Statistic which divides a data set into 100 parts and analyzes it as a percentage
In statistics, a k-thpercentile, also known as percentile score or centile, is a score (e.g., a data point) below which a given percentagek of all scores in its frequency distribution exists ("exclusive" definition). Alternatively, it is a score at or below which a given percentage of the all scores exists ("inclusive" definition). I.e., a score in the k-th percentile would be above approximately k% of all scores in its set. For example, under the exclusive definition, the 97th percentile is the value such that 97% of the data points are less than it. Percentiles depends on how scores are arranged.
Percentiles are a type of quantiles, obtained by a subdivision into 100 groups. The 25th percentile is also known as the first quartile (Q1), the 50th percentile as the median or second quartile (Q2), and the 75th percentile as the third quartile (Q3). For example, the 50th percentile (median) is the score below (or at or below, depending on the definition) which 50% of the scores in the distribution are found.
A related quantity is the percentile rank of a given score, expressed in percent, which represents the fraction of scores in its distribution that are less than it, an exclusive definition. Percentile scores and percentile ranks are often used in the reporting of test scores from norm-referenced tests, but, as just noted, they are not the same. For percentile ranks, a score is given and a percentage is computed. Percentile ranks are exclusive: if the percentile rank for a specified score is 90%, then 90% of the scores were lower. In contrast, for percentiles a percentage is given and a corresponding score is determined, which can be either exclusive or inclusive. The score for a specified percentage (e.g., 90th) indicates a score below which (exclusive definition) or at or below which (inclusive definition) other scores in the distribution fall.
Definitions
There is no standard definition of percentile;[1][2][3] however, all definitions yield similar results when the number of observations is very large and the probability distribution is continuous.[4] In the limit, as the sample size approaches infinity, the 100pth percentile (0<p<1) approximates the inverse of the cumulative distribution function (CDF) thus formed, evaluated at p, as p approximates the CDF. This can be seen as a consequence of the Glivenko–Cantelli theorem. Some methods for calculating the percentiles are given below.
In the normal distribution
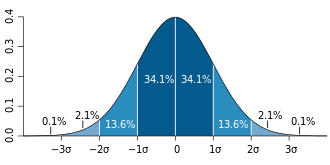
Representation of the three-sigma rule. The dark blue zone represents observations within one standard deviation (σ) to either side of the mean (μ), which accounts for about 68.3% of the population. Two standard deviations from the mean (dark and medium blue) account for about 95.4%, and three standard deviations (dark, medium, and light blue) for about 99.7%.
The methods given in the calculation methods section (below) are approximations for use in small-sample statistics. In general terms, for very large populations following a normal distribution, percentiles may often be represented by reference to a normal curve plot. The normal distribution is plotted along an axis scaled to standard deviations, or sigma () units. Mathematically, the normal distribution extends to negative infinity on the left and positive infinity on the right. Note, however, that only a very small proportion of individuals in a population will fall outside the −3σ to +3σ range. For example, with human heights very few people are above the +3σ height level.
Percentiles represent the area under the normal curve, increasing from left to right. Each standard deviation represents a fixed percentile. Thus, rounding to two decimal places, −3σ is the 0.13th percentile, −2σ the 2.28th percentile, −1σ the 15.87th percentile, 0σ the 50th percentile (both the mean and median of the distribution), +1σ the 84.13rd percentile, +2σ the 97.72nd percentile, and +3σ the 99.87th percentile. This is related to the 68–95–99.7 rule or the three-sigma rule. Note that in theory the 0th percentile falls at negative infinity and the 100th percentile at positive infinity, although in many practical applications, such as test results, natural lower and/or upper limits are enforced.
Applications
When Internet service provider bill "burstable" internet bandwidth, the 95th or 98th percentile usually cuts off the top 5% or 2% of bandwidth peaks in each month, and then bills at the nearest rate. In this way, infrequent peaks are ignored, and the customer is charged in a fairer way. The reason this statistic is so useful in measuring data throughput is that it gives a very accurate picture of the cost of the bandwidth. The 95th percentile says that 95% of the time, the usage is below this amount: so, the remaining 5% of the time, the usage is above that amount.
Physicians will often use infant and children's weight and height to assess their growth in comparison to national median and other percentiles which are found in growth charts.
The 85th percentile speed of traffic on a road is often used as a guideline in setting speed limits and assessing whether such a limit is too high or low.[5][6]
In finance, value at risk is a standard measure to assess (in a model-dependent way) the quantity under which the value of the portfolio is not expected to sink within a given period of time and given a confidence value.
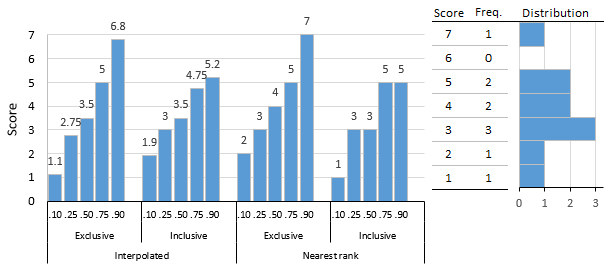
Interpolated and nearest-rank, exclusive and inclusive, percentiles for 10-score distribution
Interpolated and nearest-rank, exclusive and inclusive, percentiles for 10-score distribution
There are many formulas or algorithms[7] for a percentile score. Hyndman and Fan [1] identified nine and most statistical and spreadsheet software use one of the methods they describe.[8] Algorithms either return the value of a score that exists in the set of scores (nearest-rank methods) or interpolate between existing scores and are either exclusive or inclusive.
