In probability theory and statistics, a central moment is a moment of a probability distribution of a random variable about the random variable's mean; that is, it is the expected value of a specified integer power of the deviation of the random variable from the mean. The various moments form one set of values by which the properties of a probability distribution can be usefully characterized. Central moments are used in preference to ordinary moments, computed in terms of deviations from the mean instead of from zero, because the higher-order central moments relate only to the spread and shape of the distribution, rather than also to its location.

A random variable is a mathematical formalization of a quantity or object which depends on random events. The term 'random variable' in its mathematical definition refers to neither randomness nor variability but instead is a mathematical function in which

In probability theory, a probability density function (PDF), density function, or density of an absolutely continuous random variable, is a function whose value at any given sample in the sample space can be interpreted as providing a relative likelihood that the value of the random variable would be equal to that sample. Probability density is the probability per unit length, in other words, while the absolute likelihood for a continuous random variable to take on any particular value is 0, the value of the PDF at two different samples can be used to infer, in any particular draw of the random variable, how much more likely it is that the random variable would be close to one sample compared to the other sample.
A likelihood function measures how well a statistical model explains observed data by calculating the probability of seeing that data under different parameter values of the model. It is constructed from the joint probability distribution of the random variable that (presumably) generated the observations. When evaluated on the actual data points, it becomes a function solely of the model parameters.

In probability theory and statistics, the geometric distribution is either one of two discrete probability distributions:

In probability theory and statistics, the zeta distribution is a discrete probability distribution. If X is a zeta-distributed random variable with parameter s, then the probability that X takes the positive integer value k is given by the probability mass function
In probability theory and statistics, the moment-generating function of a real-valued random variable is an alternative specification of its probability distribution. Thus, it provides the basis of an alternative route to analytical results compared with working directly with probability density functions or cumulative distribution functions. There are particularly simple results for the moment-generating functions of distributions defined by the weighted sums of random variables. However, not all random variables have moment-generating functions.
In probability theory, the probability generating function of a discrete random variable is a power series representation (the generating function) of the probability mass function of the random variable. Probability generating functions are often employed for their succinct description of the sequence of probabilities Pr(X = i) in the probability mass function for a random variable X, and to make available the well-developed theory of power series with non-negative coefficients.
In probability and statistics, an exponential family is a parametric set of probability distributions of a certain form, specified below. This special form is chosen for mathematical convenience, including the enabling of the user to calculate expectations, covariances using differentiation based on some useful algebraic properties, as well as for generality, as exponential families are in a sense very natural sets of distributions to consider. The term exponential class is sometimes used in place of "exponential family", or the older term Koopman–Darmois family. Sometimes loosely referred to as "the" exponential family, this class of distributions is distinct because they all possess a variety of desirable properties, most importantly the existence of a sufficient statistic.
In probability theory and statistics, the cumulantsκn of a probability distribution are a set of quantities that provide an alternative to the moments of the distribution. Any two probability distributions whose moments are identical will have identical cumulants as well, and vice versa.
In mathematics, the moments of a function are certain quantitative measures related to the shape of the function's graph. If the function represents mass density, then the zeroth moment is the total mass, the first moment is the center of mass, and the second moment is the moment of inertia. If the function is a probability distribution, then the first moment is the expected value, the second central moment is the variance, the third standardized moment is the skewness, and the fourth standardized moment is the kurtosis.
In numerical analysis and computational statistics, rejection sampling is a basic technique used to generate observations from a distribution. It is also commonly called the acceptance-rejection method or "accept-reject algorithm" and is a type of exact simulation method. The method works for any distribution in with a density.
In probability theory, a Chernoff bound is an exponentially decreasing upper bound on the tail of a random variable based on its moment generating function. The minimum of all such exponential bounds forms the Chernoff or Chernoff-Cramér bound, which may decay faster than exponential. It is especially useful for sums of independent random variables, such as sums of Bernoulli random variables.
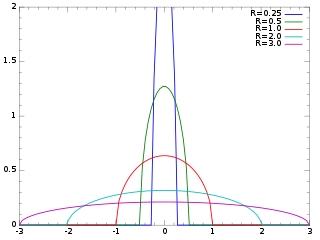
The Wigner semicircle distribution, named after the physicist Eugene Wigner, is the probability distribution defined on the domain [−R, R] whose probability density function f is a scaled semicircle, i.e. a semi-ellipse, centered at :

In probability theory and statistics, the characteristic function of any real-valued random variable completely defines its probability distribution. If a random variable admits a probability density function, then the characteristic function is the Fourier transform of the probability density function. Thus it provides an alternative route to analytical results compared with working directly with probability density functions or cumulative distribution functions. There are particularly simple results for the characteristic functions of distributions defined by the weighted sums of random variables.
Differential entropy is a concept in information theory that began as an attempt by Claude Shannon to extend the idea of (Shannon) entropy of a random variable, to continuous probability distributions. Unfortunately, Shannon did not derive this formula, and rather just assumed it was the correct continuous analogue of discrete entropy, but it is not. The actual continuous version of discrete entropy is the limiting density of discrete points (LDDP). Differential entropy is commonly encountered in the literature, but it is a limiting case of the LDDP, and one that loses its fundamental association with discrete entropy.
In probability theory and statistics, the factorial moment generating function (FMGF) of the probability distribution of a real-valued random variable X is defined as
In statistical mechanics, the mean squared displacement is a measure of the deviation of the position of a particle with respect to a reference position over time. It is the most common measure of the spatial extent of random motion, and can be thought of as measuring the portion of the system "explored" by the random walker. In the realm of biophysics and environmental engineering, the Mean Squared Displacement is measured over time to determine if a particle is spreading slowly due to diffusion, or if an advective force is also contributing. Another relevant concept, the variance-related diameter, is also used in studying the transportation and mixing phenomena in the realm of environmental engineering. It prominently appears in the Debye–Waller factor and in the Langevin equation.

In probability theory and statistics, the Hermite distribution, named after Charles Hermite, is a discrete probability distribution used to model count data with more than one parameter. This distribution is flexible in terms of its ability to allow a moderate over-dispersion in the data.
Cramér's theorem is a fundamental result in the theory of large deviations, a subdiscipline of probability theory. It determines the rate function of a series of iid random variables. A weak version of this result was first shown by Harald Cramér in 1938.



