Example of samples from two populations with the same mean but different variances. The red population has mean μ = 100 and variance σ = 100 (σ = 10), while the blue population has mean μ = 100 and variance σ = 2500 (σ = 50).
An advantage of variance as a measure of dispersion is that it is more amenable to algebraic manipulation than other measures of dispersion such as the expected absolute deviation; for example, the variance of a sum of uncorrelated random variables is equal to the sum of their variances. A disadvantage of the variance for practical applications is that, unlike the standard deviation, its units differ from the random variable, which is why the standard deviation is more commonly reported as a measure of dispersion once the calculation is finished. Another disadvantage is that the variance is not finite for many distributions.
There are two distinct concepts that are both called "variance". One, as discussed above, is part of a theoretical probability distribution and is defined by an equation. The other variance is a characteristic of a set of observations. When variance is calculated from observations, those observations are typically measured from a real-world system. If all possible observations of the system are present, then the calculated variance is called the population variance. Normally, however, only a subset is available, and the variance calculated from this is called the sample variance. The variance calculated from a sample is considered an estimate of the full population variance. There are multiple ways to estimate the population variance on the basis of the sample variance, as discussed in the section below.
The two kinds of variance are closely related. To see how, consider that a theoretical probability distribution can be used as a generator of hypothetical observations. If an infinite number of observations are generated using a distribution, then the sample variance calculated from that infinite set will match the value calculated using the distribution's equation for variance. Variance has a central role in statistics, where some ideas that use it include descriptive statistics, statistical inference, hypothesis testing, goodness of fit, and Monte Carlo sampling.
Geometric visualisation of the variance of an arbitrary distribution (2, 4, 4, 4, 5, 5, 7, 9):
A frequency distribution is constructed.
The centroid of the distribution gives its mean.
A square with sides equal to the difference of each value from the mean is formed for each value.
Arranging the squares into a rectangle with one side equal to the number of values, n, results in the other side being the distribution's variance, σ .
Definition
The variance of a random variable is the expected value of the squared deviation from the mean of , : This definition encompasses random variables that are generated by processes that are discrete, continuous, neither, or mixed. The variance can also be thought of as the covariance of a random variable with itself:
The variance is also equivalent to the second cumulant of a probability distribution that generates . The variance is typically designated as , or sometimes as or , or symbolically as or simply (pronounced "sigma squared"). The expression for the variance can be expanded as follows:
In other words, the variance of X is equal to the mean of the square of X minus the square of the mean of X. This equation should not be used for computations using floating-point arithmetic, because it suffers from catastrophic cancellation if the two components of the equation are similar in magnitude. For other numerically stable alternatives, see Algorithms for calculating variance.
Discrete random variable
If the generator of random variable is discrete with probability mass function, then where is the expected value. That is, (When such a discrete weighted variance is specified by weights whose sum is not1, then one divides by the sum of the weights.)
The variance of a collection of equally likely values can be written as where is the average value. That is,
The variance of a set of equally likely values can be equivalently expressed, without directly referring to the mean, in terms of squared deviations of all pairwise squared distances of points from each other:[2]
Using integration by parts and making use of the expected value already calculated, we have:
Thus, the variance of X is given by
Fair die
A fair six-sided die can be modeled as a discrete random variable, X, with outcomes 1 through 6, each with equal probability 1/6. The expected value of X is Therefore, the variance of X is
The general formula for the variance of the outcome, X, of an n-sided die is
Commonly used probability distributions
The following table lists the variance for some commonly used probability distributions.
Variance is non-negative because the squares are positive or zero:
The variance of a constant is zero.
Conversely, if the variance of a random variable is 0, then it is almost surely a constant. That is, it always has the same value:
Issues of finiteness
If a distribution does not have a finite expected value, as is the case for the Cauchy distribution, then the variance cannot be finite either. However, some distributions may not have a finite variance, despite their expected value being finite. An example is a Pareto distribution whose index satisfies
Decomposition
The general formula for variance decomposition or the law of total variance is: If and are two random variables, and the variance of exists, then
The conditional expectation of given , and the conditional variance may be understood as follows. Given any particular value y ofthe random variableY, there is a conditional expectation given the eventY=y. This quantity depends on the particular valuey; it is a function . That same function evaluated at the random variable Y is the conditional expectation .
In particular, if is a discrete random variable assuming possible values with corresponding probabilities , then in the formula for total variance, the first term on the right-hand side becomes where . Similarly, the second term on the right-hand side becomes where and . Thus the total variance is given by
A similar formula is applied in analysis of variance, where the corresponding formula is\ here refers to the Mean of the Squares. In linear regression analysis the corresponding formula is
This can also be derived from the additivity of variances, since the total (observed) score is the sum of the predicted score and the error score, where the latter two are uncorrelated.
