As a simple example of the concept, if one flips a fair coin and does not yet know the outcome (heads or tails), then they lack a certain amount of information. After looking at the coin, they gain information about the outcome. For a fair coin, the probability of either heads or tails is 1/2 and the amount of information is expressed as = 1 bit of information.
A key concept in information theory is information entropy. Entropy is equal to the lack of information about an event. In the above coin flip example, the entropy in the case where you don't know the outcome is 1 bit. In the case where you do know the outcome, the entropy is zero because you have gained one bit of information.
Information theory, as conceived by Claude Shannon, studies the processing and utilization of information within a probabilistic context. Abstractly, in this approach information can be thought of as the resolution of uncertainty. In the case of communication of information over a noisy channel, this abstract concept was formalized in 1948 by Claude Shannon in a paper entitled A Mathematical Theory of Communication, in which information is thought of as a set of possible messages, and the goal is to send these messages over a noisy channel, and to have the receiver reconstruct the message with low probability of error, in spite of the channel noise. Shannon's main result, the noisy-channel coding theorem, showed that, in the limit of many channel uses, the rate of information that is asymptotically achievable is equal to the channel capacity, a quantity dependent merely on the statistics of the channel over which the messages are sent.[9]
Coding theory is concerned with finding explicit methods, called codes, for increasing the efficiency and reducing the error rate of data communication over noisy channels to near the channel capacity. These codes can be roughly subdivided into data compression (source coding) and error-correction (channel coding) techniques. In the latter case, it took many years to find the methods Shannon's work proved were possible.[24][25]
A third class of information theory codes are cryptographic algorithms (both codes and ciphers). Concepts, methods and results from coding theory and information theory are widely used in cryptography and cryptanalysis,[26] such as the unit ban.
The landmark event establishing the discipline of information theory and bringing it to immediate worldwide attention was the publication of Claude Shannon's classic paper "A Mathematical Theory of Communication" in the Bell System Technical Journal in July and October 1948. Historian James Gleick rated the paper as the most important development of 1948, noting that the paper was "even more profound and more fundamental" than the transistor.[27] He came to be known as the "father of information theory".[28][29][30] Shannon outlined some of his initial ideas of information theory as early as 1939 in a letter to Vannevar Bush.[30]
Prior to this paper, limited information-theoretic ideas had been developed at Bell Labs, all implicitly assuming events of equal probability. Harry Nyquist's 1924 paper, Certain Factors Affecting Telegraph Speed, contains a theoretical section quantifying "intelligence" and the "line speed" at which it can be transmitted by a communication system, giving the relation W = K log m (recalling the Boltzmann constant), where W is the speed of transmission of intelligence, m is the number of different voltage levels to choose from at each time step, and K is a constant. Ralph Hartley's 1928 paper, Transmission of Information, uses the word information as a measurable quantity, reflecting the receiver's ability to distinguish one sequence of symbols from any other, thus quantifying information as H = log Sn = n log S, where S was the number of possible symbols, and n the number of symbols in a transmission. The unit of information was therefore the decimal digit, which since has sometimes been called the hartley in his honor as a unit or scale or measure of information. Alan Turing in 1940 used similar ideas as part of the statistical analysis of the breaking of the German second world war Enigma ciphers.[citation needed]
In Shannon's revolutionary and groundbreaking paper, the work for which had been substantially completed at Bell Labs by the end of 1944, Shannon for the first time introduced the qualitative and quantitative model of communication as a statistical process underlying information theory, opening with the assertion:[32]
"The fundamental problem of communication is that of reproducing at one point, either exactly or approximately, a message selected at another point."
The mutual information, and the channel capacity of a noisy channel, including the promise of perfect loss-free communication given by the noisy-channel coding theorem;
Information theory is based on probability theory and statistics, where quantified information is usually described in terms of bits. Information theory often concerns itself with measures of information of the distributions associated with random variables. One of the most important measures is called entropy, which forms the building block of many other measures. Entropy allows quantification of measure of information in a single random variable.[33]
Another useful concept is mutual information defined on two random variables, which quantifies the dependence between those variables, which is done by comparing the conditional and unconditional distributions.[34] The former quantity is a property of the probability distribution of a random variable and gives a limit on the rate at which data generated by independent samples with the given distribution can be reliably compressed. The latter is a property of the joint distribution of two random variables and is the maximum rate of reliable communication across a noisy channel in the limit of long block lengths, when the channel statistics are determined by the joint distribution.
