Linear regression is also a type of machine learningalgorithm, more specifically a supervised algorithm, that learns from the labelled datasets and maps the data points to the most optimized linear functions that can be used for prediction on new datasets.[3]
Linear regression was the first type of regression analysis to be studied rigorously, and to be used extensively in practical applications.[4] This is because models which depend linearly on their unknown parameters are easier to fit than models which are non-linearly related to their parameters and because the statistical properties of the resulting estimators are easier to determine.
Linear regression has many practical uses. Most applications fall into one of the following two broad categories:
If the goal is to reduce error, i.e. variance in prediction or forecasting, linear regression can be used to fit a predictive model to an observed data set of values of the response and explanatory variables. After developing such a model, if additional values of the explanatory variables are collected without an accompanying response value, the fitted model can be used to make a prediction of the response.
If the goal is to explain variation in the response variable that can be attributed to variation in the explanatory variables, linear regression analysis can be applied to quantify the strength of the relationship between the response and the explanatory variables, and in particular to determine whether some explanatory variables may have no linear relationship with the response at all, or to identify which subsets of explanatory variables may contain redundant information about the response.
Linear regression models are often fitted using the least squares approach, but they may also be fitted in other ways, such as by minimizing the "lack of fit" in some other norm (as with least absolute deviations regression), or by minimizing a penalized version of the least squares cost function as in ridge regression (L2-norm penalty) and lasso (L1-norm penalty). Use of the Mean Squared Error (MSE) as the cost on a dataset that has many large outliers, can result in a model that fits the outliers more than the true data due to the higher importance assigned by MSE to large errors. So, cost functions that are robust to outliers should be used if the dataset has many large outliers. Conversely, the least squares approach can be used to fit models that are not linear models. Thus, although the terms "least squares" and "linear model" are closely linked, they are not synonymous.
Formulation
In linear regression, the observations (red) are assumed to be the result of random deviations (green) from an underlying relationship (blue) between a dependent variable (y) and an independent variable (x).
Given a data set of nstatistical units, a linear regression model assumes that the relationship between the dependent variable y and the vector of regressors x is linear. This relationship is modeled through a disturbance term or error variableε—an unobserved random variable that adds "noise" to the linear relationship between the dependent variable and regressors. Thus the model takes the formwhere T denotes the transpose, so that xiTβ is the inner product between vectorsxi and β.
Often these n equations are stacked together and written in matrix notation as
where
Notation and terminology
is a vector of observed values of the variable called the regressand, endogenous variable, response variable, target variable, measured variable, criterion variable, or dependent variable. This variable is also sometimes known as the predicted variable, but this should not be confused with predicted values, which are denoted . The decision as to which variable in a data set is modeled as the dependent variable and which are modeled as the independent variables may be based on a presumption that the value of one of the variables is caused by, or directly influenced by the other variables. Alternatively, there may be an operational reason to model one of the variables in terms of the others, in which case there need be no presumption of causality.
Usually a constant is included as one of the regressors. In particular, for . The corresponding element of β is called the intercept. Many statistical inference procedures for linear models require an intercept to be present, so it is often included even if theoretical considerations suggest that its value should be zero.
Sometimes one of the regressors can be a non-linear function of another regressor or of the data values, as in polynomial regression and segmented regression. The model remains linear as long as it is linear in the parameter vector β.
The values xij may be viewed as either observed values of random variablesXj or as fixed values chosen prior to observing the dependent variable. Both interpretations may be appropriate in different cases, and they generally lead to the same estimation procedures; however different approaches to asymptotic analysis are used in these two situations.
is a -dimensional parameter vector, where is the intercept term (if one is included in the model—otherwise is p-dimensional). Its elements are known as effects or regression coefficients (although the latter term is sometimes reserved for the estimated effects). In simple linear regression, p=1, and the coefficient is known as regression slope. Statistical estimation and inference in linear regression focuses on β. The elements of this parameter vector are interpreted as the partial derivatives of the dependent variable with respect to the various independent variables.
is a vector of values . This part of the model is called the error term, disturbance term, or sometimes noise (in contrast with the "signal" provided by the rest of the model). This variable captures all other factors which influence the dependent variable y other than the regressors x. The relationship between the error term and the regressors, for example their correlation, is a crucial consideration in formulating a linear regression model, as it will determine the appropriate estimation method.
