A mixed model, mixed-effects model or mixed error-component model is a statistical model containing both fixed effects and random effects.[1][2] These models are useful in a wide variety of disciplines in the physical, biological and social sciences. They are particularly useful in settings where repeated measurements are made on the same statistical units (see also longitudinal study), or where measurements are made on clusters of related statistical units.[2] Mixed models are often preferred over traditional analysis of variance regression models because they don't rely on the independent observations assumption. Further, they have their flexibility in dealing with missing values and uneven spacing of repeated measurements.[3] The Mixed model analysis allows measurements to be explicitly modeled in a wider variety of correlation and variance-covarianceavoiding biased estimations structures.
Non-independent sets are ones in which the variability between outcomes is due to correlations within groups or between groups. Mixed models properly account for nested structures/hierarchical data structures where observations are influenced by their nested associations. For example, when studying education methods involving multiple schools, there are multiple levels of variables to consider. The individual level/lower level comprises individual students or teachers within the school. The observations obtained from this student/teacher is nested within their school. For example, Student A is a unit within the School A. The next higher level is the school. At the higher level, the school contains multiple individual students and teachers. The school level influences the observations obtained from the students and teachers. For Example, School A and School B are the higher levels each with its set of Student A and Student B respectively. This represents a hierarchical data scheme. A solution to modeling hierarchical data is using linear mixed models.
Representation of how data, related to education system, is non-independent and structured in nested/hierarchical levels.
LMMs allow us to understand the important effects between and within levels while incorporating the corrections for standard errors for non-independence embedded in the data structure.[4][5] In experimental fields such as social psychology, psycholinguistics, cognitive psychology (and neuroscience), where studies often involve multiple grouping variables, failing to account for random effects can lead to inflated Type I error rates and unreliable conclusions.[6][7] For instance, when analyzing data from experiments that involve both samples of participants and samples of stimuli (e.g., images, scenarios, etc.), ignoring variation in either of these grouping variables (e.g., by averaging over stimuli) can result in misleading conclusions. In such cases, researchers can instead treat both participant and stimulus as random effects with LMMs, and in doing so, can correctly account for the variation in their data across multiple grouping variables. Similarly, when analyzing data from comparative longitudinal surveys, failing to include random effects at all relevant levels—such as country and country-year—can significantly distort the results.[8]
The Fixed Effect
Fixed effects encapsulate the tendencies/trends that are consistent at the levels of primary interest. These effects are considered fixed because they are non-random and assumed to be constant for the population being studied.[5] For example, when studying education a fixed effect could represent overall school level effects that are consistent across all schools.
While the hierarchy of the data set is typically obvious, the specific fixed effects that affect the average responses for all subjects must be specified. Some fixed effect coefficients are sufficient without corresponding random effects where as other fixed coefficients only represent an average where the individual units are random. These may be determined by incorporating random intercepts and slopes.[9][10][11]
In most situations, several related models are considered and the model that best represents a universal model is adopted.
The Random Effect, ε
A key component of the mixed model is the incorporation of random effects with the fixed effect. Fixed effects are often fitted to represent the underlying model. In Linear mixed models, the true regression of the population is linear, β. The fixed data is fitted at the highest level. Random effects introduce statistical variability at different levels of the data hierarchy. These account for the unmeasured sources of variance that affect certain groups in the data. For example, the differences between student 1 and student 2 in the same class, or the differences between class 1 and class 2 in the same school.[9][10][11]
History and current status
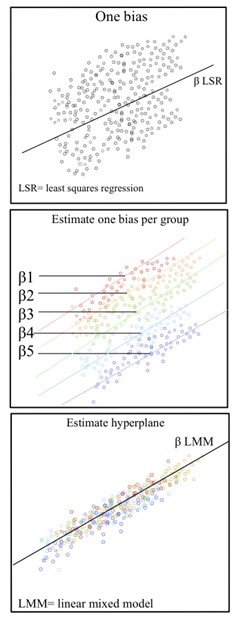
Representation of biased vs. unbiased data and the differences between fitted estimates using least squares regression (LSR) and a linear mixed model (LMM).