Similar decompositions are possible for the sum of squared deviations (sum of squares, ):
Calculation from the CDF
The population variance for a non-negative random variable can be expressed in terms of the cumulative distribution functionF using
This expression can be used to calculate the variance in situations where the CDF, but not the density, can be conveniently expressed.
Characteristic property
The second moment of a random variable attains the minimum value when taken around the first moment (i.e., mean) of the random variable, i.e. . Conversely, if a continuous function satisfies for all random variables X, then it is necessarily of the form , where a > 0. This also holds in the multidimensional case.[3]
Units of measurement
Unlike the expected absolute deviation, the variance of a variable has units that are the square of the units of the variable itself. For example, a variable measured in meters will have a variance measured in meters squared. For this reason, describing data sets via their standard deviation or root mean square deviation is often preferred over using the variance. In the dice example the standard deviation is √2.9 ≈ 1.7, slightly larger than the expected absolute deviation of1.5.
The standard deviation and the expected absolute deviation can both be used as an indicator of the "spread" of a distribution. The standard deviation is more amenable to algebraic manipulation than the expected absolute deviation, and, together with variance and its generalization covariance, is used frequently in theoretical statistics; however the expected absolute deviation tends to be more robust as it is less sensitive to outliers arising from measurement anomalies or an unduly heavy-tailed distribution.
Propagation
Addition and multiplication by a constant
Variance is invariant with respect to changes in a location parameter. That is, if a constant is added to all values of the variable, the variance is unchanged:
If all values are scaled by a constant, the variance is scaled by the square of that constant:
The variance of a sum of two random variables is given by where is the covariance.
Linear combinations
In general, for the sum of random variables , the variance becomes: see also general Bienaymé's identity.
If the random variables are such that then they are said to be uncorrelated. It follows immediately from the expression given earlier that if the random variables are uncorrelated, then the variance of their sum is equal to the sum of their variances, or, expressed symbolically:
Since independent random variables are always uncorrelated (see Covariance §Uncorrelatedness and independence), the equation above holds in particular when the random variables are independent. Thus, independence is sufficient but not necessary for the variance of the sum to equal the sum of the variances.
Matrix notation for the variance of a linear combination
Define as a column vector of random variables , and as a column vector of scalars . Therefore, is a linear combination of these random variables, where denotes the transpose of . Also let be the covariance matrix of . The variance of is then given by:[4]
This implies that the variance of the mean can be written as (with a column vector of ones)
One reason for the use of the variance in preference to other measures of dispersion is that the variance of the sum (or the difference) of uncorrelated random variables is the sum of their variances:
This statement is called the Bienaymé formula[5] and was discovered in 1853.[6][7] It is often made with the stronger condition that the variables are independent, but being uncorrelated suffices. So if all the variables have the same variance σ2, then, since division by n is a linear transformation, this formula immediately implies that the variance of their mean is
That is, the variance of the mean decreases when n increases. This formula for the variance of the mean is used in the definition of the standard error of the sample mean, which is used in the central limit theorem.
To prove the initial statement, it suffices to show that
The general result then follows by induction. Starting with the definition,
Using the linearity of the expectation operator and the assumption of independence (or uncorrelatedness) of X and Y, this further simplifies as follows:
Sum of correlated variables
Sum of correlated variables with fixed sample size
In general, the variance of the sum of n variables is the sum of their covariances: (Note: The second equality comes from the fact that Cov(Xi, Xi) = Var(Xi).)
Here, is the covariance, which is zero for independent random variables (if it exists). The formula states that the variance of a sum is equal to the sum of all elements in the covariance matrix of the components. The next expression states equivalently that the variance of the sum is the sum of the diagonal of covariance matrix plus two times the sum of its upper triangular elements (or its lower triangular elements); this emphasizes that the covariance matrix is symmetric. This formula is used in the theory of Cronbach's alpha in classical test theory.
So, if the variables have equal variance σ2 and the average correlation of distinct variables is ρ, then the variance of their mean is
This implies that the variance of the mean increases with the average of the correlations. In other words, additional correlated observations are not as effective as additional independent observations at reducing the uncertainty of the mean. Moreover, if the variables have unit variance, for example if they are standardized, then this simplifies to
This formula is used in the Spearman–Brown prediction formula of classical test theory. This converges to ρ if n goes to infinity, provided that the average correlation remains constant or converges too. So for the variance of the mean of standardized variables with equal correlations or converging average correlation we have
Therefore, the variance of the mean of a large number of standardized variables is approximately equal to their average correlation. This makes clear that the sample mean of correlated variables does not generally converge to the population mean, even though the law of large numbers states that the sample mean will converge for independent variables.