Fitting a linear model to a given data set usually requires estimating the regression coefficients such that the error term is minimized. For example, it is common to use the sum of squared errors as a measure of for minimization.
Example
Consider a situation where a small ball is being tossed up in the air and then we measure its heights of ascent hi at various moments in time ti. Physics tells us that, ignoring the drag, the relationship can be modeled as
where β1 determines the initial velocity of the ball, β2 is proportional to the standard gravity, and εi is due to measurement errors. Linear regression can be used to estimate the values of β1 and β2 from the measured data. This model is non-linear in the time variable, but it is linear in the parameters β1 and β2; if we take regressors xi=(xi1, xi2) =(ti, ti2), the model takes on the standard form
When estimating the parameters of linear regression models with standard estimation techniques such as ordinary least squares, it is necessary to make a number of assumptions about the predictor variables, the response variable and their relationship, to get estimators that are unbiased in finite sample. Numerous extensions have been developed that allow each of these assumptions to be relaxed (reduced to a weaker form), and in some cases eliminated entirely. Generally these extensions require more data or modelling assumptions to produce an equally precise model[5].
Interpretation
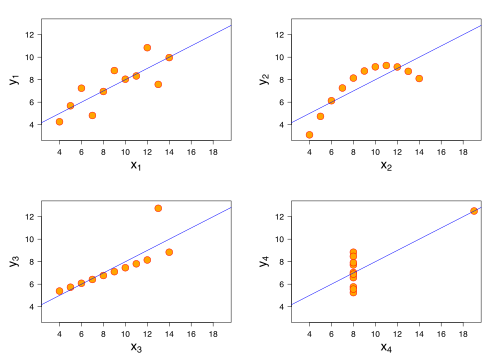
The data sets in the Anscombe's quartet are designed to have approximately the same linear regression line (as well as nearly identical means, standard deviations, and correlations) but are graphically very different. This illustrates the pitfalls of relying solely on a fitted model to understand the relationship between variables.
A fitted linear regression model can be used to identify the relationship between a single predictor variable xj and the response variable y when all the other predictor variables in the model are "held fixed". Specifically, the interpretation of βj is the expected change in y for a one-unit change in xj when the other covariates are held fixed—that is, the expected value of the partial derivative of y with respect to xj. This is sometimes called the unique effect of xj on y. In contrast, the marginal effect of xj on y can be assessed using a correlation coefficient or simple linear regression model relating only xj to y; this effect is the total derivative of y with respect to xj.
Care must be taken when interpreting regression results, as some of the regressors may not allow for marginal changes (such as dummy variables, or the intercept term), while others cannot be held fixed (recall the example from the introduction: it would be impossible to "hold ti fixed" and at the same time change the value of ti2).
It is possible that the unique effect be nearly zero even when the marginal effect is large. This may imply that some other covariate captures all the information in xj, so that once that variable is in the model, there is no contribution of xj to the variation in y. Conversely, the unique effect of xj can be large while its marginal effect is nearly zero. This would happen if the other covariates explained a great deal of the variation of y, but they mainly explain variation in a way that is complementary to what is captured by xj. In this case, including the other variables in the model reduces the part of the variability of y that is unrelated to xj, thereby strengthening the apparent relationship with xj.
The meaning of the expression "held fixed" may depend on how the values of the predictor variables arise. If the experimenter directly sets the values of the predictor variables according to a study design, the comparisons of interest may literally correspond to comparisons among units whose predictor variables have been "held fixed" by the experimenter. Alternatively, the expression "held fixed" can refer to a selection that takes place in the context of data analysis. In this case, we "hold a variable fixed" by restricting our attention to the subsets of the data that happen to have a common value for the given predictor variable. This is the only interpretation of "held fixed" that can be used in an observational study.
The notion of a "unique effect" is appealing when studying a complex system where multiple interrelated components influence the response variable. In some cases, it can literally be interpreted as the causal effect of an intervention that is linked to the value of a predictor variable. However, it has been argued that in many cases multiple regression analysis fails to clarify the relationships between the predictor variables and the response variable when the predictors are correlated with each other and are not assigned following a study design.[6]
Extensions
Numerous extensions of linear regression have been developed, which allow some or all of the assumptions underlying the basic model to be relaxed.
