coding, on the other hand, uses only data from within the current frame, effectively being still-image compression.[51]
The intra-frame video coding formats used in camcorders and video editing employ simpler compression that uses only intra-frame prediction. This simplifies video editing software, as it prevents a situation in which a compressed frame refers to data that the editor has deleted.
Usually, video compression additionally employs lossy compression techniques like quantization that reduce aspects of the source data that are (more or less) irrelevant to the human visual perception by exploiting perceptual features of human vision. For example, small differences in color are more difficult to perceive than are changes in brightness. Compression algorithms can average a color across these similar areas in a manner similar to those used in JPEG image compression.[9] As in all lossy compression, there is a trade-off between video quality and bit rate, cost of processing the compression and decompression, and system requirements. Highly compressed video may present visible or distracting artifacts.
Other methods other than the prevalent DCT-based transform formats, such as fractal compression, matching pursuit and the use of a discrete wavelet transform (DWT), have been the subject of some research, but are typically not used in practical products. Wavelet compression is used in still-image coders and video coders without motion compensation. Interest in fractal compression seems to be waning, due to recent theoretical analysis showing a comparative lack of effectiveness of such methods.[51]
In inter-frame coding, individual frames of a video sequence are compared from one frame to the next, and the video compression codec records the differences to the reference frame. If the frame contains areas where nothing has moved, the system can simply issue a short command that copies that part of the previous frame into the next one. If sections of the frame move in a simple manner, the compressor can emit a (slightly longer) command that tells the decompressor to shift, rotate, lighten, or darken the copy. This longer command still remains much shorter than data generated by intra-frame compression. Usually, the encoder will also transmit a residue signal which describes the remaining more subtle differences to the reference imagery. Using entropy coding, these residue signals have a more compact representation than the full signal. In areas of video with more motion, the compression must encode more data to keep up with the larger number of pixels that are changing. Commonly, the high-frequency detail of explosions, flames, flocks of animals, and some panning shots, will lead to decreases in quality or increases in the variable bitrate.
Hybrid block-based transform formats
Processing stages of a typical video encoder
Many commonly used video compression methods (e.g., those in standards approved by the ITU-T or ISO) share the same basic architecture that dates back to H.261 which was standardized in 1988 by the ITU-T. They mostly rely on the DCT, applied to rectangular blocks of neighboring pixels, and temporal prediction using motion vectors, as well as nowadays also an in-loop filtering step.
In the prediction stage, various deduplication and difference-coding techniques are applied that help decorrelate data and describe new data based on already transmitted data.
Then rectangular blocks of remaining pixel data are transformed to the frequency domain. In the main lossy processing stage, frequency domain data gets quantized in order to reduce information that is irrelevant to human visual perception.
In the last stage statistical redundancy gets largely eliminated by an entropy coder which often applies some form of arithmetic coding.
In an additional in-loop filtering stage various filters can be applied to the reconstructed image signal. By computing these filters also inside the encoding loop they can help compression because they can be applied to reference material before it gets used in the prediction process and they can be guided using the original signal. The most popular example are deblocking filters that blur out blocking artifacts from quantization discontinuities at transform block boundaries.