Sum of uncorrelated variables with random sample size
There are cases when a sample is taken without knowing, in advance, how many observations will be acceptable according to some criterion. In such cases, the sample size N is a random variable whose variation adds to the variation of X, such that,[8] which follows from the law of total variance.
The scaling property and the Bienaymé formula, along with the property of the covarianceCov(aX,bY) = ab Cov(X,Y) jointly imply that
This implies that in a weighted sum of variables, the variable with the largest weight will have a disproportionally large weight in the variance of the total. For example, if X and Y are uncorrelated and the weight of X is two times the weight of Y, then the weight of the variance of X will be four times the weight of the variance of Y.
The expression above can be extended to a weighted sum of multiple variables:
Product of variables
Product of independent variables
If two variables X and Y are independent, the variance of their product is given by[9]
Equivalently, using the basic properties of expectation, it is given by
Product of statistically dependent variables
In general, if two variables are statistically dependent, then the variance of their product is given by:
Real-world observations such as the measurements of yesterday's rain throughout the day typically cannot be complete sets of all possible observations that could be made. As such, the variance calculated from the finite set will in general not match the variance that would have been calculated from the full population of possible observations. This means that one estimates the mean and variance from a limited set of observations by using an estimator equation. The estimator is a function of the sample of nobservations drawn without observational bias from the whole population of potential observations. In this example, the sample would be the set of actual measurements of yesterday's rainfall from available rain gauges within the geography of interest.
The simplest estimators for population mean and population variance are simply the mean and variance of the sample, the sample mean and (uncorrected) sample variance – these are consistent estimators (they converge to the value of the whole population as the number of samples increases) but can be improved. Most simply, the sample variance is computed as the sum of squared deviations about the (sample) mean, divided by n as the number of samples. However, using values other than n improves the estimator in various ways. Four common values for the denominator are n, n − 1, n + 1, and n − 1.5: n is the simplest (the variance of the sample), n − 1 eliminates bias,[10]n + 1 minimizes mean squared error for the normal distribution,[11] and n − 1.5 mostly eliminates bias in unbiased estimation of standard deviation for the normal distribution.[12]
Firstly, if the true population mean is unknown, then the sample variance (which uses the sample mean in place of the true mean) is a biased estimator: it underestimates the variance by a factor of (n − 1) / n; correcting this factor, resulting in the sum of squared deviations about the sample mean divided by n − 1 instead of n, is called Bessel's correction.[10] The resulting estimator is unbiased and is called the (corrected) sample variance or unbiased sample variance. If the mean is determined in some other way than from the same samples used to estimate the variance, then this bias does not arise, and the variance can safely be estimated as that of the samples about the (independently known) mean.
Secondly, the sample variance does not generally minimize mean squared error between sample variance and population variance. Correcting for bias often makes this worse: one can always choose a scale factor that performs better than the corrected sample variance, though the optimal scale factor depends on the excess kurtosis of the population (see Mean squared error §Variance) and introduces bias. This always consists of scaling down the unbiased estimator (dividing by a number larger than n − 1) and is a simple example of a shrinkage estimator: one "shrinks" the unbiased estimator towards zero. For the normal distribution, dividing by n + 1 (instead of n − 1 or n) minimizes mean squared error.[11] The resulting estimator is biased, however, and is known as the biased sample variation.
Population variance
In general, the population variance of a finitepopulation of size N with values xi is given by where the population mean is and , where is the expectation value operator.
The population variance can also be computed using[13]
(The right side has duplicate terms in the sum while the middle side has only unique terms to sum.) This is true because
The population variance matches the variance of the generating probability distribution. In this sense, the concept of population can be extended to continuous random variables with infinite populations.
In many practical situations, the true variance of a population is not known a priori and must be computed somehow. When dealing with extremely large populations, it is not possible to count every object in the population, so the computation must be performed on a sample of the population.[14] This is generally referred to as sample variance or empirical variance. Sample variance can also be applied to the estimation of the variance of a continuous distribution from a sample of that distribution.
We take a sample with replacement of n values Y1, ..., Yn from the population of size N, where n < N, and estimate the variance on the basis of this sample.[15] Directly taking the variance of the sample data gives the average of the squared deviations:[16] (See the section §Population variance for the derivation of this formula.) Here, denotes the sample mean:
Since the Yi are selected randomly, both and are random variables. Their expected values can be evaluated by averaging over the ensemble of all possible samples {Yi} of size n from the population. For this gives:
Here derived in the section is population variance and due to independency of and .
