Visual comparison of convolution, cross-correlation and autocorrelation. For the operations involving function f, and assuming the height of f is 1.0, the value of the result at 5 different points is indicated by the shaded area below each point. Also, the vertical symmetry of f is the reason and are identical in this example.
In probability and statistics, the term cross-correlations refers to the correlations between the entries of two random vectors and , while the correlations of a random vector are the correlations between the entries of itself, those forming the correlation matrix of . If each of and is a scalar random variable which is realized repeatedly in a time series, then the correlations of the various temporal instances of are known as autocorrelations of , and the cross-correlations of with across time are temporal cross-correlations. In probability and statistics, the definition of correlation always includes a standardising factor in such a way that correlations have values between −1 and +1.
If and are two independentrandom variables with probability density functions and , respectively, then the probability density of the difference is formally given by the cross-correlation (in the signal-processing sense) ; however, this terminology is not used in probability and statistics. In contrast, the convolution (equivalent to the cross-correlation of and ) gives the probability density function of the sum .
Cross-correlation of deterministic signals
For continuous functions and , the cross-correlation is defined as:[1][2][3]which is equivalent towhere denotes the complex conjugate of , and is called displacement or lag.
For highly-correlated and which have a maximum cross-correlation at a particular , a feature in at also occurs later in at , hence could be described to lag by .
If and are both continuous periodic functions of period , the integration from to is replaced by integration over any interval of length :which is equivalent toSimilarly, for discrete functions, the cross-correlation is defined as:[4][5]which is equivalent to:For finite discrete functions , the (circular) cross-correlation is defined as:[6]which is equivalent to:For finite discrete functions , , the kernel cross-correlation is defined as:[7]where is a vector of kernel functions and is an affine transform.
Specifically, can be circular translation transform, rotation transform, or scale transform, etc. The kernel cross-correlation extends cross-correlation from linear space to kernel space. Cross-correlation is equivariant to translation; kernel cross-correlation is equivariant to any affine transforms, including translation, rotation, and scale, etc.
Explanation
As an example, consider two real valued functions and differing only by an unknown shift along the x-axis. One can use the cross-correlation to find how much must be shifted along the x-axis to make it identical to . The formula essentially slides the function along the x-axis, calculating the integral of their product at each position. When the functions match, the value of is maximized. This is because when peaks (positive areas) are aligned, they make a large contribution to the integral. Similarly, when troughs (negative areas) align, they also make a positive contribution to the integral because the product of two negative numbers is positive.
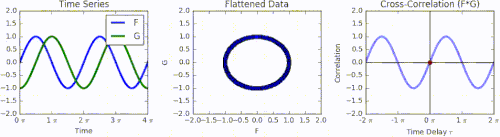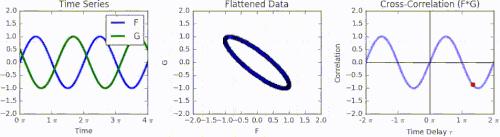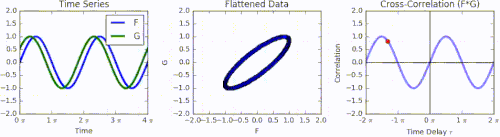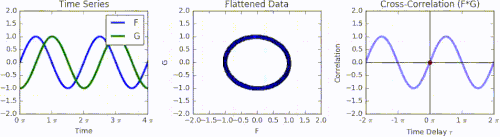
Animation of how cross-correlation is calculated. The left graph shows a green function G that is phase-shifted relative to function F by a time displacement of 𝜏. The middle graph shows the function F and the phase-shifted G represented together as a Lissajous curve. Integrating F multiplied by the phase-shifted G produces the right graph, the cross-correlation across all values of 𝜏.
With complex-valued functions and , taking the conjugate of ensures that aligned peaks (or aligned troughs) with imaginary components will contribute positively to the integral.
In econometrics, lagged cross-correlation is sometimes referred to as cross-autocorrelation.[8]:p. 74
Properties
The cross-correlation of functions and is equivalent to the convolution (denoted by ) of and . That is:
where denotes the Fourier transform, and an again indicates the complex conjugate of , since . Coupled with fast Fourier transform algorithms, this property is often exploited for the efficient numerical computation of cross-correlations[9] (see circular cross-correlation).
For random vectors and , each containing random elements whose expected value and variance exist, the cross-correlation matrix of and is defined by[10]:p.337and has dimensions . Written component-wise:The random vectors and need not have the same dimension, and either might be a scalar value. Where is the expectation value.
Example
For example, if and are random vectors, then is a matrix whose -th entry is .
Definition for complex random vectors
If and are complex random vectors, each containing random variables whose expected value and variance exist, the cross-correlation matrix of and is defined bywhere denotes Hermitian transposition.
Cross-correlation of stochastic processes
In time series analysis and statistics, the cross-correlation of a pair of random process is the correlation between values of the processes at different times, as a function of the two times. Let be a pair of random processes, and be any point in time ( may be an integer for a discrete-time process or a real number for a continuous-time process). Then is the value (or realization) produced by a given run of the process at time .
Cross-correlation function
Suppose that the process has means and and variances and at time , for each . Then the definition of the cross-correlation between times and is[10]:p.392where is the expected value operator. Note that this expression may be not defined.
Cross-covariance function
Subtracting the mean before multiplication yields the cross-covariance between times and :[10]:p.392Note that this expression is not well-defined for all time series or processes, because the mean or variance may not exist.
Definition for wide-sense stationary stochastic process
This definition is used by Newland[11]. Note that some references including Gubner[10] use an alternative convention , which is equivalent to reversing the sign of the time lag and (for complex-valued processes) taking the complex conjugate. The resulting spectrum will be the complex conjugate of one obtained based on the other convention.