In 1967, A.H. Robinson and C. Cherry proposed a run-length encoding bandwidth compression scheme for the transmission of analog television signals.[71] The DCT, which is fundamental to modern video compression,[72] was introduced by Nasir Ahmed, T. Natarajan and K. R. Rao in 1974.[16][73]
H.261, which debuted in 1988, commercially introduced the prevalent basic architecture of video compression technology.[74] It was the first video coding format based on DCT compression.[72] H.261 was developed by a number of companies, including Hitachi, PictureTel, NTT, BT and Toshiba.[75]
Genetics compression algorithms are the latest generation of lossless algorithms that compress data (typically sequences of nucleotides) using both conventional compression algorithms and genetic algorithms adapted to the specific datatype. In 2012, a team of scientists from Johns Hopkins University published a genetic compression algorithm that does not use a reference genome for compression. HAPZIPPER was tailored for HapMap data and achieves over 20-fold compression (95% reduction in file size), providing 2- to 4-fold better compression and is less computationally intensive than the leading general-purpose compression utilities. For this, Chanda, Elhaik, and Bader introduced MAF-based encoding (MAFE), which reduces the heterogeneity of the dataset by sorting SNPs by their minor allele frequency, thus homogenizing the dataset.[79] Other algorithms developed in 2009 and 2013 (DNAZip and GenomeZip) have compression ratios of up to 1200-fold—allowing 6 billion basepair diploid human genomes to be stored in 2.5 megabytes (relative to a reference genome or averaged over many genomes).[80][81] For a benchmark in genetics/genomics data compressors, see [82]
Outlook and currently unused potential
It is estimated that the total amount of data that is stored on the world's storage devices could be further compressed with existing compression algorithms by a remaining average factor of 4.5:1.[83] It is estimated that the combined technological capacity of the world to store information provides 1,300 exabytes of hardware digits in 2007, but when the corresponding content is optimally compressed, this only represents 295 exabytes of Shannon information.[84]
↑Wade, Graham (1994). Signal coding and processing (2ed.). Cambridge University Press. p.34. ISBN978-0-521-42336-6. Retrieved 2011-12-22. The broad objective of source coding is to exploit or remove 'inefficient' redundancy in the PCM source and thereby achieve a reduction in the overall source rate R.
↑Salomon, David (2008). A Concise Introduction to Data Compression. Berlin: Springer. ISBN9781848000728.
↑Tank, M.K. (2011). "Implementation of Lempel-ZIV algorithm for lossless compression using VHDL". Thinkquest 2010: Proceedings of the First International Conference on Contours of Computing Technology. Berlin: Springer. pp.275–283. doi:10.1007/978-81-8489-989-4_51. ISBN978-81-8489-988-7.
↑Korn, D.G.; Vo, K.P. (1995). B. Krishnamurthy (ed.). Vdelta: Differencing and Compression. Practical Reusable Unix Software. New York: John Wiley & Sons, Inc.
↑Hoffman, Roy (2012). Data Compression in Digital Systems. Springer Science & Business Media. p.124. ISBN9781461560319. Basically, wavelet coding is a variant on DCT-based transform coding that reduces or eliminates some of its limitations. (...) Another advantage is that rather than working with 8 × 8 blocks of pixels, as do JPEG and other block-based DCT techniques, wavelet coding can simultaneously compress the entire image.
↑The Olympus WS-120 digital speech recorder, according to its manual, can store about 178 hours of speech-quality audio in .WMA format in 500 MB of flash memory.
123Schroeder, Manfred R. (2014). "Bell Laboratories". Acoustics, Information, and Communication: Memorial Volume in Honor of Manfred R. Schroeder. Springer. p.388. ISBN9783319056609.
↑Britanak, V. (2011). "On Properties, Relations, and Simplified Implementation of Filter Banks in the Dolby Digital (Plus) AC-3 Audio Coding Standards". IEEE Transactions on Audio, Speech, and Language Processing. 19 (5): 1231–1241. Bibcode:2011ITASL..19.1231B. doi:10.1109/TASL.2010.2087755. S2CID897622.
↑Princen, J.; Johnson, A.; Bradley, A. (1987). "Subband/Transform coding using filter bank designs based on time domain aliasing cancellation". ICASSP '87. IEEE International Conference on Acoustics, Speech, and Signal Processing. Vol.12. pp.2161–2164. doi:10.1109/ICASSP.1987.1169405. S2CID58446992.
↑Princen, J.; Bradley, A. (1986). "Analysis/Synthesis filter bank design based on time domain aliasing cancellation". IEEE Transactions on Acoustics, Speech, and Signal Processing. 34 (5): 1153–1161. Bibcode:1986ITASS..34.1153P. doi:10.1109/TASSP.1986.1164954.
↑Vatolin, Dmitriy; etal. (Graphics & Media Lab Video Group) (March 2007). Lossless Video Codecs Comparison '2007(PDF) (Report). Moscow State University. Archived(PDF) from the original on 2008-05-15.
↑"Video Coding". CSIP website. Center for Signal and Information Processing, Georgia Institute of Technology. Archived from the original on 23 May 2013. Retrieved 6 March 2013.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.