Ronald Fisher introduced random effects models to study the correlations of trait values between relatives.[12] In the 1950s, Charles Roy Henderson provided best linear unbiased estimates of fixed effects and best linear unbiased predictions of random effects.[13][14][15][16] Subsequently, mixed modeling has become a major area of statistical research, including work on computation of maximum likelihood estimates, non-linear mixed effects models, missing data in mixed effects models, and Bayesian estimation of mixed effects models. Mixed models are applied in many disciplines where multiple correlated measurements are made on each unit of interest. They are prominently used in research involving human and animal subjects in fields ranging from genetics to marketing, and have also been used in baseball [17] and industrial statistics.[18] The mixed linear model association has improved the prevention of false positive associations. Populations are deeply interconnected and the relatedness structure of population dynamics is extremely difficult to model without the use of mixed models. Linear mixed models may not, however, be the only solution. LMM's have a constant-residualvariance assumption that is sometimes violated when accounting for deeply associated continuous and binary traits.[19]
Definition
In matrix notation a linear mixed model can be represented as
is an unknown vector of random errors, with mean and variance ;
is the known design matrix for the fixed effects relating the observations to , respectively
is the known design matrix for the random effects relating the observations to , respectively.
For example, if each observation can belong to any zero or more of k categories then Z, which has one row per observation, can be chosen to have k columns, where a value of 1 for a matrix element of Z indicates that an observation is known to belong to a category and a value of 0 indicates that an observation is known to not belong to a category. The inferred value of u for a category is then a category-specific intercept. If Z has additional columns, where the non-zero values are instead the value of an independent variable for an observation, then the corresponding inferred value of u is a category-specific slope for that independent variable. The prior distribution for the category intercepts and slopes is described by the covariance matrix G.
Estimation
The joint density of and can be written as: . Assuming normality, , and , and maximizing the joint density over and , gives Henderson's "mixed model equations" (MME) for linear mixed models:[13][15][20]
The solutions to the MME, and are best linear unbiased estimates and predictors for and , respectively. This is a consequence of the Gauss–Markov theorem when the conditional variance of the outcome is not scalable to the identity matrix. When the conditional variance is known, then the inverse variance weighted least squares estimate is best linear unbiased estimates. However, the conditional variance is rarely, if ever, known. So it is desirable to jointly estimate the variance and weighted parameter estimates when solving MMEs.
Choice of random effects structure
One choice that analysts face with mixed models is which random effects (i.e., grouping variables, random intercepts, and random slopes) to include. One prominent recommendation in the context of confirmatory hypothesis testing[21] is to adopt a "maximal" random effects structure, including all possible random effects justified by the experimental design, as a means to control Type I error rates.
Software
One method used to fit such mixed models is that of the expectation–maximization algorithm (EM) where the variance components are treated as unobserved nuisance parameters in the joint likelihood.[22] Currently, this is the method implemented in statistical software such as Python (statsmodels package) and as initial step only in R's nlme package lme(). The solution to the mixed model equations is a maximum likelihood estimate when the distribution of the errors is normal.[23][24]
Fixed, mixed, and random effects influence linear regression models.
There are several other methods to fit mixed models, including using a mixed effect model (MEM) initially, and then Newton-Raphson (used by R package nlme[25]'s lme(), SAS MIXED, and SPSS MIXED), penalized least squares to get a profiled log likelihood only depending on the (low-dimensional) variance-covariance parameters of , i.e., its cov matrix , and then modern direct optimization for that reduced objective function (used by R's lme4[26] package lmer() and the Julia package MixedModels.jl) and direct optimization of the likelihood (used by e.g. R's glmmTMB). Notably, while the canonical form proposed by Henderson is useful for theory, many popular software packages use a different formulation for numerical computation in order to take advantage of sparse matrix methods (e.g. lme4 and MixedModels.jl).