The simplest case of a single scalar predictor variable x and a single scalar response variable y is known as simple linear regression. The extension to multiple and/or vector-valued predictor variables (denoted with a capital X) is known as multiple linear regression, also known as multivariable linear regression (not to be confused with multivariate linear regression).[7]
Multiple linear regression is a generalization of simple linear regression to the case of more than one independent variable, and a special case of general linear models, restricted to one dependent variable. The basic model for multiple linear regression is
for each observation .
In the formula above we consider n observations of one dependent variable and p independent variables. Thus, Yi is the ith observation of the dependent variable, Xij is ith observation of the jth independent variable, j = 1, 2, ..., p. The values βj represent parameters to be estimated, and εi is the ith independent identically distributed normal error.
In the more general multivariate linear regression, there is one equation of the above form for each of m > 1 dependent variables that share the same set of explanatory variables and hence are estimated simultaneously with each other:
for all observations indexed as i = 1, ... , n and for all dependent variables indexed as j = 1, ... , m.
Nearly all real-world regression models involve multiple predictors, and basic descriptions of linear regression are often phrased in terms of the multiple regression model. Note, however, that in these cases the response variable y is still a scalar. Another term, multivariate linear regression, refers to cases where y is a vector, i.e., the same as general linear regression.
General linear models
The general linear model considers the situation when the response variable is not a scalar (for each observation) but a vector, yi. Conditional linearity of is still assumed, with a matrix B replacing the vector β of the classical linear regression model. Multivariate analogues of ordinary least squares (OLS) and generalized least squares (GLS) have been developed. "General linear models" are also called "multivariate linear models". These are not the same as multivariable linear models (also called "multiple linear models").
The Generalized linear model (GLM) is a framework for modeling response variables that are bounded or discrete. This is used, for example:
when modeling positive quantities (e.g. prices or populations) that vary over a large scale—which are better described using a skewed distribution such as the log-normal distribution or Poisson distribution (although GLMs are not used for log-normal data, instead the response variable is simply transformed using the logarithm function);
when modeling ordinal data, e.g. ratings on a scale from 0 to 5, where the different outcomes can be ordered but where the quantity itself may not have any absolute meaning (e.g. a rating of 4 may not be "twice as good" in any objective sense as a rating of 2, but simply indicates that it is better than 2 or 3 but not as good as 5).
Generalized linear models allow for an arbitrary link function, g, that relates the mean of the response variable(s) to the predictors: . The link function is often related to the distribution of the response, and in particular it typically has the effect of transforming between the range of the linear predictor and the range of the response variable.
Single index models[clarification needed] allow some degree of nonlinearity in the relationship between x and y, while preserving the central role of the linear predictor β′x as in the classical linear regression model. Under certain conditions, simply applying OLS to data from a single-index model will consistently estimate β up to a proportionality constant.[8]
Hierarchical linear models
Hierarchical linear models (or multilevel regression) organizes the data into a hierarchy of regressions, for example where A is regressed on B, and B is regressed on C. It is often used where the variables of interest have a natural hierarchical structure such as in educational statistics, where students are nested in classrooms, classrooms are nested in schools, and schools are nested in some administrative grouping, such as a school district. The response variable might be a measure of student achievement such as a test score, and different covariates would be collected at the classroom, school, and school district levels.
Errors-in-variables
Errors-in-variables models (or "measurement error models") extend the traditional linear regression model to allow the predictor variables X to be observed with error. This error causes standard estimators of β to become biased. Generally, the form of bias is an attenuation, meaning that the effects are biased toward zero.
parameter of predictor variable represents the individual effect of . It has an interpretation as the expected change in the response variable when increases by one unit with other predictor variables held constant. When is strongly correlated with other predictor variables, it is improbable that can increase by one unit with other variables held constant. In this case, the interpretation of becomes problematic as it is based on an improbable condition, and the effect of cannot be evaluated in isolation.
For a group of predictor variables, say, , a group effect is defined as a linear combination of their parameters
where is a weight vector satisfying . Because of the constraint on , is also referred to as a normalized group effect. A group effect has an interpretation as the expected change in when variables in the group change by the amount , respectively, at the same time with other variables (not in the group) held constant. It generalizes the individual effect of a variable to a group of variables in that () if , then the group effect reduces to an individual effect, and () if and for , then the group effect also reduces to an individual effect. A group effect is said to be meaningful if the underlying simultaneous changes of the variables is probable.