The choice of logarithmic base in the following formulae determines the unit of information entropy that is used. A common unit of information is the bit or shannon, based on the binary logarithm. Other units include the nat, which is based on the natural logarithm, and the decimal digit, which is based on the common logarithm.
In what follows, an expression of the form p log p is considered by convention to be equal to zero whenever p = 0. This is justified because for any logarithmic base.
The amount of information conveyed by an individual source symbol with probability is known as its self-information or surprisal, . This quantity is defined as:[37][38]
A less probable symbol has a larger surprisal, meaning its occurrence provides more information.[37] The entropy is the weighted average of the surprisal of all possible symbols from the source's probability distribution:[39][40]
Intuitively, the entropy of a discrete random variableX is a measure of the amount of uncertainty associated with the value of when only its distribution is known.[35] A high entropy indicates the outcomes are more evenly distributed, making the result harder to predict.[41]
For example, if one transmits 1000 bits (0s and 1s), and the value of each of these bits is known to the receiver (has a specific value with certainty) ahead of transmission, no information is transmitted. If, however, each bit is independently and equally likely to be 0 or 1, 1000 shannons of information (more often called bits) have been transmitted.[42]
The entropy of a Bernoulli trial as a function of success probability, often called the binary entropy function, Hb(p). The entropy is maximized at 1 bit per trial when the two possible outcomes are equally probable, as in an unbiased coin toss.
Properties
A key property of entropy is that it is maximized when all the messages in the message space are equiprobable. For a source with n possible symbols, where for all , the entropy is given by:[43]
This maximum value represents the most unpredictable state.[39]
For a source that emits a sequence of symbols that are independent and identically distributed (i.i.d.), the total entropy of the message is bits. If the source data symbols are identically distributed but not independent, the entropy of a message of length will be less than .[44][45]
Units
The choice of the logarithmic base in the entropy formula determines the unit of entropy used:[37][39]
A base-2 logarithm (as shown in the main formula) measures entropy in bits per symbol. This unit is also sometimes called the shannon in honor of Claude Shannon.[35]
A Natural logarithm (base e) measures entropy in nats per symbol. This is often used in theoretical analysis as it avoids the need for scaling constants (like ln 2) in derivations.[46]
Other bases are also possible. A base-10 logarithm measures entropy in decimal digits, or hartleys, per symbol.[36] A base-256 logarithm measures entropy in bytes per symbol, since 28 = 256.[47]
Binary Entropy Function
The special case of information entropy for a random variable with two outcomes (a Bernoulli trial) is the binary entropy function. This is typically calculated using a base-2 logarithm, and its unit is the shannon.[48] If one outcome has probability p, the other has probability 1 − p. The entropy is given by:[49]
This function is depicted in the plot shown above, reaching its maximum of 1 bit when p = 0.5, corresponding to the highest uncertainty.
Joint entropy
The joint entropy of two discrete random variables X and Y is merely the entropy of their pairing: (X, Y). This implies that if X and Y are independent, then their joint entropy is the sum of their individual entropies.
For example, if (X, Y) represents the position of a chess piece—X the row and Y the column, then the joint entropy of the row of the piece and the column of the piece will be the entropy of the position of the piece.
Despite similar notation, joint entropy should not be confused with cross-entropy.
The join entropy of discrete random variables is
This can also be represented as a summation of their joint probability mass function:
.
Thus, joint entropy is just a subcase of entropy where the random variable is a vector giving values in the product space.[34]
Conditional entropy (equivocation)
The conditional entropy or conditional uncertainty of X given random variable Y (also called the equivocation of X about Y) is the average conditional entropy over Y:[50]
Because entropy can be conditioned on a random variable or on that random variable being a certain value, care should be taken not to confuse these two definitions of conditional entropy, the former of which is in more common use. A basic property of this form of conditional entropy is that:
Mutual information (transinformation)
Mutual information measures the amount of information that can be obtained about one random variable by observing another. It is important in communication where it can be used to maximize the amount of information shared between sent and received signals. The mutual information of X relative to Y is given by:
In other words, this is a measure of how much, on the average, the probability distribution on will change if we are given the value of . This is often recalculated as the divergence from the product of the marginal distributions to the actual joint distribution:
Mutual information is closely related to the log-likelihood ratio test in the context of contingency tables and the multinomial distribution and to Pearson's χ2 test: mutual information can be considered a statistic for assessing independence between a pair of variables, and has a well-specified asymptotic distribution.
