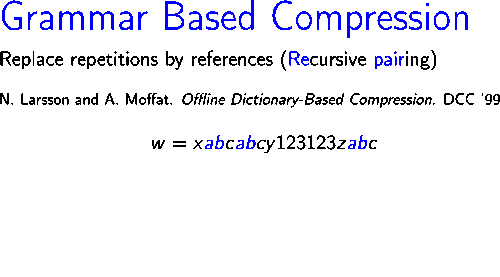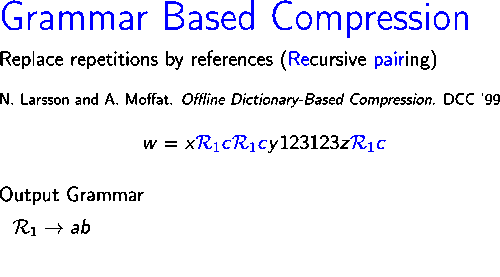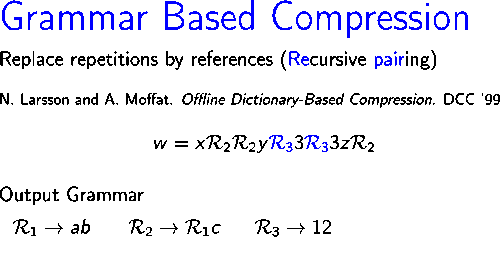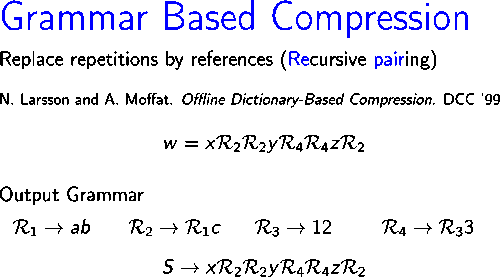
Once the grammar has been built for a given input string, in order to achieve effective compression, this grammar has to be encoded efficiently. One of the simplest methods for encoding the grammar is the implicit encoding, which consists on invoking function encodeCFG(X), described below, sequentially on all the axiom's symbols. Intuitively, rules are encoded as they are visited in a depth-first traversal of the grammar. The first time a rule is visited, its right hand side is encoded recursively and a new code is assigned to the rule. From that point, whenever the rule is reached, the assigned value is written.
num_rules_encoded=256// By default, the extended ASCII charset are the terminals of the grammar.writeSymbol(symbols){bitslen=log(num_rules_encoded);// Initially 8, to describe any extended ASCII characterwritesinbinaryusingbitslenbits}voidencodeCFG_rec(symbols){if(sisnon-terminalandthisisthefirsttimesymbolsappears){takerules→XY;writebit1;encodeCFG_rec(X);encodeCFG_rec(Y);assigntosymbolsvalue++num_rules_encoded;}else{writebit0;writeSymbol(terminal/valueassigned)}}voidencodeCFG(symbols){encodeCFG_rec(s);writebit1;}Another possibility is to separate the rules of the grammar into generations such that a rule  belongs to generation
belongs to generation  iff at least one of
iff at least one of  or
or  belongs to generation
belongs to generation  and the other belongs to generation
and the other belongs to generation  with
with  . Then these generations are encoded subsequently starting from generation
. Then these generations are encoded subsequently starting from generation  . This was the method proposed originally when Re-Pair was first introduced. However, most implementations of Re-Pair use the implicit encoding method due to its simplicity and good performance. Furthermore, it allows on-the-fly decompression.
. This was the method proposed originally when Re-Pair was first introduced. However, most implementations of Re-Pair use the implicit encoding method due to its simplicity and good performance. Furthermore, it allows on-the-fly decompression.