Nearest-rank methods (exclusive/inclusive)
PC: percentile specified
0.10
0.25
0.50
0.75
0.90
N: Number of scores
10
10
10
10
10
OR: ordinal rank = PC × N
1
2.5
5
7.5
9
Rank: >OR / ≥OR
2/1
3/3
6/5
8/8
10/9
Score at rank (exc/inc)
2/1
3/3
4/3
5/5
7/5
The figure shows a 10-score distribution, illustrates the percentile scores that result from these different algorithms, and serves as an introduction to the examples given subsequently. The simplest are nearest-rank methods that return a score from the distribution, although compared to interpolation methods, results can be a bit crude. The Nearest-Rank Methods table shows the computational steps for exclusive and inclusive methods.
Interpolated methods (exclusive/inclusive)
PC: percentile specified
0.10
0.25
0.50
0.75
0.90
N: number of scores
10
10
10
10
10
OR: PC×(N+1) / PC×(N−1)+1
1.1/1.9
2.75/3.25
5.5/5.5
8.25/7.75
9.9/9.1
LoRank: OR truncated
1/1
2/3
5/5
8/7
9/9
HIRank: OR rounded up
2/2
3/4
6/6
9/8
10/10
LoScore: score at LoRank
1/1
2/3
3/3
5/4
5/5
HiScore: score at HiRank
2/2
3/3
4/4
5/5
7/7
Difference: HiScore − LoScore
1/1
1/0
1/1
0/1
2/2
Mod: fractional part of OR
0.1/0.9
0.75/0.25
0.5/0.5
0.25/0.75
0.9/0.1
Interpolated score (exc/inc) = LoScore + Mod × Difference
1.1/1.9
2.75/3
3.5/3.5
5/4.75
6.8/5.2
Interpolation methods, as the name implies, can return a score that is between scores in the distribution. Algorithms used by statistical programs typically use interpolation methods, for example, the percentile.exc and percentile.inc functions in Microsoft Excel. The Interpolated Methods table shows the computational steps.
The nearest-rank method
The percentile values for the ordered list {15, 20, 35, 40, 50}
One definition of percentile, often given in texts, is that the P-th percentile of a list of N ordered values (sorted from least to greatest) is the smallest value in the list such that no more than P percent of the data is strictly less than the value and at least P percent of the data is less than or equal to that value.
This is calculated by first calculating the ordinalrank and then taking the value from the ordered list that corresponds to that rank. The ordinal rank n is calculated using the formula
Using the nearest-rank method on lists with fewer than 100 distinct values can result in the same value being used for more than one percentile.
A percentile calculated using the nearest-rank method will always be a member of the original ordered list.
The 100th percentile is defined to be the largest value in the ordered list.
This method is also called the "empirical distribution function" method.[9]
The 50th percentile calculated using this method is equal to the usual value of the median if N is odd, but not if N is even.[9]
The CDF method
The CDF method was described, e.g. by Langford.[9]
the linear interpolation is simply accomplished by calculating
, where uses the floor function to represent the integral part of x, whereas uses the mod function to represent its fractional part (the remainder after division by 1).
This way,
As we can see, x is the continuous version of the subscript i, linearly interpolating v between adjacent nodes.
There are two ways in which the variant approaches differ. The first is in the linear relationship between the rankx, the percent rank, and a constant that is a function of the sample size N:
There is the additional requirement that the midpoint of the range , corresponding to the median, occur at :
and our revised function now has just one degree of freedom, looking like this:
The second way in which the variants differ is in the definition of the function near the margins of the range of p: should produce, or be forced to produce, a result in the range , which may mean the absence of a one-to-one correspondence in the wider region. One author has suggested a choice of where ξ is the shape of the Generalized extreme value distribution which is the extreme value limit of the sampled distribution.
First variant, C = 1/2
The result of using each of the three variants on the ordered list {15, 20, 35, 40, 50}
The inverse relationship is restricted to a narrower region:
Second variant, C = 1
[Source: Some software packages, including NumPy[11] and Microsoft Excel[3] (up to and including version 2013 by means of the PERCENTILE.INC function). Noted as an alternative by NIST.[8]]
Note that the relationship is one-to-one for , the only one of the three variants with this property; hence the "INC" suffix, for inclusive, on the Excel function.
Third variant, C = 0
(The primary variant recommended by NIST.[8] Adopted by Microsoft Excel since 2010 by means of PERCENTIL.EXC function. However, as the "EXC" suffix indicates, the Excel version excludes both endpoints of the range of p, i.e., , whereas the "INC" version, the second variant, does not; in fact, any number smaller than is also excluded and would cause an error.)
In addition to the percentile function, there is also a weighted percentile, where the percentage in the total weight is counted instead of the total number. There is no standard function for a weighted percentile. One method extends the above approach in a natural way.
Suppose we have positive weights associated, respectively, with our N sorted sample values. Let
the sum of the weights. Then the formulas above are generalized by taking
when ,
or
for general ,
and
The 50% weighted percentile is known as the weighted median.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.