In probability theory, conditional probability is a measure of the probability of an event occurring, given that another event (by assumption, presumption, assertion or evidence) is already known to have occurred.[1] This particular method relies on event A occurring with some sort of relationship with another event B. In this situation, the event A can be analyzed by a conditional probability with respect to B. If the event of interest is A and the event B is known or assumed to have occurred, "the conditional probability of A given B", or "the probability of A under the condition B", is usually written as P(A|B)[2] or occasionally PB(A). This can also be understood as the fraction of probability B that intersects with A, or the ratio of the probabilities of both events happening to the "given" one happening (how many times A occurs rather than not assuming B has occurred):
For example, the probability that any given person has a cough on any given day may be only 5%. But if we know or assume that the person is sick, then they are much more likely to be coughing. For example, the conditional probability that someone sick is coughing might be 75%, in which case we would have that P(Cough) = 5% and P(Cough|Sick) = 75%. Although there is a relationship between A and B in this example, such a relationship or dependence between A and B is not necessary, nor do they have to occur simultaneously.
P(A|B) may or may not be equal to P(A), i.e., the unconditional probability or absolute probability of A. If P(A|B) = P(A), then events A and B are said to be independent: in such a case, knowledge about either event does not alter the likelihood of each other. P(A|B) (the conditional probability of A given B) typically differs from P(B|A). For example, if a person has dengue fever, the person might have a 90% chance of being tested as positive for the disease. In this case, what is being measured is that if event B (having dengue) has occurred, the probability of A (tested as positive) given that B occurred is 90%, simply writing P(A|B) = 90%. Alternatively, if a person is tested as positive for dengue fever, they may have only a 15% chance of actually having this rare disease due to high false positive rates. In this case, the probability of the event B (having dengue) given that the event A (testing positive) has occurred is 15% or P(B|A) = 15%. It should be apparent now that falsely equating the two probabilities can lead to various errors of reasoning, which is commonly seen through base rate fallacies.
While conditional probabilities can provide extremely useful information, limited information is often supplied or at hand. Therefore, it can be useful to reverse or convert a conditional probability using Bayes' theorem: .[4] Another option is to display conditional probabilities in a conditional probability table to illuminate the relationship between events.
Definition
Illustration of conditional probabilities with an Euler diagram. The unconditional probability P(A) = 0.30 + 0.10 + 0.12 = 0.52. However, the conditional probability P(A|B1) = 1, P(A|B2) = 0.12 ÷ (0.12 + 0.04) = 0.75, and P(A|B3) = 0.On a tree diagram, branch probabilities are conditional on the event associated with the parent node. (Here, the overbars indicate that the event does not occur.)Venn pie chart describing conditional probabilities
Given two eventsA and B from the sigma-field of a probability space, with the unconditional probability of B being greater than zero (i.e., P(B) > 0), the conditional probability of A given B () is the probability of A occurring if B has or is assumed to have happened.[5]A is assumed to be the set of all possible outcomes of an experiment or random trial that has a restricted or reduced sample space. The conditional probability can be found by the quotient of the probability of the joint intersection of events A and B, that is, , the probability at which A and B occur together, and the probability of B:[2][6][7]
For a sample space consisting of equal likelihood outcomes, the probability of the event A is understood as the fraction of the number of outcomes in A to the number of all outcomes in the sample space. Then, this equation is understood as the fraction of the set to the set B. Note that the above equation is a definition, not just a theoretical result. We denote the quantity as and call it the "conditional probability of A given B."
This equation for a conditional probability, although mathematically equivalent, may be intuitively easier to understand. It can be interpreted as "the probability of B occurring multiplied by the probability of A occurring, provided that B has occurred, is equal to the probability of the A and B occurrences together, although not necessarily occurring at the same time". Additionally, this may be preferred philosophically; under major probability interpretations, such as the subjective theory, conditional probability is considered a primitive entity. Moreover, this "multiplication rule" can be practically useful in computing the probability of and introduces a symmetry with the summation axiom for Poincaré Formula:
Thus the equations can be combined to find a new representation of the:
As the probability of a conditional event
Conditional probability can be defined as the probability of a conditional event . The Goodman–Nguyen–Van Fraassen conditional event can be defined as:
where and represent states or elements of A or B.[8]
It can be shown that
which meets the Kolmogorov definition of conditional probability.[9]
Conditioning on an event of probability zero
If , then according to the definition, is undefined.
The case of greatest interest is that of a random variable Y, conditioned on a continuous random variable X resulting in a particular outcome x. The event has probability zero and, as such, cannot be conditioned on.
Instead of conditioning on X being exactlyx, we could condition on it being closer than distance away from x. The event will generally have nonzero probability and hence, can be conditioned on. We can then take the limit
1
For example, if two continuous random variables X and Y have a joint density , then by L'Hôpital's rule and Leibniz integral rule, upon differentiation with respect to :
The resulting limit is the conditional probability distribution of Y given X and exists when the denominator, the probability density , is strictly positive.
It is tempting to define the undefined probability using limit (1), but this cannot be done in a consistent manner. In particular, it is possible to find random variables X and W and values x, w such that the events and are identical but the resulting limits are not:
Let X be a discrete random variable and its possible outcomes denoted V. For example, if X represents the value of a rolled dice then V is the set . Let us assume for the sake of presentation that X is a discrete random variable, so that each value in V has a nonzero probability.