In the context of Bayesian methods, the brms package provides a user-friendly interface for fitting mixed models in R using Stan, allowing for the incorporation of prior distributions and the estimation of posterior distributions.[27][28] In python, Bambi provides a similarly streamlined approach for fitting mixed effects models using PyMC.[29]
↑Judd, Charles M.; Westfall, Jacob; Kenny, David A. (2012). "Treating stimuli as a random factor in social psychology: A new and comprehensive solution to a pervasive but largely ignored problem". Journal of Personality and Social Psychology. 103 (1): 54–69. doi:10.1037/a0028347. PMID22612667.
↑Schmidt-Catran, Alexander W.; Fairbrother, Malcolm (February 2016). "The Random Effects in Multilevel Models: Getting Them Wrong and Getting Them Right". European Sociological Review. 32 (1): 23–38. doi:10.1093/esr/jcv090. hdl:1983/de3e0a3c-9b41-4963-880c-452809860a7e.
12Kreft & de Leeuw, J. Introducing multilevel modeling. London:Sage.{{cite book}}: CS1 maint: publisher location (link)
12Raudenbush, Bryk, S.W, A.S (2002). Hierarchical Linear Models: Applications and Data Analysis Methods. Thousand Oaks, CA: Sage.{{cite book}}: CS1 maint: multiple names: authors list (link)
12Snijders, Bosker, T.A.B, R.J (2012). Multilevel analysis: An introduction to basic and advanced multilevel modeling. Vol.2nd edition. London:Sage.{{cite book}}: CS1 maint: multiple names: authors list (link) CS1 maint: publisher location (link)
↑C. R. Henderson; Oscar Kempthorne; S. R. Searle; C. M. von Krosigk (1959). "The Estimation of Environmental and Genetic Trends from Records Subject to Culling". Biometrics. 15 (2). International Biometric Society: 192–218. doi:10.2307/2527669. JSTOR2527669.
↑McLean, Robert A.; Sanders, William L.; Stroup, Walter W. (1991). "A Unified Approach to Mixed Linear Models". The American Statistician. 45 (1). American Statistical Association: 54–64. doi:10.2307/2685241. JSTOR2685241.
↑Lindstrom, ML; Bates, DM (1988). "Newton–Raphson and EM algorithms for linear mixed-effects models for repeated-measures data". Journal of the American Statistical Association. 83 (404): 1014–1021. doi:10.1080/01621459.1988.10478693.
↑Laird, Nan M.; Ware, James H. (1982). "Random-Effects Models for Longitudinal Data". Biometrics. 38 (4). International Biometric Society: 963–974. doi:10.2307/2529876. JSTOR2529876. PMID7168798.
↑Fitzmaurice, Garrett M.; Laird, Nan M.; Ware, James H. (2004). Applied Longitudinal Analysis. John Wiley & Sons. pp.326–328.
↑Pinheiro, J; Bates, DM (2006). Mixed-effects models in S and S-PLUS. Statistics and Computing. New York: Springer Science & Business Media. doi:10.1007/b98882. ISBN0-387-98957-9.
↑Bürkner, Paul-Christian (2018). "Advanced Bayesian Multilevel Modeling with the R Package brms". The R Journal. 10 (1): 395. arXiv:1705.11123. doi:10.32614/RJ-2018-017.
↑Capretto, Tomás; Piho, Camen; Kumar, Ravin; Westfall, Jacob; Yarkoni, Tal; Martin, Osvaldo A. (2020). "Bambi: A simple interface for fitting Bayesian linear models in Python". arXiv:2012.10754 [stat.CO].
Further reading
Gałecki, Andrzej; Burzykowski, Tomasz (2013). Linear Mixed-Effects Models Using R: A Step-by-Step Approach. New York: Springer. ISBN978-1-4614-3900-4.
Milliken, G. A.; Johnson, D. E. (1992). Analysis of Messy Data: Vol. I. Designed Experiments. New York: Chapman & Hall.
West, B. T.; Welch, K. B.; Galecki, A. T. (2007). Linear Mixed Models: A Practical Guide Using Statistical Software. New York: Chapman & Hall/CRC.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.