
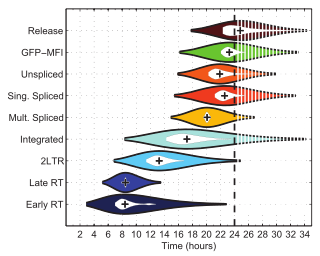
A violin plot (also known as a bean plot) is a statistical graphic for comparing probability distributions. It is similar to a box plot, but has enhanced information with the addition of a rotated kernel density plot on each side. [1]
A violin plot (also known as a bean plot) is a statistical graphic for comparing probability distributions. It is similar to a box plot, but has enhanced information with the addition of a rotated kernel density plot on each side. [1]
The violin plot was proposed in 1997 by Jerry L. Hintze and Ray D. Nelson as a way to display even more information than box plots, which were created by John Tukey in 1977. [2] The name comes from the plot's alleged resemblance to a violin. [2]
Violin plots are similar to box plots, except that they also show the probability density of the data at different values, usually smoothed by a kernel density estimator. A violin plot will include all the data that is in a box plot: a marker for the median of the data; a box or marker indicating the interquartile range; and possibly all sample points, if the number of samples is not too high.
While a box plot shows a summary statistics such as mean/median and interquartile ranges, the violin plot shows the full distribution of the data. The violin plot can be used in multimodal data (more than one peak). In this case a violin plot shows the presence of different peaks, their position and relative amplitude.
Like box plots, violin plots are used to represent comparison of a variable distribution (or sample distribution) across different "categories" (for example, temperature distribution compared between day and night, or distribution of car prices compared across different car makers).
A violin plot can have multiple layers. For instance, the outer shape represents all possible results. The next layer inside might represent the values that occur 95% of the time. The next layer (if it exists) inside might represent the values that occur 50% of the time.
Violin plots are less popular than box plots. Violin plots may be harder to understand for readers not familiar with them. In this case, a more accessible alternative is to plot a series of stacked histograms or kernel density plots.
The original meaning of "violin plot" was a combination of a box plot and a two-sided kernel density plot. [1] However, currently "violin plots" are sometimes understood just as two-sided kernel density plots, without a box plot or any other elements. [3] [4]
![]() This article incorporates public domain material from Dataplot reference manual: Violin plot. National Institute of Standards and Technology.
This article incorporates public domain material from Dataplot reference manual: Violin plot. National Institute of Standards and Technology.