For a value x in V and an event A, the conditional probability is given by . Writing
for short, we see that it is a function of two variables, x and A.
For a fixed A, we can form the random variable . It represents an outcome of whenever a value x of X is observed.
The conditional probability of A given X can thus be treated as a random variable Y with outcomes in the interval . From the law of total probability, its expected value is equal to the unconditional probability of A.
Partial conditional probability
The partial conditional probability is about the probability of event given that each of the condition events has occurred to a degree (degree of belief, degree of experience) that might be different from 100%. Frequentistically, partial conditional probability makes sense, if the conditions are tested in experiment repetitions of appropriate length .[10] Such -bounded partial conditional probability can be defined as the conditionally expected average occurrence of event in testbeds of length that adhere to all of the probability specifications , i.e.:
Suppose that somebody secretly rolls two fair six-sided dice, and we wish to compute the probability that the face-up value of the first one is 2, given the information that their sum is no greater than 5.
Table 1 shows the sample space of 36 combinations of rolled values of the two dice, each of which occurs with probability 1/36, with the numbers displayed in the red and dark gray cells being D1 + D2.
D1=2 in exactly 6 of the 36 outcomes; thus P(D1 = 2)=6⁄36=1⁄6:
Table 1
+
D2
1
2
3
4
5
6
D1
1
2
3
4
5
6
7
2
3
4
5
6
7
8
3
4
5
6
7
8
9
4
5
6
7
8
9
10
5
6
7
8
9
10
11
6
7
8
9
10
11
12
Probability thatD1+D2≤5
Table 2 shows that D1+D2≤5 for exactly 10 of the 36 outcomes, thus P(D1+D2≤5)=10⁄36:
Table 2
+
D2
1
2
3
4
5
6
D1
1
2
3
4
5
6
7
2
3
4
5
6
7
8
3
4
5
6
7
8
9
4
5
6
7
8
9
10
5
6
7
8
9
10
11
6
7
8
9
10
11
12
Probability thatD1=2 given thatD1+D2≤5
Table 3 shows that for 3 of these 10 outcomes, D1=2.
Thus, the conditional probability P(D1=2|D1+D2≤5)=3⁄10=0.3:
Table 3
+
D2
1
2
3
4
5
6
D1
1
2
3
4
5
6
7
2
3
4
5
6
7
8
3
4
5
6
7
8
9
4
5
6
7
8
9
10
5
6
7
8
9
10
11
6
7
8
9
10
11
12
Here, in the earlier notation for the definition of conditional probability, the conditioning event B is that D1+D2≤5, and the event A is D1=2. We have as seen in the table.
Use in inference
In statistical inference, the conditional probability is an update of the probability of an event based on new information.[13] The new information can be incorporated as follows:[1]
Let A, the event of interest, be in the sample space, say (X,P).
The occurrence of the event A knowing that event B has or will have occurred, means the occurrence of A as it is restricted to B, i.e. .
Without the knowledge of the occurrence of B, the information about the occurrence of A would simply be P(A)
The probability of A knowing that event B has or will have occurred, will be the probability of relative to P(B), the probability that B has occurred.
This results in whenever P(B)>0 and 0 otherwise.
This approach results in a probability measure that is consistent with the original probability measure and satisfies all the Kolmogorov axioms. This conditional probability measure also could have resulted by assuming that the relative magnitude of the probability of A with respect to X will be preserved with respect to B (cf. a Formal Derivation below).
The wording "evidence" or "information" is generally used in the Bayesian interpretation of probability. The conditioning event is interpreted as evidence for the conditioned event. That is, P(A) is the probability of A before accounting for evidence E, and P(A|E) is the probability of A after having accounted for evidence E or after having updated P(A). This is consistent with the frequentist interpretation, which is the first definition given above.
Example
When Morse code is transmitted, there is a certain probability that the "dot" or "dash" that was received is erroneous. This is often taken as interference in the transmission of a message. Therefore, it is important to consider when sending a "dot", for example, the probability that a "dot" was received. This is represented by: In Morse code, the ratio of dots to dashes is 3:4 at the point of sending, so the probabilities of a "dot" and "dash" are . If it is assumed that the probability that a dot is transmitted as a dash is 1/10, and that the probability that a dash is transmitted as a dot is likewise 1/10, then Bayes's rule can be used to calculate .
Events A and B are defined to be statistically independent if the probability of the intersection of A and B is equal to the product of the probabilities of A and B:
If P(B) is not zero, then this is equivalent to the statement that
Similarly, if P(A) is not zero, then
is also equivalent. Although the derived forms may seem more intuitive, they are not the preferred definition as the conditional probabilities may be undefined, and the preferred definition is symmetrical in A and B. Independence does not refer to a disjoint event.[15]
It should also be noted that given the independent event pair [A,B] and an event C, the pair is defined to be conditionally independent if[16]
This theorem is useful in applications where multiple independent events are being observed.