Kullback–Leibler divergence (information gain)
The Kullback–Leibler divergence (or information divergence, information gain, or relative entropy) is a way of comparing two distributions: a "true" probability distribution, and an arbitrary probability distribution . If we compress data in a manner that assumes is the distribution underlying some data, when, in reality, is the correct distribution, the Kullback–Leibler divergence is the number of average additional bits per datum necessary for compression. It is thus defined
Although it is sometimes used as a 'distance metric', KL divergence is not a true metric since it is not symmetric and does not satisfy the triangle inequality (making it a semi-quasimetric).
Another interpretation of the KL divergence is the "unnecessary surprise" introduced by a prior from the truth: suppose a number is about to be drawn randomly from a discrete set with probability distribution . If Alice knows the true distribution , while Bob believes (has a prior) that the distribution is , then Bob will be more surprised than Alice, on average, upon seeing the value of . The KL divergence is the (objective) expected value of Bob's (subjective) surprisal minus Alice's surprisal, measured in bits if the log is in base 2. In this way, the extent to which Bob's prior is "wrong" can be quantified in terms of how "unnecessarily surprised" it is expected to make him.
Directed Information
Directed information, , is an information theory measure that quantifies the information flow from the random process to the random process . The term directed information was coined by James Massey and is defined as:
In contrast to mutual information, directed information is not symmetric. The measures the information bits that are transmitted causally[clarification needed] from to . The Directed information has many applications in problems where causality plays an important role such as capacity of channel with feedback,[51][52] capacity of discrete memoryless networks with feedback,[53]gambling with causal side information,[54]compression with causal side information,[55]real-time control communication settings,[56][57] and in statistical physics.[58]
Other quantities
Other important information theoretic quantities include the Rényi entropy and the Tsallis entropy (generalizations of the concept of entropy), differential entropy (a generalization of quantities of information to continuous distributions), and the conditional mutual information. Also, pragmatic information has been proposed as a measure of how much information has been used in making a decision.
A picture showing scratches on the readable surface of a CD-R. Music and data CDs are coded using error correcting codes and thus can still be read even if they have minor scratches using error detection and correction.
Coding theory is one of the most important and direct applications of information theory. It can be subdivided into source coding theory and channel coding theory. Using a statistical description for data, information theory quantifies the number of bits needed to describe the data, which is the information entropy of the source.
Data compression (source coding): There are two formulations for the compression problem:
Lossy data compression: allocates bits needed to reconstruct the data, within a specified fidelity level measured by a distortion function. This subset of information theory is called rate–distortion theory.
Error-correcting codes (channel coding): While data compression removes as much redundancy as possible, an error-correcting code adds just the right kind of redundancy (i.e., error correction) needed to transmit the data efficiently and faithfully across a noisy channel.
This division of coding theory into compression and transmission is justified by the information transmission theorems, or source–channel separation theorems that justify the use of bits as the universal currency for information in many contexts. However, these theorems only hold in the situation where one transmitting user wishes to communicate to one receiving user. In scenarios with more than one transmitter (the multiple-access channel), more than one receiver (the broadcast channel) or intermediary "helpers" (the relay channel), or more general networks, compression followed by transmission may no longer be optimal.
Source theory
Any process that generates successive messages can be considered a source of information. A memoryless source is one in which each message is an independent identically distributed random variable, whereas the properties of ergodicity and stationarity impose less restrictive constraints. All such sources are stochastic. These terms are well studied in their own right outside information theory.
Rate
Information rate is the average entropy per symbol. For memoryless sources, this is merely the entropy of each symbol, while, in the case of a stationary stochastic process, it is:
that is, the conditional entropy of a symbol given all the previous symbols generated. For the more general case of a process that is not necessarily stationary, the average rate is:
that is, the limit of the joint entropy per symbol. For stationary sources, these two expressions give the same result.[59]
It is common in information theory to speak of the "rate" or "entropy" of a language. This is appropriate, for example, when the source of information is English prose. The rate of a source of information is related to its redundancy and how well it can be compressed, the subject of source coding.