Group effects provide a means to study the collective impact of strongly correlated predictor variables in linear regression models. Individual effects of such variables are not well-defined as their parameters do not have good interpretations. Furthermore, when the sample size is not large, none of their parameters can be accurately estimated by the least squares regression due to the multicollinearity problem. Nevertheless, there are meaningful group effects that have good interpretations and can be accurately estimated by the least squares regression. A simple way to identify these meaningful group effects is to use an all positive correlations (APC) arrangement of the strongly correlated variables under which pairwise correlations among these variables are all positive, and standardize all predictor variables in the model so that they all have mean zero and length one. To illustrate this, suppose that is a group of strongly correlated variables in an APC arrangement and that they are not strongly correlated with predictor variables outside the group. Let be the centred and be the standardized . Then, the standardized linear regression model is
Parameters in the original model, including , are simple functions of in the standardized model. The standardization of variables does not change their correlations, so is a group of strongly correlated variables in an APC arrangement and they are not strongly correlated with other predictor variables in the standardized model. A group effect of is
and its minimum-variance unbiased linear estimator is
where is the least squares estimator of . In particular, the average group effect of the standardized variables is
which has an interpretation as the expected change in when all in the strongly correlated group increase by th of a unit at the same time with variables outside the group held constant. With strong positive correlations and in standardized units, variables in the group are approximately equal, so they are likely to increase at the same time and in similar amount. Thus, the average group effect is a meaningful effect. It can be accurately estimated by its minimum-variance unbiased linear estimator , even when individually none of the can be accurately estimated by .
Not all group effects are meaningful or can be accurately estimated. For example, is a special group effect with weights and for , but it cannot be accurately estimated by . It is also not a meaningful effect. In general, for a group of strongly correlated predictor variables in an APC arrangement in the standardized model, group effects whose weight vectors are at or near the centre of the simplex () are meaningful and can be accurately estimated by their minimum-variance unbiased linear estimators. Effects with weight vectors far away from the centre are not meaningful as such weight vectors represent simultaneous changes of the variables that violate the strong positive correlations of the standardized variables in an APC arrangement. As such, they are not probable. These effects also cannot be accurately estimated.
Applications of the group effects include (1) estimation and inference for meaningful group effects on the response variable, (2) testing for "group significance" of the variables via testing versus , and (3) characterizing the region of the predictor variable space over which predictions by the least squares estimated model are accurate.
A group effect of the original variables can be expressed as a constant times a group effect of the standardized variables . The former is meaningful when the latter is. Thus meaningful group effects of the original variables can be found through meaningful group effects of the standardized variables.[9]
Others
In Dempster–Shafer theory, or a linear belief function in particular, a linear regression model may be represented as a partially swept matrix, which can be combined with similar matrices representing observations and other assumed normal distributions and state equations. The combination of swept or unswept matrices provides an alternative method for estimating linear regression models.
Estimation methods
A large number of procedures have been developed for parameter estimation and inference in linear regression. These methods differ in computational simplicity of algorithms, presence of a closed-form solution, robustness with respect to heavy-tailed distributions, and theoretical assumptions needed to validate desirable statistical properties such as consistency and asymptotic efficiency.
Some of the more common estimation techniques for linear regression are summarized below.
Francis Galton's 1886 illustration of the correlation between the heights of adults and their parents. The observation that adult children's heights tended to deviate less from the mean height than their parents suggested the concept of "regression toward the mean", giving regression its name. The "locus of horizontal tangential points" passing through the leftmost and rightmost points on the ellipse (which is a level curve of the bivariate normal distribution estimated from the data) is the OLS estimate of the regression of parents' heights on children's heights, while the "locus of vertical tangential points" is the OLS estimate of the regression of children's heights on parent's heights. The major axis of the ellipse is the TLS estimate.
Assuming that the independent variables are and the model's parameters are , then the model's prediction would be
.
If is extended to then would become a dot product of the parameter and the independent vectors, i.e.
.
