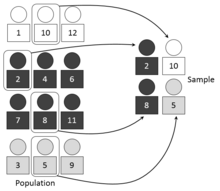
In statistical surveys, when subpopulations within an overall population vary, it could be advantageous to sample each subpopulation (stratum) independently.
Stratification is the process of dividing members of the population into homogeneous subgroups before sampling. The strata should define a partition of the population. That is, it should be collectively exhaustive and mutually exclusive: every element in the population must be assigned to one and only one stratum. Then sampling is done in each stratum, for example: by simple random sampling. The objective is to improve the precision of the sample by reducing sampling error. It can produce a weighted mean that has less variability than the arithmetic mean of a simple random sample of the population.
Assume that we need to estimate the average number of votes for each candidate in an election. Assume that a country has 3 towns: Town A has 1 million factory workers, Town B has 2 million office workers and Town C has 3 million retirees. We can choose to get a random sample of size 60 over the entire population but there is some chance that the resulting random sample is poorly balanced across these towns and hence is biased, causing a significant error in estimation (when the outcome of interest has a different distribution, in terms of the parameter of interest, between the towns). Instead, if we choose to take a random sample of 10, 20 and 30 from Town A, B and C respectively, then we can produce a smaller error in estimation for the same total sample size. This method is generally used when a population is not a homogeneous group.
Strategies
Proportionate allocation uses a sampling fraction in each of the strata that are proportional to that of the total population. For instance, if the population consists of n total individuals, m of which are male and f female (and where m + f = n), then the relative size of the two samples (x1 = m/n males, x2 = f/n females) should reflect this proportion.
Optimum allocation (or disproportionate allocation) – The sampling fraction of each stratum is proportionate to both the proportion (as above) and the standard deviation of the distribution of the variable. Larger samples are taken in the strata with the greatest variability to generate the least possible overall sampling variance.
A real-world example of using stratified sampling would be for a political survey. If the respondents needed to reflect the diversity of the population, the researcher would specifically seek to include participants of various minority groups such as race or religion, based on their proportionality to the total population as mentioned above. A stratified survey could thus claim to be more representative of the population than a survey of simple random sampling or systematic sampling. Both mean and variance can be corrected for disproportionate sampling costs using stratified sample sizes.
If measurements within strata have a lower standard deviation (as compared to the overall standard deviation in the population), stratification gives a smaller error in estimation.
For many applications, measurements become more manageable and/or cheaper when the population is grouped into strata.
When it is desirable to have estimates of the population parameters for groups within the population – stratified sampling verifies we have enough samples from the strata of interest.
If the population density varies greatly within a region, stratified sampling will ensure that estimates can be made with equal accuracy in different parts of the region, and that comparisons of sub-regions can be made with equal statistical power. For example, in Ontario a survey taken throughout the province might use a larger sampling fraction in the less populated north, since the disparity in population between north and south is so great that a sampling fraction based on the provincial sample as a whole might result in the collection of only a handful of data from the north.
Disadvantages
It would be a misapplication of the technique to make subgroups' sample sizes proportional to the amount of data available from the subgroups, rather than scaling sample sizes to subgroup sizes (or to their variances, if known to vary significantly—e.g. using an F test). Data representing each subgroup are taken to be of equal importance if suspected variation among them warrants stratified sampling. If subgroup variances differ significantly and the data needs to be stratified by variance, it is not possible to simultaneously make each subgroup sample size proportional to subgroup size within the total population. For an efficient way to partition sampling resources among groups that vary in their means, variance and costs, see "optimum allocation". The problem of stratified sampling in the case of unknown class priors (ratio of subpopulations in the entire population) can have a deleterious effect on the performance of any analysis on the dataset, e.g. classification.[3] In that regard, minimax sampling ratio can be used to make the dataset robust with respect to uncertainty in the underlying data generating process.[3]
Combining sub-strata to ensure adequate numbers can lead to Simpson's paradox, where trends that exist in different groups of data disappear or even reverse when the groups are combined.
Mean and standard error
The mean and variance of stratified random sampling are given by:[2]
where
number of strata
the sum of all stratum sizes
size of stratum
sample mean of stratum
number of observations in stratum
sample standard deviation of stratum
Note that the term , which equals , is a finite population correction and must be expressed in "sample units". Foregoing the finite population correction gives:
where the is the population weight of stratum .
Sample size allocation
For the proportional allocation strategy, the size of the sample in each stratum is taken in proportion to the size of the stratum. Suppose that in a company there are the following staff:[4]
male, full-time: 90
male, part-time: 18
female, full-time: 9
female, part-time: 63
total: 180
and we are asked to take a sample of 40 staff, stratified according to the above categories.
The first step is to calculate the percentage of each group of the total.
% male, full-time = 90 ÷ 180 = 50%
% male, part-time = 18 ÷ 180 = 10%
% female, full-time = 9 ÷ 180 = 5%
% female, part-time = 63 ÷ 180 = 35%
This tells us that of our sample of 40,
50% (20 individuals) should be male, full-time.
10% (4 individuals) should be male, part-time.
5% (2 individuals) should be female, full-time.
35% (14 individuals) should be female, part-time.
Another easy way without having to calculate the percentage is to multiply each group size by the sample size and divide by the total population size (size of entire staff):
↑ Hunt, Neville; Tyrrell, Sidney (2001). "Stratified Sampling". Webpage at Coventry University. Archived from the original on 13 October 2013. Retrieved 12 July 2012.
Further reading
Särndal, Carl-Erik; etal. (2003). "Stratified Sampling". Model Assisted Survey Sampling. New York: Springer. pp.100–109. ISBN0-387-40620-4.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.