Communications over a channel is the primary motivation of information theory. However, channels often fail to produce exact reconstruction of a signal; noise, periods of silence, and other forms of signal corruption often degrade quality.
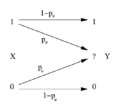
Consider the communications process over a discrete channel. A simple model of the process is shown below:
Here represents the space of messages transmitted, and the space of messages received during a unit time over our channel. Let p(y|x) be the conditional probability distribution function of given . We will consider p(y|x) to be an inherent fixed property of our communications channel (representing the nature of the noise of our channel). Then the joint distribution of and is completely determined by our channel and by our choice of f(x), the marginal distribution of messages we choose to send over the channel. Under these constraints, we would like to maximize the rate of information, or the signal, we can communicate over the channel. The appropriate measure for this is the mutual information, and this maximum mutual information is called the channel capacity and is given by:
This capacity has the following property related to communicating at information rate R (where R is usually bits per symbol). For any information rate R < C and coding error ε > 0, for large enough N, there exists a code of length N and rate ≥ R and a decoding algorithm, such that the maximal probability of block error is ≤ ε; that is, it is always possible to transmit with arbitrarily small block error. In addition, for any rate R>C, it is impossible to transmit with arbitrarily small block error.
Channel coding is concerned with finding such nearly optimal codes that can be used to transmit data over a noisy channel with a small coding error at a rate near the channel capacity.
A binary symmetric channel (BSC) with crossover probability p is a binary input, binary output channel that flips the input bit with probability p. The BSC has a capacity of 1 −Hb(p) bits per channel use, where Hb is the binary entropy function to the base-2 logarithm:
A binary erasure channel (BEC) with erasure probability p is a binary input, ternary output channel. The possible channel outputs are 0, 1, and a third symbol 'e' called an erasure. The erasure represents complete loss of information about an input bit. The capacity of the BEC is 1 −p bits per channel use.
Channels with memory and directed information
In practice many channels have memory. Namely, at time the channel is given by the conditional probability. It is often more comfortable to use the notation and the channel become . In such a case the capacity is given by the mutual information rate when there is no feedback available and the Directed information rate in the case that either there is feedback or not[51][60] (if there is no feedback the directed information equals the mutual information).
Fungible information
Fungible information is the information for which the means of encoding is not important.[61] Classical information theorists and computer scientists are mainly concerned with information of this sort. It is sometimes referred as speakable information.[62]
Applications to other fields
Network physiology
Information theory concepts, methods and approaches have broad applications in network physiology,[63][64][65] a field which provides a quantitative framework, based on adaptive networks of dynamical systems, to investigate how physiological systems exchange, process, and integrate information as a network to (i) coordinate their functions across levels and scales (from sub-cellular to organs and organism level) and (ii) generate distinct physiological states in health and disease. Through measures such as mutual information, transfer entropy, and co-information, information theory enables the detection of coupling strength, directionality, synergy/redundancy and higher-order interactions among physiological systems and sub-systems, revealing how network cross-communication and regulation occur within the organism. Applications of information-theoretic approaches span from analyzing information transfer between brain and body networks during various states;[66][67][68] cardio-respiratory interactions;[69][70][71] cardio-muscular interactions;[72] cortico-muscular interactions;[73][74] brain wave interactions and brain functional networks;[75][76][77][78][79] network physiology in extreme environments.[80]
Information theoretic concepts apply to cryptography and cryptanalysis. Turing's information unit, the ban, was used in the Ultra project, breaking the German Enigma machine code and hastening the end of World War II in Europe. Shannon himself defined an important concept now called the unicity distance. Based on the redundancy of the plaintext, it attempts to give a minimum amount of ciphertext necessary to ensure unique decipherability.
Information theory leads us to believe it is much more difficult to keep secrets than it might first appear. A brute force attack can break systems based on asymmetric key algorithms or on most commonly used methods of symmetric key algorithms (sometimes called secret key algorithms), such as block ciphers. The security of all such methods comes from the assumption that no known attack can break them in a practical amount of time.