In the least-squares setting, the optimum parameter vector is defined as such that minimizes the sum of mean squared loss:
Now putting the independent and dependent variables in matrices and respectively, the loss function can be rewritten as:
Setting the gradient to zero produces the optimum parameter:
Note: The obtained may indeed be the local minimum, one needs to differentiate once more to obtain the Hessian matrix and show that it is positive definite. This is provided by the Gauss–Markov theorem.
Maximum-likelihood estimation and related techniques
Maximum likelihood estimation
Maximum likelihood estimation can be performed when the distribution of the error terms is known to belong to a certain parametric family ƒθ of probability distributions.[12] When fθ is a normal distribution with zero mean and variance θ, the resulting estimate is identical to the OLS estimate. GLS estimates are maximum likelihood estimates when ε follows a multivariate normal distribution with a known covariance matrix. Let's denote each data point by and the regression parameters as , and the set of all data by and the cost function by .
As shown below the same optimal parameter that minimizes achieves maximum likelihood too.[13] Here the assumption is that the dependent variable is a random variable that follows a Gaussian distribution, where the standard deviation is fixed and the mean is a linear combination of :
Now, we need to look for a parameter that maximizes this likelihood function. Since the logarithmic function is strictly increasing, instead of maximizing this function, we can also maximize its logarithm and find the optimal parameter that way.[13]
In this way, the parameter that maximizes is the same as the one that minimizes . This means that in linear regression, the result of the least squares method is the same as the result of the maximum likelihood estimation method.[13]
Regularized Regression
Ridge regression[14][15][16] and other forms of penalized estimation, such as Lasso regression,[17] deliberately introduce bias into the estimation of β in order to reduce the variability of the estimate. The resulting estimates generally have lower mean squared error than the OLS estimates, particularly when multicollinearity is present or when overfitting is a problem. They are generally used when the goal is to predict the value of the response variable y for values of the predictors x that have not yet been observed. These methods are not as commonly used when the goal is inference, since it is difficult to account for the bias.
Least Absolute Deviation
Least absolute deviation (LAD) regression is a robust estimation technique in that it is less sensitive to the presence of outliers than OLS (but is less efficient than OLS when no outliers are present). It is equivalent to maximum likelihood estimation under a Laplace distribution model for ε.[18]
Adaptive Estimation
If we assume that error terms are independent of the regressors, , then the optimal estimator is the 2-step MLE, where the first step is used to non-parametrically estimate the distribution of the error term.[19]
Bayesian linear regression applies the framework of Bayesian statistics to linear regression. (See also Bayesian multivariate linear regression.) In particular, the regression coefficients β are assumed to be random variables with a specified prior distribution. The prior distribution can bias the solutions for the regression coefficients, in a way similar to (but more general than) ridge regression or lasso regression. In addition, the Bayesian estimation process produces not a single point estimate for the "best" values of the regression coefficients but an entire posterior distribution, completely describing the uncertainty surrounding the quantity. This can be used to estimate the "best" coefficients using the mean, mode, median, any quantile (see quantile regression), or any other function of the posterior distribution.
Quantile regression focuses on the conditional quantiles of y given X rather than the conditional mean of y given X. Linear quantile regression models a particular conditional quantile, for example the conditional median, as a linear function βTx of the predictors.
Mixed models are widely used to analyze linear regression relationships involving dependent data when the dependencies have a known structure. Common applications of mixed models include analysis of data involving repeated measurements, such as longitudinal data, or data obtained from cluster sampling. They are generally fit as parametric models, using maximum likelihood or Bayesian estimation. In the case where the errors are modeled as normal random variables, there is a close connection between mixed models and generalized least squares.[20]Fixed effects estimation is an alternative approach to analyzing this type of data.
Principal component regression (PCR)[21][22] is used when the number of predictor variables is large, or when strong correlations exist among the predictor variables. This two-stage procedure first reduces the predictor variables using principal component analysis, and then uses the reduced variables in an OLS regression fit. While it often works well in practice, there is no general theoretical reason that the most informative linear function of the predictor variables should lie among the dominant principal components of the multivariate distribution of the predictor variables. The partial least squares regression is the extension of the PCR method which does not suffer from the mentioned deficiency.
Least-angle regression[23] is an estimation procedure for linear regression models that was developed to handle high-dimensional covariate vectors, potentially with more covariates than observations.