Hence gives an estimate of the population variance that is biased by a factor of because the expectation value of is smaller than the population variance (true variance) by that factor. For this reason, is referred to as the biased sample variance.
Unbiased sample variance
Correcting for this bias yields the unbiased sample variance, denoted :
Either estimator may be simply referred to as the sample variance when the version can be determined by context. The same proof is also applicable for samples taken from a continuous probability distribution.
The use of the term n − 1 is called Bessel's correction, and it is also used in sample covariance and the sample standard deviation (the square root of variance). The square root is a concave function and thus introduces negative bias (by Jensen's inequality), which depends on the distribution, and thus the corrected sample standard deviation (using Bessel's correction) is biased. The unbiased estimation of standard deviation is a technically involved problem, though for the normal distribution using the term n − 1.5 yields an almost unbiased estimator.
The unbiased sample variance is a U-statistic for the function f(y1, y2) = (y1 − y2)2/2, meaning that it is obtained by averaging a 2-sample statistic over 2-element subsets of the population.
Example
For a set of numbers {10, 15, 30, 45, 57, 52, 63, 72, 81, 93, 102, 105}, if this set is the whole data population for some measurement, then variance is the population variance 932.743 as the sum of the squared deviations about the mean of this set, divided by 12 as the number of the set members. If the set is a sample from the whole population, then the unbiased sample variance can be calculated as 1017.538 that is the sum of the squared deviations about the mean of the sample, divided by 11 instead of 12. A function VAR.S in Microsoft Excel gives the unbiased sample variance while VAR.P is for population variance.
Distribution of the sample variance
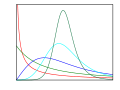
Distribution and cumulative distribution of S2/σ2, for various values of ν = n − 1, when the yi are independent normally distributed.
If Yi are independent and identically distributed, but not necessarily normally distributed, then[19] where κ is the kurtosis of the distribution and μ4 is the fourth central moment.
If the conditions of the law of large numbers hold for the squared observations, S2 is a consistent estimator ofσ2. One can see indeed that the variance of the estimator tends asymptotically to zero. An asymptotically equivalent formula was given in Kenney and Keeping (1951:164), Rose and Smith (2002:264), and Weisstein (n.d.).[20][21][22]
Samuelson's inequality
Samuelson's inequality is a result that states bounds on the values that individual observations in a sample can take, given that the sample mean and (biased) variance have been calculated.[23] Values must lie within the limits .
Relations with the harmonic and arithmetic means
It has been shown[24] that for a sample {yi} of positive real numbers, where ymax is the maximum of the sample, A is the arithmetic mean, H is the harmonic mean of the sample and is the (biased) variance of the sample.
This bound has been improved, and it is known that variance is bounded by where ymin is the minimum of the sample.[25]
Tests of equality of variances
The F-test of equality of variances and the chi square tests are adequate when the sample is normally distributed. Non-normality makes testing for the equality of two or more variances more difficult.
Several non parametric tests have been proposed: these include the Barton–David–Ansari–Freund–Siegel–Tukey test, the Capon test, Mood test, the Klotz test and the Sukhatme test. The Sukhatme test applies to two variances and requires that both medians be known and equal to zero. The Mood, Klotz, Capon and Barton–David–Ansari–Freund–Siegel–Tukey tests also apply to two variances. They allow the median to be unknown but do require that the two medians are equal.
The Lehmann test is a parametric test of two variances. Of this test there are several variants known. Other tests of the equality of variances include the Box test, the Box–Anderson test and the Moses test.
Resampling methods, which include the bootstrap and the jackknife, may be used to test the equality of variances.
The variance of a probability distribution is analogous to the moment of inertia in classical mechanics of a corresponding mass distribution along a line, with respect to rotation about its center of mass.[26] It is because of this analogy that such things as the variance are called moments of probability distributions.[26] The covariance matrix is related to the moment of inertia tensor for multivariate distributions. The moment of inertia of a cloud of n points with a covariance matrix of is given by[citation needed]
This difference between moment of inertia in physics and in statistics is clear for points that are gathered along a line. Suppose many points are close to the x axis and distributed along it. The covariance matrix might look like
That is, there is the most variance in the x direction. Physicists would consider this to have a low moment about the x axis so the moment-of-inertia tensor is
Semivariance
The semivariance is calculated in the same manner as the variance but only those observations that fall below the mean are included in the calculation: It is also described as a specific measure in different fields of application. For skewed distributions, the semivariance can provide additional information that a variance does not.[27]
The great body of available statistics show us that the deviations of a human measurement from its mean follow very closely the Normal Law of Errors, and, therefore, that the variability may be uniformly measured by the standard deviation corresponding to the square root of the mean square error. When there are two independent causes of variability capable of producing in an otherwise uniform population distributions with standard deviations and , it is found that the distribution, when both causes act together, has a standard deviation . It is therefore desirable in analysing the causes of variability to deal with the square of the standard deviation as the measure of variability. We shall term this quantity the Variance...