Information theoretic security refers to methods such as the one-time pad that are not vulnerable to such brute force attacks. In such cases, the positive conditional mutual information between the plaintext and ciphertext (conditioned on the key) can ensure proper transmission, while the unconditional mutual information between the plaintext and ciphertext remains zero, resulting in absolutely secure communications. In other words, an eavesdropper would not be able to improve his or her guess of the plaintext by gaining knowledge of the ciphertext but not of the key. However, as in any other cryptographic system, care must be used to correctly apply even information-theoretically secure methods; the Venona project was able to crack the one-time pads of the Soviet Union due to their improper reuse of key material.
Pseudorandom number generators are widely available in computer language libraries and application programs. They are, almost universally, unsuited to cryptographic use as they do not evade the deterministic nature of modern computer equipment and software. A class of improved random number generators is termed cryptographically secure pseudorandom number generators, but even they require random seeds external to the software to work as intended. These can be obtained via extractors, if done carefully. The measure of sufficient randomness in extractors is min-entropy, a value related to Shannon entropy through Rényi entropy; Rényi entropy is also used in evaluating randomness in cryptographic systems. Although related, the distinctions among these measures mean that a random variable with high Shannon entropy is not necessarily satisfactory for use in an extractor and so for cryptography uses.
Seismic exploration
One early commercial application of information theory was in the field of seismic oil exploration. Work in this field made it possible to strip off and separate the unwanted noise from the desired seismic signal. Information theory and digital signal processing offer a major improvement of resolution and image clarity over previous analog methods.[81]
Semiotics
SemioticiansDoede Nauta[nl] and Winfried Nöth both considered Charles Sanders Peirce as having created a theory of information in his works on semiotics.[82]:171[83]:137 Nauta defined semiotic information theory as the study of "the internal processes of coding, filtering, and information processing."[82]:91
Concepts from information theory such as redundancy and code control have been used by semioticians such as Umberto Eco and Ferruccio Rossi-Landi[it] to explain ideology as a form of message transmission whereby a dominant social class emits its message by using signs that exhibit a high degree of redundancy such that only one message is decoded among a selection of competing ones.[84]
Integrated process organization of neural information
Quantitative information theoretic methods have been applied in cognitive science to analyze the integrated process organization of neural information in the context of the binding problem in cognitive neuroscience.[85] In this context, either an information-theoretical measure, such as functional clusters (Gerald Edelman and Giulio Tononi's functional clustering model and dynamic core hypothesis (DCH)[86]) or effective information (Tononi's integrated information theory (IIT) of consciousness[87][88][89]), is defined (on the basis of a reentrant process organization, i.e. the synchronization of neurophysiological activity between groups of neuronal populations), or the measure of the minimization of free energy on the basis of statistical methods (Karl J. Friston's free energy principle (FEP), an information-theoretical measure which states that every adaptive change in a self-organized system leads to a minimization of free energy, and the Bayesian brain hypothesis[90][91][92][93][94]).
↑Burnham, K. P.; Anderson, D. R. (2002). Model Selection and Multimodel Inference: A Practical Information-Theoretic Approach (Seconded.). New York: Springer Science. ISBN978-0-387-95364-9.
12F. Rieke; D. Warland; R Ruyter van Steveninck; W Bialek (1997). Spikes: Exploring the Neural Code. The MIT press. ISBN978-0-262-68108-7.
↑Loy, D. Gareth (2017), Pareyon, Gabriel; Pina-Romero, Silvia; Agustín-Aquino, Octavio A.; Lluis-Puebla, Emilio (eds.), "Music, Expectation, and Information Theory", The Musical-Mathematical Mind: Patterns and Transformations, Computational Music Science, Cham: Springer International Publishing, pp.161–169, doi:10.1007/978-3-319-47337-6_17, ISBN978-3-319-47337-6, retrieved 2024-09-19{{citation}}: CS1 maint: work parameter with ISBN (link)
↑Pinkard, Henry; Kabuli, Leyla; Markley, Eric; Chien, Tiffany; Jiao, Jiantao; Waller, Laura (2024). "Universal evaluation and design of imaging systems using information estimation". arXiv:2405.20559 [physics.optics].
12Polyanskiy, Yury; Wu, Yihong (2025). Information theory: from coding to learning. Cambridge, United Kingdom; New York, NY: Cambridge University Press. ISBN978-1-108-83290-8.
123Cover, Thomas M.; Thomas, Joy A. (2006). Elements of Information Theory (2nded.). Wiley-Interscience. p.14. ISBN978-0-471-24195-9.