The Theil–Sen estimator is a simple robust estimation technique that chooses the slope of the fit line to be the median of the slopes of the lines through pairs of sample points. It has similar statistical efficiency properties to simple linear regression but is much less sensitive to outliers.[24]
Other robust estimation techniques, including the α-trimmed mean approach, and L-, M-, S-, and R-estimators have been introduced.
Linear regression is widely used in biological, behavioral and social sciences to describe possible relationships between variables. It ranks as one of the most important tools used in these disciplines.
A trend line represents a trend, the long-term movement in time series data after other components have been accounted for. It tells whether a particular data set (say GDP, oil prices or stock prices) have increased or decreased over the period of time. A trend line could simply be drawn by eye through a set of data points, but more properly their position and slope is calculated using statistical techniques like linear regression. Trend lines typically are straight lines, although some variations use higher degree polynomials depending on the degree of curvature desired in the line.
Trend lines are sometimes used in business analytics to show changes in data over time. This has the advantage of being simple. Trend lines are often used to argue that a particular action or event (such as training, or an advertising campaign) caused observed changes at a point in time. This is a simple technique, and does not require a control group, experimental design, or a sophisticated analysis technique. However, it suffers from a lack of scientific validity in cases where other potential changes can affect the data.
Epidemiology
Early evidence relating tobacco smoking to mortality and morbidity came from observational studies employing regression analysis. In order to reduce spurious correlations when analyzing observational data, researchers usually include several variables in their regression models in addition to the variable of primary interest. For example, in a regression model in which cigarette smoking is the independent variable of primary interest and the dependent variable is lifespan measured in years, researchers might include education and income as additional independent variables, to ensure that any observed effect of smoking on lifespan is not due to those other socio-economic factors. However, it is never possible to include all possible confounding variables in an empirical analysis. For example, a hypothetical gene might increase mortality and also cause people to smoke more. For this reason, randomized controlled trials are often able to generate more compelling evidence of causal relationships than can be obtained using regression analyses of observational data. When controlled experiments are not feasible, variants of regression analysis such as instrumental variables regression may be used to attempt to estimate causal relationships from observational data.
Finance
The capital asset pricing model uses linear regression as well as the concept of beta for analyzing and quantifying the systematic risk of an investment. This comes directly from the beta coefficient of the linear regression model that relates the return on the investment to the return on all risky assets.
Linear regression finds application in a wide range of environmental science applications such as land use,[29]infectious diseases,[30] and air pollution.[31] For example, linear regression can be used to predict the changing effects of car pollution.[32] One notable example of this application in infectious diseases is the flattening the curve strategy emphasized early in the COVID-19 pandemic, where public health officials dealt with sparse data on infected individuals and sophisticated models of disease transmission to characterize the spread of COVID-19.[33]
Building science
Linear regression is commonly used in building science field studies to derive characteristics of building occupants. In a thermal comfort field study, building scientists usually ask occupants' thermal sensation votes, which range from -3 (feeling cold) to 0 (neutral) to +3 (feeling hot), and measure occupants' surrounding temperature data. A neutral or comfort temperature can be calculated based on a linear regression between the thermal sensation vote and indoor temperature, and setting the thermal sensation vote as zero. However, there has been a debate on the regression direction: regressing thermal sensation votes (y-axis) against indoor temperature (x-axis) or the opposite: regressing indoor temperature (y-axis) against thermal sensation votes (x-axis).[34]
Isaac Newton is credited with inventing "a certain technique known today as linear regression analysis" in his work on equinoxes in 1700, and wrote down the first of the two normal equations of the ordinary least squares method.[36][37] The Least squares linear regression, as a means of finding a good rough linear fit to a set of points was performed by Legendre (1805) and Gauss (1809) for the prediction of planetary movement. Quetelet was responsible for making the procedure well-known and for using it extensively in the social sciences.[38]
↑Freedman, David A. (2009). Statistical Models: Theory and Practice. Cambridge University Press. p.26. A simple regression equation has on the right hand side an intercept and an explanatory variable with a slope coefficient. A multiple regression e right hand side, each with its own slope coefficient
↑Rencher, Alvin C.; Christensen, William F. (2012), "Chapter 10, Multivariate regression – Section 10.1, Introduction", Methods of Multivariate Analysis, Wiley Series in Probability and Statistics, vol.709 (3rded.), John Wiley & Sons, p.19, ISBN978-1-118-39167-9, archived from the original on 2024-10-04, retrieved 2015-02-07.
