In information theory, data compression, source coding, or bit-rate reduction is the process of encoding information using fewer bits than the original representation. Any particular compression is either lossy or lossless. Lossless compression reduces bits by identifying and eliminating statistical redundancy. No information is lost in lossless compression. Lossy compression reduces bits by removing unnecessary or less important information. Typically, a device that performs data compression is referred to as an encoder, and one that performs the reversal of the process (decompression) as a decoder.
In information technology, lossy compression or irreversible compression is the class of data compression methods that uses inexact approximations and partial data discarding to represent the content. These techniques are used to reduce data size for storing, handling, and transmitting content. Higher degrees of approximation create coarser images as more details are removed. This is opposed to lossless data compression which does not degrade the data. The amount of data reduction possible using lossy compression is much higher than using lossless techniques.

MP3 is a coding format for digital audio developed largely by the Fraunhofer Society in Germany under the lead of Karlheinz Brandenburg. It was designed to greatly reduce the amount of data required to represent audio, yet still sound like a faithful reproduction of the original uncompressed audio to most listeners; for example, compared to CD-quality digital audio, MP3 compression can commonly achieve a 75–95% reduction in size, depending on the bit rate. In popular usage, MP3 often refers to files of sound or music recordings stored in the MP3 file format (.mp3) on consumer electronic devices.
Speech coding is an application of data compression to digital audio signals containing speech. Speech coding uses speech-specific parameter estimation using audio signal processing techniques to model the speech signal, combined with generic data compression algorithms to represent the resulting modeled parameters in a compact bitstream.
Linear predictive coding (LPC) is a method used mostly in audio signal processing and speech processing for representing the spectral envelope of a digital signal of speech in compressed form, using the information of a linear predictive model.
Vector quantization (VQ) is a classical quantization technique from signal processing that allows the modeling of probability density functions by the distribution of prototype vectors. Developed in the early 1980s by Robert M. Gray, it was originally used for data compression. It works by dividing a large set of points (vectors) into groups having approximately the same number of points closest to them. Each group is represented by its centroid point, as in k-means and some other clustering algorithms. In simpler terms, vector quantization chooses a set of points to represent a larger set of points.

Digital audio is a representation of sound recorded in, or converted into, digital form. In digital audio, the sound wave of the audio signal is typically encoded as numerical samples in a continuous sequence. For example, in CD audio, samples are taken 44,100 times per second, each with 16-bit resolution. Digital audio is also the name for the entire technology of sound recording and reproduction using audio signals that have been encoded in digital form. Following significant advances in digital audio technology during the 1970s and 1980s, it gradually replaced analog audio technology in many areas of audio engineering, record production and telecommunications in the 1990s and 2000s.
Speex is an audio compression codec specifically tuned for the reproduction of human speech and also a free software speech codec that may be used on voice over IP applications and podcasts. It is based on the code excited linear prediction speech coding algorithm. Its creators claim Speex to be free of any patent restrictions and it is licensed under the revised (3-clause) BSD license. It may be used with the Ogg container format or directly transmitted over UDP/RTP. It may also be used with the FLV container format.
Advanced Audio Coding (AAC) is an audio coding standard for lossy digital audio compression. It was designed to be the successor of the MP3 format and generally achieves higher sound quality than MP3 at the same bit rate.
Algebraic code-excited linear prediction (ACELP) is a speech coding algorithm in which a limited set of pulses is distributed as excitation to a linear prediction filter. It is a linear predictive coding (LPC) algorithm that is based on the code-excited linear prediction (CELP) method and has an algebraic structure. ACELP was developed in 1989 by the researchers at the Université de Sherbrooke in Canada.
G.728 is an ITU-T standard for speech coding operating at 16 kbit/s. It is officially described as Coding of speech at 16 kbit/s using low-delay code excited linear prediction.
Mixed-excitation linear prediction (MELP) is a United States Department of Defense speech coding standard used mainly in military applications and satellite communications, secure voice, and secure radio devices. Its standardization and later development was led and supported by the NSA and NATO. The current "enhanced" version is known as MELPe.
Harmonic Vector Excitation Coding, abbreviated as HVXC is a speech coding algorithm specified in MPEG-4 Part 3 standard for very low bit rate speech coding. HVXC supports bit rates of 2 and 4 kbit/s in the fixed and variable bit rate mode and sampling frequency of 8 kHz. It also operates at lower bitrates, such as 1.2 - 1.7 kbit/s, using a variable bit rate technique. The total algorithmic delay for the encoder and decoder is 36 ms.
FS-1016 is a deprecated secure telephony speech encoding standard for Code-excited linear prediction (CELP) developed by the United States Department of Defense and finalized February 14, 1991.

Secure voice is a term in cryptography for the encryption of voice communication over a range of communication types such as radio, telephone or IP.
Line spectral pairs (LSP) or line spectral frequencies (LSF) are used to represent linear prediction coefficients (LPC) for transmission over a channel. LSPs have several properties that make them superior to direct quantization of LPCs. For this reason, LSPs are very useful in speech coding.
Bandwidth expansion is a technique for widening the bandwidth or the resonances in an LPC filter. This is done by moving all the poles towards the origin by a constant factor . The bandwidth-expanded filter can be easily derived from the original filter by:

An audio coding format is a content representation format for storage or transmission of digital audio. Examples of audio coding formats include MP3, AAC, Vorbis, FLAC, and Opus. A specific software or hardware implementation capable of audio compression and decompression to/from a specific audio coding format is called an audio codec; an example of an audio codec is LAME, which is one of several different codecs which implements encoding and decoding audio in the MP3 audio coding format in software.
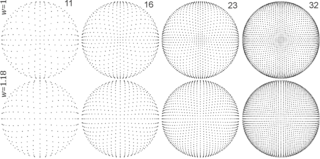
Pyramid vector quantization (PVQ) is a method used in audio and video codecs to quantize and transmit unit vectors, i.e. vectors whose magnitudes are known to the decoder but whose directions are unknown. PVQ may also be used as part of a gain/shape quantization scheme, whereby the magnitude and direction of a vector are quantized separately from each other. PVQ was initially described in 1986 in the paper "A Pyramid Vector Quantizer" by Thomas R. Fischer.