12Arndt, C. (2004). Information Measures: Information and its Description in Science and Engineering. Springer. p.5. ISBN978-3-540-40855-0.
123MacKay, David J.C. (2003). Information Theory, Inference and Learning Algorithms. Cambridge University Press. p.29. ISBN978-0-521-64298-9.
↑Cover, Thomas M.; Thomas, Joy A. (2006). Elements of Information Theory (2nded.). Wiley-Interscience. p.1. ISBN978-0-471-24195-9.
↑Cover, Thomas M.; Thomas, Joy A. (2006). Elements of Information Theory (2nded.). Wiley-Interscience. p.27. ISBN978-0-471-24195-9. Theorem 2.6.2: H(X) ≤ log|X|, with equality if and only if X has a uniform distribution over X.
↑Cover, Thomas M.; Thomas, Joy A. (2006). Elements of Information Theory (2nded.). Wiley-Interscience. p.63. ISBN978-0-471-24195-9.
↑MacKay, David J.C. (2003). Information Theory, Inference and Learning Algorithms. Cambridge University Press. p.75. ISBN978-0-521-64298-9.
↑Leung, K. (2011). "Information Theory and the Central Limit Theorem"(PDF). Purdue University. Retrieved 2025-07-06. The unit of information is determined by the base of the logarithm. If the base is 2, the unit is bits. If the base is e, the unit is nats.
↑MacKay, David J.C. (2003). Information Theory, Inference and Learning Algorithms. Cambridge University Press. p.30. ISBN978-0-521-64298-9. If we use logarithms to the base b, we are measuring information in units of logb 2 bits. We can call a quantity of information of log2 256 = 8 bits one byte.
↑Cover, Thomas M.; Thomas, Joy A. (2006). Elements of Information Theory (2nded.). Wiley-Interscience. p.15. ISBN978-0-471-24195-9.
↑MacKay, David J.C. (2003). Information Theory, Inference and Learning Algorithms. Cambridge University Press. p.145. ISBN978-0-521-64298-9.
12Massey, James (1990), "Causality, Feedback And Directed Information", Proc. 1990 Intl. Symp. on Info. Th. and its Applications, CiteSeerX10.1.1.36.5688
↑Maurer, H. (2021). "Chapter 10: Systematic Class of Information Based Architecture Types". Cognitive Science: Integrative Synchronization Mechanisms in Cognitive Neuroarchitectures of the Modern Connectionism. Boca Raton/FL: CRC Press. doi:10.1201/9781351043526. ISBN978-1-351-04352-6.
↑Edelman, G.M.; Tononi, G. (2000). A Universe of Consciousness: How Matter Becomes Imagination. New York: Basic Books. ISBN978-0-465-01377-7.
J. L. Kelly Jr., PrincetonArchived 2020-08-01 at the Wayback Machine , "A New Interpretation of Information Rate" Bell System Technical Journal, Vol. 35, July 1956, pp.917–26.
R. Landauer, IEEE.org, "Information is Physical" Proc. Workshop on Physics and Computation PhysComp'92 (IEEE Comp. Sci.Press, Los Alamitos, 1993) pp.1–4.
Timme, Nicholas; Alford, Wesley; Flecker, Benjamin; Beggs, John M. (2012). "Multivariate information measures: an experimentalist's perspective". arXiv:1111.6857 [cs.IT].
Textbooks on information theory
Alajaji, F. and Chen, P.N. An Introduction to Single-User Information Theory. Singapore: Springer, 2018. ISBN978-981-10-8000-5
Arndt, C. Information Measures, Information and its Description in Science and Engineering (Springer Series: Signals and Communication Technology), 2004, ISBN978-3-540-40855-0
A. I. Khinchin, Mathematical Foundations of Information Theory, New York: Dover, 1957. ISBN0-486-60434-9
H. S. Leff and A. F. Rex, Editors, Maxwell's Demon: Entropy, Information, Computing, Princeton University Press, Princeton, New Jersey (1990). ISBN0-691-08727-X
Robert K. Logan. What is Information? - Propagating Organization in the Biosphere, the Symbolosphere, the Technosphere and the Econosphere, Toronto: DEMO Publishing.
Tom Siegfried, The Bit and the Pendulum, Wiley, 2000. ISBN0-471-32174-5
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.