Experiment using randomness in some aspect, usually to aid in removal of bias
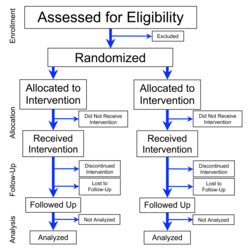
Flowchart of four phases (enrollment, intervention allocation, follow-up, and data analysis) of a parallel randomized trial of two groups, modified from the CONSORT 2010 Statement
In science, randomized experiments are the experiments that allow the greatest reliability and validity of statistical estimates of treatment effects. Randomization-based inference is especially important in experimental design and in survey sampling.
In the statistical theory of design of experiments, randomization involves randomly allocating the experimental units across the treatment groups. For example, if an experiment compares a new drug against a standard drug, then the patients should be allocated to either the new drug or to the standard drug control using randomization.
Randomized experimentation is not haphazard. Randomization reduces bias by equalising other factors that have not been explicitly accounted for in the experimental design (according to the law of large numbers). Randomization also produces ignorable designs, which are valuable in model-based statistical inference, especially Bayesian or likelihood-based. In the design of experiments, the simplest design for comparing treatments is the "completely randomized design". Some "restriction on randomization" can occur with blocking and experiments that have hard-to-change factors; additional restrictions on randomization can occur when a full randomization is infeasible or when it is desirable to reduce the variance of estimators of selected effects.
Randomization of treatment in clinical trials pose ethical problems. In some cases, randomization reduces the therapeutic options for both physician and patient, and so randomization requires clinical equipoise regarding the treatments.
Online randomized controlled experiments
Web sites can run randomized controlled experiments[2] to create a feedback loop.[3] Key differences between offline experimentation and online experiments include:[3][4]
Logging: user interactions can be logged reliably.
Number of users: large sites, such as Amazon, Bing/Microsoft, and Google run experiments, each with over a million users.
Number of concurrent experiments: large sites run tens of overlapping, or concurrent, experiments.[5]
A controlled experiment appears to have been suggested in the Old Testament's Book of Daniel. King Nebuchadnezzar proposed that some Israelites eat "a daily amount of food and wine from the king's table." Daniel preferred a vegetarian diet, but the official was concerned that the king would "see you looking worse than the other young men your age? The king would then have my head because of you." Daniel then proposed the following controlled experiment: "Test your servants for ten days. Give us nothing but vegetables to eat and water to drink. Then compare our appearance with that of the young men who eat the royal food, and treat your servants in accordance with what you see". (Daniel 1:12–13).[8][9]
Randomized experiments were institutionalized in psychology and education in the late eighteen-hundreds, following the invention of randomized experiments by C. S. Peirce.[10][11][12][13] Outside of psychology and education, randomized experiments were popularized by R.A. Fisher in his book Statistical Methods for Research Workers, which also introduced additional principles of experimental design.
Statistical interpretation
This section needs expansion. You can help by adding to it. (September 2012)
The Rubin Causal Model provides a common way to describe a randomized experiment. While the Rubin Causal Model provides a framework for defining the causal parameters (i.e., the effects of a randomized treatment on an outcome), the analysis of experiments can take a number of forms. The model assumes that there are two potential outcomes for each unit in the study: the outcome if the unit receives the treatment and the outcome if the unit does not receive the treatment. The difference between these two potential outcomes is known as the treatment effect, which is the causal effect of the treatment on the outcome. Most commonly, randomized experiments are analyzed using ANOVA, student's t-test, regression analysis, or a similar statistical test. The model also accounts for potential confounding factors, which are factors that could affect both the treatment and the outcome. By controlling for these confounding factors, the model helps to ensure that any observed treatment effect is truly causal and not simply the result of other factors that are correlated with both the treatment and the outcome.
The Rubin Causal Model is a useful a framework for understanding how to estimate the causal effect of the treatment, even when there are confounding variables that may affect the outcome. This model specifies that the causal effect of the treatment is the difference in the outcomes that would have been observed for each individual if they had received the treatment and if they had not received the treatment. In practice, it is not possible to observe both potential outcomes for the same individual, so statistical methods are used to estimate the causal effect using data from the experiment.
Empirical evidence that randomization makes a difference
Empirically differences between randomized and non-randomized studies,[14][needs update] and between adequately and inadequately randomized trials have been difficult to detect.[15][16]
Directed acyclic graph (DAG) explanation of randomization
Randomization is the cornerstone of many scientific claims. To randomize, means that we can eliminate the confounding factors. Say we study the effect of A on B. Yet, there are many unobservables U that potentially affect B and confound our estimate of the finding. To explain these kinds of issues, statisticians or econometricians nowadays use directed acyclic graph.[needs update]
↑ Kohavi, Ron; Longbotham, Roger (2015). "Online Controlled Experiments and A/B Tests"(PDF). In Sammut, Claude; Webb, Geoff (eds.). Encyclopedia of Machine Learning and Data Mining. Springer. pp.to appear.
↑ Kohavi, Ron; Deng Alex; Frasca Brian; Walker Toby; Xu Ya; Nils Pohlmann (2013). "Online controlled experiments at large scale". Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining. Vol.19. Chicago, Illinois, USA: ACM. pp.1168–1176. doi:10.1145/2487575.2488217. ISBN9781450321747. S2CID13224883.
↑ Stephen M. Stigler (November 1992). "A Historical View of Statistical Concepts in Psychology and Educational Research". American Journal of Education. 101 (1): 60–70. doi:10.1086/444032. S2CID143685203.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.