Cross-covariance function
or equivalently where and are the mean and standard deviation of the process , which are constant over time due to stationarity; and similarly for , respectively. indicates the expected value. That the cross-covariance and cross-correlation are independent of is precisely the additional information (beyond being individually wide-sense stationary) conveyed by the requirement that are jointly wide-sense stationary.
The cross-correlation of a pair of jointly wide sense stationarystochastic processes can be estimated by averaging the product of samples measured from one process and samples measured from the other (and its time shifts). The samples included in the average can be an arbitrary subset of all the samples in the signal (e.g., samples within a finite time window or a sub-sampling[which?] of one of the signals). For a large number of samples, the average converges to the true cross-correlation.
Normalization
It is common practice in some disciplines (e.g. statistics and time series analysis) to normalize the cross-correlation function to get a time-dependent Pearson correlation coefficient. However, in other disciplines (e.g. engineering) the normalization is usually dropped and the terms "cross-correlation" and "cross-covariance" are used interchangeably.
The definition of the normalized cross-correlation of a stochastic process isIf the function is well-defined, its value must lie in the range , with 1 indicating perfect correlation and −1 indicating perfect anti-correlation.
For jointly wide-sense stationary stochastic processes, the definition isThe normalization is important both because the interpretation of the autocorrelation as a correlation provides a scale-free measure of the strength of statistical dependence, and because the normalization has an effect on the statistical properties of the estimated autocorrelations.
Properties
Symmetry property
For jointly wide-sense stationary stochastic processes, the cross-correlation function has the following symmetry property:[12]:p.173Respectively for jointly WSS processes:
Time delay analysis
Cross-correlations are useful for determining the time delay between two signals, e.g., for determining time delays for the propagation of acoustic signals across a microphone array.[13][14][clarification needed] After calculating the cross-correlation between the two signals, the maximum (or minimum if the signals are negatively correlated) of the cross-correlation function indicates the point in time where the signals are best aligned; i.e., the time delay between the two signals is determined by the argument of the maximum, or arg max of the cross-correlation, as inTerminology in image processing
Zero-normalized cross-correlation (ZNCC)
For image-processing applications in which the brightness of the image and template can vary due to lighting and exposure conditions, the images can be first normalized. This is typically done at every step by subtracting the mean and dividing by the standard deviation. That is, the cross-correlation of a template with a subimage is
where is the number of pixels in and , is the average of and is standard deviation of .
Thus, if and are real matrices, their normalized cross-correlation equals the cosine of the angle between the unit vectors and , being thus if and only if equals multiplied by a positive scalar.
NCC is similar to ZNCC with the only difference of not subtracting the local mean value of intensities:
Nonlinear systems
Caution must be applied when using cross correlation function which assumes Gaussian variance for nonlinear systems. In certain circumstances, which depend on the properties of the input, cross correlation between the input and output of a system with nonlinear dynamics can be completely blind to certain nonlinear effects.[15] This problem arises because some quadratic moments can equal zero and this can incorrectly suggest that there is little "correlation" (in the sense of statistical dependence) between two signals, when in fact the two signals are strongly related by nonlinear dynamics.
↑Wang, Chen; Zhang, Le; Yuan, Junsong; Xie, Lihua (2018). "Kernel Cross-Correlator". Proceedings of the AAAI Conference on Artificial Intelligence. The Thirty-second AAAI Conference On Artificial Intelligence. 32. Association for the Advancement of Artificial Intelligence: 4179–4186. doi:10.1609/aaai.v32i1.11710. S2CID3544911.
↑Campbell; Lo; MacKinlay (1996). The Econometrics of Financial Markets. NJ: Princeton University Press. ISBN0691043019.
↑Kapinchev, Konstantin; Bradu, Adrian; Barnes, Frederick; Podoleanu, Adrian (2015). "GPU implementation of cross-correlation for image generation in real time". 2015 9th International Conference on Signal Processing and Communication Systems (ICSPCS). pp.1–6. doi:10.1109/ICSPCS.2015.7391783. ISBN978-1-4673-8118-5. S2CID17108908.
1234Gubner, John A. (2006). Probability and Random Processes for Electrical and Computer Engineers. Cambridge University Press. ISBN978-0-521-86470-1.
↑Newland, D. E. (1993). An introduction to random vibrations, spectral and wavelet analysis (3rded.). Wiley. ISBN978-0-582-21584-9.
↑Kun Il Park, Fundamentals of Probability and Stochastic Processes with Applications to Communications, Springer, 2018, 978-3-319-68074-3
↑Rhudy, Matthew; Brian Bucci; Jeffrey Vipperman; Jeffrey Allanach; Bruce Abraham (November 2009). Microphone Array Analysis Methods Using Cross-Correlations. Proceedings of 2009 ASME International Mechanical Engineering Congress, Lake Buena Vista, FL. pp.281–288. doi:10.1115/IMECE2009-10798. ISBN978-0-7918-4388-8.
↑Billings, S. A. (2013). Nonlinear System Identification: NARMAX Methods in the Time, Frequency, and Spatio-Temporal Domains. Wiley. ISBN978-1-118-53556-1.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.

![Visual comparison of convolution, cross-correlation and autocorrelation. For the operations involving function f, and assuming the height of f is 1.0, the value of the result at 5 different points is indicated by the shaded area below each point. Also, the vertical symmetry of f is the reason
f
*
g
{\displaystyle f*g}
and
f
[?]
g
{\displaystyle f\star g}
are identical in this example. Comparison convolution correlation.svg](http://upload.wikimedia.org/wikipedia/commons/thumb/2/21/Comparison_convolution_correlation.svg/500px-Comparison_convolution_correlation.svg.png)