
In computer science and information theory, a Huffman code is a particular type of optimal prefix code that is commonly used for lossless data compression. The process of finding or using such a code is Huffman coding, an algorithm developed by David A. Huffman while he was a Sc.D. student at MIT, and published in the 1952 paper "A Method for the Construction of Minimum-Redundancy Codes".
Information theory is the mathematical study of the quantification, storage, and communication of information. The field was established and put on a firm footing by Claude Shannon in the 1940s, though early contributions were made in the 1920s through the works of Harry Nyquist and Ralph Hartley. It is at the intersection of electronic engineering, mathematics, statistics, computer science, neurobiology, physics, and electrical engineering.

In information theory, the entropy of a random variable quantifies the average level of uncertainty or information associated with the variable's potential states or possible outcomes. This measures the expected amount of information needed to describe the state of the variable, considering the distribution of probabilities across all potential states. Given a discrete random variable , which takes values in the set and is distributed according to , the entropy is where denotes the sum over the variable's possible values. The choice of base for , the logarithm, varies for different applications. Base 2 gives the unit of bits, while base e gives "natural units" nat, and base 10 gives units of "dits", "bans", or "hartleys". An equivalent definition of entropy is the expected value of the self-information of a variable.
In telecommunications and electronics, baud is a common unit of measurement of symbol rate, which is one of the components that determine the speed of communication over a data channel.

Image compression is a type of data compression applied to digital images, to reduce their cost for storage or transmission. Algorithms may take advantage of visual perception and the statistical properties of image data to provide superior results compared with generic data compression methods which are used for other digital data.
In information theory, an entropy coding is any lossless data compression method that attempts to approach the lower bound declared by Shannon's source coding theorem, which states that any lossless data compression method must have an expected code length greater than or equal to the entropy of the source.
In the field of data compression, Shannon–Fano coding, named after Claude Shannon and Robert Fano, is one of two related techniques for constructing a prefix code based on a set of symbols and their probabilities.

Arithmetic coding (AC) is a form of entropy encoding used in lossless data compression. Normally, a string of characters is represented using a fixed number of bits per character, as in the ASCII code. When a string is converted to arithmetic encoding, frequently used characters will be stored with fewer bits and not-so-frequently occurring characters will be stored with more bits, resulting in fewer bits used in total. Arithmetic coding differs from other forms of entropy encoding, such as Huffman coding, in that rather than separating the input into component symbols and replacing each with a code, arithmetic coding encodes the entire message into a single number, an arbitrary-precision fraction q, where 0.0 ≤ q < 1.0. It represents the current information as a range, defined by two numbers. A recent family of entropy coders called asymmetric numeral systems allows for faster implementations thanks to directly operating on a single natural number representing the current information.
A binary symmetric channel is a common communications channel model used in coding theory and information theory. In this model, a transmitter wishes to send a bit, and the receiver will receive a bit. The bit will be "flipped" with a "crossover probability" of p, and otherwise is received correctly. This model can be applied to varied communication channels such as telephone lines or disk drive storage.
Golomb coding is a lossless data compression method using a family of data compression codes invented by Solomon W. Golomb in the 1960s. Alphabets following a geometric distribution will have a Golomb code as an optimal prefix code, making Golomb coding highly suitable for situations in which the occurrence of small values in the input stream is significantly more likely than large values.
Rate–distortion theory is a major branch of information theory which provides the theoretical foundations for lossy data compression; it addresses the problem of determining the minimal number of bits per symbol, as measured by the rate R, that should be communicated over a channel, so that the source can be approximately reconstructed at the receiver without exceeding an expected distortion D.
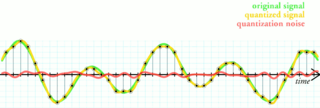
Quantization, in mathematics and digital signal processing, is the process of mapping input values from a large set to output values in a (countable) smaller set, often with a finite number of elements. Rounding and truncation are typical examples of quantization processes. Quantization is involved to some degree in nearly all digital signal processing, as the process of representing a signal in digital form ordinarily involves rounding. Quantization also forms the core of essentially all lossy compression algorithms.

Coding theory is the study of the properties of codes and their respective fitness for specific applications. Codes are used for data compression, cryptography, error detection and correction, data transmission and data storage. Codes are studied by various scientific disciplines—such as information theory, electrical engineering, mathematics, linguistics, and computer science—for the purpose of designing efficient and reliable data transmission methods. This typically involves the removal of redundancy and the correction or detection of errors in the transmitted data.
In information theory, Shannon's source coding theorem establishes the statistical limits to possible data compression for data whose source is an independent identically-distributed random variable, and the operational meaning of the Shannon entropy.
In information theory, the noisy-channel coding theorem, establishes that for any given degree of noise contamination of a communication channel, it is possible to communicate discrete data nearly error-free up to a computable maximum rate through the channel. This result was presented by Claude Shannon in 1948 and was based in part on earlier work and ideas of Harry Nyquist and Ralph Hartley.
A timeline of events related to information theory, quantum information theory and statistical physics, data compression, error correcting codes and related subjects.
The decisive event which established the discipline of information theory, and brought it to immediate worldwide attention, was the publication of Claude E. Shannon's classic paper "A Mathematical Theory of Communication" in the Bell System Technical Journal in July and October 1948.
In information theory, Shannon–Fano–Elias coding is a precursor to arithmetic coding, in which probabilities are used to determine codewords. It is named for Claude Shannon, Robert Fano, and Peter Elias.
In computer science and information theory, Tunstall coding is a form of entropy coding used for lossless data compression.
Asymmetric numeral systems (ANS) is a family of entropy encoding methods introduced by Jarosław (Jarek) Duda from Jagiellonian University, used in data compression since 2014 due to improved performance compared to previous methods. ANS combines the compression ratio of arithmetic coding, with a processing cost similar to that of Huffman coding. In the tabled ANS (tANS) variant, this is achieved by constructing a finite-state machine to operate on a large alphabet without using multiplication.