Independent events vs. mutually exclusive events
The concepts of mutually independent events and mutually exclusive events are separate and distinct. The following table contrasts results for the two cases (provided that the probability of the conditioning event is not zero).
If statistically independent
If mutually exclusive
0
0
0
In fact, mutually exclusive events cannot be statistically independent (unless both of them are impossible), since knowing that one occurs gives information about the other (in particular, that the latter will certainly not occur).
Common fallacies
These fallacies should not be confused with Robert K. Shope's 1978 "conditional fallacy", which deals with counterfactual examples that beg the question.
Assuming conditional probability is of similar size to its inverse
A geometric visualization of Bayes' theorem. In the table, the values 2, 3, 6 and 9 give the relative weights of each corresponding condition and case. The figures denote the cells of the table involved in each metric, the probability being the fraction of each figure that is shaded. This shows that i.e. . Similar reasoning can be used to show that etc.
In general, it cannot be assumed that P(A|B)≈P(B|A). This can be an insidious error, even for those who are highly conversant with statistics.[17] The relationship between P(A|B) and P(B|A) is given by Bayes' theorem:
That is, P(A|B)≈P(B|A) only if P(B)/P(A)≈1, or equivalently, P(A)≈P(B).
Assuming marginal and conditional probabilities are of similar size
In general, it cannot be assumed that P(A)≈P(A|B). These probabilities are linked through the law of total probability:
This fallacy may arise through selection bias.[18] For example, in the context of a medical claim, let SC be the event that a sequela (chronic disease) S occurs as a consequence of circumstance (acute condition) C. Let H be the event that an individual seeks medical help. Suppose that in most cases, C does not cause S (so that P(SC) is low). Suppose also that medical attention is only sought if S has occurred due to C. From experience of patients, a doctor may therefore erroneously conclude that P(SC) is high. The actual probability observed by the doctor is P(SC|H).
Over- or under-weighting priors
Not taking prior probability into account partially or completely is called base rate neglect. The reverse, insufficient adjustment from the prior probability is conservatism.
Formal derivation
Formally, P(A|B) is defined as the probability of A according to a new probability function on the sample space, such that outcomes not in B have probability 0 and that it is consistent with all original probability measures.[19][20]
Let Ω be a discrete sample space with elementary events {ω}, and let P be the probability measure with respect to the σ-algebra of Ω. Suppose we are told that the event B⊆Ω has occurred. A new probability distribution (denoted by the conditional notation) is to be assigned on {ω} to reflect this. All events that are not in B will have null probability in the new distribution. For events in B, two conditions must be met: the probability of B is one and the relative magnitudes of the probabilities must be preserved. The former is required by the axioms of probability, and the latter stems from the fact that the new probability measure has to be the analog of P in which the probability of B is one—and every event that is not in B, therefore, has a null probability. Hence, for some scale factor α, the new distribution must satisfy:
↑ Reichl, Linda Elizabeth (2016). "2.3 Probability". A Modern Course in Statistical Physics (4th revised and updateded.). WILEY-VCH. ISBN978-3-527-69049-7.
↑ Kolmogorov, Andrey (1956), Foundations of the Theory of Probability, Chelsea
↑ Van Fraassen, Bas C. (1976), Harper, William L.; Hooker, Clifford Alan (eds.), "Probabilities of Conditionals", Foundations of Probability Theory, Statistical Inference, and Statistical Theories of Science: Volume I Foundations and Philosophy of Epistemic Applications of Probability Theory, The University of Western Ontario Series in Philosophy of Science, Dordrecht: Springer Netherlands, pp.261–308, doi:10.1007/978-94-010-1853-1_10, ISBN978-94-010-1853-1, retrieved 2021-12-04
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.





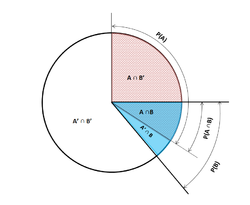



























































![A geometric visualization of Bayes' theorem. In the table, the values 2, 3, 6 and 9 give the relative weights of each corresponding condition and case. The figures denote the cells of the table involved in each metric, the probability being the fraction of each figure that is shaded. This shows that
P
(
A
|
B
)
P
(
B
)
=
P
(
B
|
A
)
P
(
A
)
{\displaystyle P(A\mid B)P(B)=P(B\mid A)P(A)}
i.e.
P
(
A
|
B
)
=
P
(
B
|
A
)
P
(
A
)
[?]
P
(
B
)
{\displaystyle P(A\mid B)={\frac {P(B\mid A)}{P(A)\cdot P(B)}}}
. Similar reasoning can be used to show that
P
(
A
-
|
B
)
=
P
(
B
|
A
-
)
P
(
A
-
)
P
(
B
)
{\displaystyle P({\bar {A}}\mid B)={\frac {P(B\mid {\bar {A}})P({\bar {A}})}{P(B)}}}
etc. Bayes theorem visualisation.svg](http://upload.wikimedia.org/wikipedia/commons/thumb/b/bf/Bayes_theorem_visualisation.svg/330px-Bayes_theorem_visualisation.svg.png)












