In information theory, data compression, source coding, or bit-rate reduction is the process of encoding information using fewer bits than the original representation. Any particular compression is either lossy or lossless. Lossless compression reduces bits by identifying and eliminating statistical redundancy. No information is lost in lossless compression. Lossy compression reduces bits by removing unnecessary or less important information. Typically, a device that performs data compression is referred to as an encoder, and one that performs the reversal of the process (decompression) as a decoder.
MPEG-1 is a standard for lossy compression of video and audio. It is designed to compress VHS-quality raw digital video and CD audio down to about 1.5 Mbit/s without excessive quality loss, making video CDs, digital cable/satellite TV and digital audio broadcasting (DAB) practical.

Motion compensation in computing is an algorithmic technique used to predict a frame in a video given the previous and/or future frames by accounting for motion of the camera and/or objects in the video. It is employed in the encoding of video data for video compression, for example in the generation of MPEG-2 files. Motion compensation describes a picture in terms of the transformation of a reference picture to the current picture. The reference picture may be previous in time or even from the future. When images can be accurately synthesized from previously transmitted/stored images, the compression efficiency can be improved.

A compression artifact is a noticeable distortion of media caused by the application of lossy compression. Lossy data compression involves discarding some of the media's data so that it becomes small enough to be stored within the desired disk space or transmitted (streamed) within the available bandwidth. If the compressor cannot store enough data in the compressed version, the result is a loss of quality, or introduction of artifacts. The compression algorithm may not be intelligent enough to discriminate between distortions of little subjective importance and those objectionable to the user.
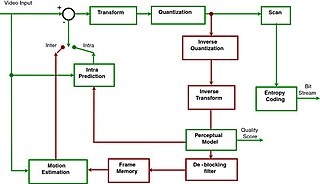
Advanced Video Coding (AVC), also referred to as H.264 or MPEG-4 Part 10, is a video compression standard based on block-oriented, motion-compensated coding. It is by far the most commonly used format for the recording, compression, and distribution of video content, used by 91% of video industry developers as of September 2019. It supports a maximum resolution of 8K UHD.
H.261 is an ITU-T video compression standard, first ratified in November 1988. It is the first member of the H.26x family of video coding standards in the domain of the ITU-T Study Group 16 Video Coding Experts Group. It was the first video coding standard that was useful in practical terms.
In the field of video compression a video frame is compressed using different algorithms with different advantages and disadvantages, centered mainly around amount of data compression. These different algorithms for video frames are called picture types or frame types. The three major picture types used in the different video algorithms are I, P and B. They are different in the following characteristics:
An inter frame is a frame in a video compression stream which is expressed in terms of one or more neighboring frames. The "inter" part of the term refers to the use of Inter frame prediction. This kind of prediction tries to take advantage from temporal redundancy between neighboring frames enabling higher compression rates.
H.262 or MPEG-2 Part 2 is a video coding format standardised and jointly maintained by ITU-T Study Group 16 Video Coding Experts Group (VCEG) and ISO/IEC Moving Picture Experts Group (MPEG), and developed with the involvement of many companies. It is the second part of the ISO/IEC MPEG-2 standard. The ITU-T Recommendation H.262 and ISO/IEC 13818-2 documents are identical.
Global motion compensation(GMC) is a motion compensation technique used in video compression to reduce the bitrate required to encode video. It is most commonly used in MPEG-4 ASP, such as with the DivX and Xvid codecs.

Image stitching or photo stitching is the process of combining multiple photographic images with overlapping fields of view to produce a segmented panorama or high-resolution image. Commonly performed through the use of computer software, most approaches to image stitching require nearly exact overlaps between images and identical exposures to produce seamless results, although some stitching algorithms actually benefit from differently exposed images by doing high-dynamic-range imaging in regions of overlap. Some digital cameras can stitch their photos internally.
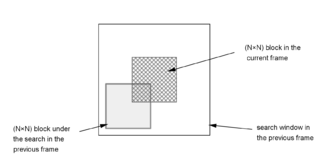
A Block Matching Algorithm is a way of locating matching macroblocks in a sequence of digital video frames for the purposes of motion estimation. The underlying supposition behind motion estimation is that the patterns corresponding to objects and background in a frame of video sequence move within the frame to form corresponding objects on the subsequent frame. This can be used to discover temporal redundancy in the video sequence, increasing the effectiveness of inter-frame video compression by defining the contents of a macroblock by reference to the contents of a known macroblock which is minimally different.
The macroblock is a processing unit in image and video compression formats based on linear block transforms, typically the discrete cosine transform (DCT). A macroblock typically consists of 16×16 samples, and is further subdivided into transform blocks, and may be further subdivided into prediction blocks. Formats which are based on macroblocks include JPEG, where they are called MCU blocks, H.261, MPEG-1 Part 2, H.262/MPEG-2 Part 2, H.263, MPEG-4 Part 2, and H.264/MPEG-4 AVC. In H.265/HEVC, the macroblock as a basic processing unit has been replaced by the coding tree unit.
Television standards conversion is the process of changing a television transmission or recording from one video system to another. Converting video between different numbers of lines, frame rates, and color models in video pictures is a complex technical problem. However, the international exchange of television programming makes standards conversion necessary so that video may be viewed in another nation with a differing standard. Typically video is fed into video standards converter which produces a copy according to a different video standard. One of the most common conversions is between the NTSC and PAL standards.
Rate-distortion optimization (RDO) is a method of improving video quality in video compression. The name refers to the optimization of the amount of distortion against the amount of data required to encode the video, the rate. While it is primarily used by video encoders, rate-distortion optimization can be used to improve quality in any encoding situation where decisions have to be made that affect both file size and quality simultaneously.
Anil K. Jain was an Indian-American electrical engineer and Professor of the Department of Electrical Engineering and Computer Science at the University of California, Davis, known for his contributions on "two-dimensional stochastic models for images provided a firm theoretical foundation for a number of algorithms of spectral analysis, adaptive image estimation and image data compression", including work on transform coding for image compression and block-based motion compensation for video compression in particular.
A video coding format is a content representation format of digital video content, such as in a data file or bitstream. It typically uses a standardized video compression algorithm, most commonly based on discrete cosine transform (DCT) coding and motion compensation. A specific software, firmware, or hardware implementation capable of compression or decompression in a specific video coding format is called a video codec.
In computer vision, rigid motion segmentation is the process of separating regions, features, or trajectories from a video sequence into coherent subsets of space and time. These subsets correspond to independent rigidly moving objects in the scene. The goal of this segmentation is to differentiate and extract the meaningful rigid motion from the background and analyze it. Image segmentation techniques labels the pixels to be a part of pixels with certain characteristics at a particular time. Here, the pixels are segmented depending on its relative movement over a period of time i.e. the time of the video sequence.

Block-matching and 3D filtering (BM3D) is a 3-D block-matching algorithm used primarily for noise reduction in images. It is one of the expansions of the non-local means methodology. There are two cascades in BM3D: a hard-thresholding and a Wiener filter stage, both involving the following parts: grouping, collaborative filtering, and aggregation. This algorithm depends on an augmented representation in the transformation site.

Video super-resolution (VSR) is the process of generating high-resolution video frames from the given low-resolution video frames. Unlike single-image super-resolution (SISR), the main goal is not only to restore more fine details while saving coarse ones, but also to preserve motion consistency.