Generalizations
For complex variables
If is a scalar complex-valued random variable, with values in , then its variance is , where is the complex conjugate of . This variance is a real scalar.
For vector-valued random variables
As a matrix
If is a vector-valued random variable, with values in and thought of as a column vector, then a natural generalization of variance is where and is the transpose of X, and so is a row vector. The result is a positive semi-definite square matrix, commonly referred to as the variance-covariance matrix (or simply as the covariance matrix).
Another generalization of variance for vector-valued random variables , which results in a scalar value rather than in a matrix, is the generalized variance, the determinant of the covariance matrix. The generalized variance can be shown to be related to the multidimensional scatter of points around their mean.[29]
A different generalization is obtained by considering the equation for the scalar variance, , and reinterpreting as the squared Euclidean distance between the random variable and its mean, or, simply as the scalar product of the vector with itself. This results in which is the trace of the covariance matrix.
↑Wasserman, Larry (2005). All of Statistics: a concise course in statistical inference. Springer texts in statistics. p.51. ISBN978-1-4419-2322-6.
↑Yuli Zhang; Huaiyu Wu; Lei Cheng (June 2012). Some new deformation formulas about variance and covariance. Proceedings of 4th International Conference on Modelling, Identification and Control(ICMIC2012). pp.987–992.
↑Kagan, A.; Shepp, L. A. (1998). "Why the variance?". Statistics & Probability Letters. 38 (4): 329–333. doi:10.1016/S0167-7152(98)00041-8.
↑Loève, M. (1977) "Probability Theory", Graduate Texts in Mathematics, Volume 45, 4th edition, Springer-Verlag, p.12.
↑Bienaymé, I.-J. (1853) "Considérations à l'appui de la découverte de Laplace sur la loi de probabilité dans la méthode des moindres carrés", Comptes rendus de l'Académie des sciences Paris, 37, p.309–317; digital copy available Archived 2018-06-23 at the Wayback Machine
↑Bienaymé, I.-J. (1867) "Considérations à l'appui de la découverte de Laplace sur la loi de probabilité dans la méthode des moindres carrés", Journal de Mathématiques Pures et Appliquées, Série 2, Tome 12, p.158–167; digital copy available
↑Cornell, J R, and Benjamin, C A, Probability, Statistics, and Decisions for Civil Engineers, McGraw-Hill, NY, 1970, pp. 178-9.
↑Brugger, R. M. (1969). "A Note on Unbiased Estimation of the Standard Deviation". The American Statistician. 23 (4): 32. doi:10.1080/00031305.1969.10481865.
↑Yuli Zhang; Huaiyu Wu; Lei Cheng (June 2012). Some new deformation formulas about variance and covariance. Proceedings of 4th International Conference on Modelling, Identification and Control(ICMIC2012). pp.987–992.
↑Navidi, William (2006). Statistics for Engineers and Scientists. McGraw-Hill. p.14.
↑Montgomery, D. C. and Runger, G. C. (1994) Applied statistics and probability for engineers, page 201. John Wiley & Sons New York
↑Yuli Zhang; Huaiyu Wu; Lei Cheng (June 2012). Some new deformation formulas about variance and covariance. Proceedings of 4th International Conference on Modelling, Identification and Control(ICMIC2012). pp.987–992.
↑Knight, K. (2000). Mathematical Statistics. New York: Chapman and Hall. proposition 2.11.
↑Casella, George; Berger, Roger L. (2002). Statistical Inference (2nded.). Example 7.3.3, p.331. ISBN0-534-24312-6.
↑Mood, A. M., Graybill, F. A., and Boes, D.C. (1974) Introduction to the Theory of Statistics, 3rd Edition, McGraw-Hill, New York, p. 229
↑Kenney, John F.; Keeping, E.S. (1951). Mathematics of Statistics. Part Two(PDF) (2nded.). Princeton, New Jersey: D. Van Nostrand Company, Inc. Archived from the original(PDF) on Nov 17, 2018 – via KrishiKosh.
↑Sharma, R. (2008). "Some more inequalities for arithmetic mean, harmonic mean and variance". Journal of Mathematical Inequalities. 2 (1): 109–114. CiteSeerX10.1.1.551.9397. doi:10.7153/jmi-02-11.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.