↑Yan, Xin (2009), Linear Regression Analysis: Theory and Computing, World Scientific, pp.1–2, ISBN978-981-283-411-9, archived from the original on 2024-10-04, retrieved 2015-02-07, Regression analysis ... is probably one of the oldest topics in mathematical statistics dating back to about two hundred years ago. The earliest form of the linear regression was the least squares method, which was published by Legendre in 1805, and by Gauss in 1809 ... Legendre and Gauss both applied the method to the problem of determining, from astronomical observations, the orbits of bodies about the sun.
↑Brillinger, David R. (1977). "The Identification of a Particular Nonlinear Time Series System". Biometrika. 64 (3): 509–515. doi:10.1093/biomet/64.3.509. JSTOR2345326.
↑Tsao, Min (2022). "Group least squares regression for linear models with strongly correlated predictor variables". Annals of the Institute of Statistical Mathematics. 75 (2): 233–250. arXiv:1804.02499. doi:10.1007/s10463-022-00841-7. S2CID237396158.
↑Swindel, Benee F. (1981). "Geometry of Ridge Regression Illustrated". The American Statistician. 35 (1): 12–15. doi:10.2307/2683577. JSTOR2683577.
↑Draper, Norman R.; van Nostrand; R. Craig (1979). "Ridge Regression and James-Stein Estimation: Review and Comments". Technometrics. 21 (4): 451–466. doi:10.2307/1268284. JSTOR1268284.
↑Hoerl, Arthur E.; Kennard, Robert W.; Hoerl, Roger W. (1985). "Practical Use of Ridge Regression: A Challenge Met". Journal of the Royal Statistical Society, Series C. 34 (2): 114–120. JSTOR2347363.
↑Tibshirani, Robert (1996). "Regression Shrinkage and Selection via the Lasso". Journal of the Royal Statistical Society, Series B. 58 (1): 267–288. doi:10.1111/j.2517-6161.1996.tb02080.x. JSTOR2346178.
↑Narula, Subhash C.; Wellington, John F. (1982). "The Minimum Sum of Absolute Errors Regression: A State of the Art Survey". International Statistical Review. 50 (3): 317–326. doi:10.2307/1402501. JSTOR1402501.
↑Goldstein, H. (1986). "Multilevel Mixed Linear Model Analysis Using Iterative Generalized Least Squares". Biometrika. 73 (1): 43–56. doi:10.1093/biomet/73.1.43. JSTOR2336270.
↑Hawkins, Douglas M. (1973). "On the Investigation of Alternative Regressions by Principal Component Analysis". Journal of the Royal Statistical Society, Series C. 22 (3): 275–286. Bibcode:1973AppSt..22..275H. doi:10.2307/2346776. JSTOR2346776.
↑Jolliffe, Ian T. (1982). "A Note on the Use of Principal Components in Regression". Journal of the Royal Statistical Society, Series C. 31 (3): 300–303. doi:10.2307/2348005. JSTOR2348005.
Charles Darwin. The Variation of Animals and Plants under Domestication. (1868) (Chapter XIII describes what was known about reversion in Galton's time. Darwin uses the term "reversion".)
Draper, N. R.; Smith, H. (1998). Applied Regression Analysis (3rded.). John Wiley. ISBN978-0-471-17082-2.
Francis Galton. "Regression Towards Mediocrity in Hereditary Stature," Journal of the Anthropological Institute, 15:246–263 (1886). (Facsimile at: Archived 2016-03-10 at the Wayback Machine )
Robert S. Pindyck and Daniel L. Rubinfeld (1998, 4th ed.). Econometric Models and Economic Forecasts, ch. 1 (Intro, including appendices on Σ operators & derivation of parameter est.) & Appendix 4.3 (mult. regression in matrix form).
Further reading
Pedhazur, Elazar J (1982). Multiple regression in behavioral research: Explanation and prediction (2nded.). New York: Holt, Rinehart and Winston. ISBN978-0-03-041760-3.
National Physical Laboratory (1961). "Chapter 1: Linear Equations and Matrices: Direct Methods". Modern Computing Methods. Notes on Applied Science. Vol.16 (2nded.). Her Majesty's Stationery Office.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.