
In statistics, correlation or dependence is any statistical relationship, whether causal or not, between two random variables or bivariate data. Although in the broadest sense, "correlation" may indicate any type of association, in statistics it usually refers to the degree to which a pair of variables are linearly related. Familiar examples of dependent phenomena include the correlation between the height of parents and their offspring, and the correlation between the price of a good and the quantity the consumers are willing to purchase, as it is depicted in the so-called demand curve.

In statistics, the Pearson correlation coefficient (PCC) is a correlation coefficient that measures linear correlation between two sets of data. It is the ratio between the covariance of two variables and the product of their standard deviations; thus, it is essentially a normalized measurement of the covariance, such that the result always has a value between −1 and 1. As with covariance itself, the measure can only reflect a linear correlation of variables, and ignores many other types of relationships or correlations. As a simple example, one would expect the age and height of a sample of teenagers from a high school to have a Pearson correlation coefficient significantly greater than 0, but less than 1.
Pearson's chi-squared test is a statistical test applied to sets of categorical data to evaluate how likely it is that any observed difference between the sets arose by chance. It is the most widely used of many chi-squared tests – statistical procedures whose results are evaluated by reference to the chi-squared distribution. Its properties were first investigated by Karl Pearson in 1900. In contexts where it is important to improve a distinction between the test statistic and its distribution, names similar to Pearson χ-squared test or statistic are used.

In statistics, Spearman's rank correlation coefficient or Spearman's ρ, named after Charles Spearman and often denoted by the Greek letter (rho) or as , is a nonparametric measure of rank correlation. It assesses how well the relationship between two variables can be described using a monotonic function.
An odds ratio (OR) is a statistic that quantifies the strength of the association between two events, A and B. The odds ratio is defined as the ratio of the odds of A in the presence of B and the odds of A in the absence of B, or equivalently, the ratio of the odds of B in the presence of A and the odds of B in the absence of A. Two events are independent if and only if the OR equals 1, i.e., the odds of one event are the same in either the presence or absence of the other event. If the OR is greater than 1, then A and B are associated (correlated) in the sense that, compared to the absence of B, the presence of B raises the odds of A, and symmetrically the presence of A raises the odds of B. Conversely, if the OR is less than 1, then A and B are negatively correlated, and the presence of one event reduces the odds of the other event.
In statistics, an effect size is a value measuring the strength of the relationship between two variables in a population, or a sample-based estimate of that quantity. It can refer to the value of a statistic calculated from a sample of data, the value of a parameter for a hypothetical population, or to the equation that operationalizes how statistics or parameters lead to the effect size value. Examples of effect sizes include the correlation between two variables, the regression coefficient in a regression, the mean difference, or the risk of a particular event happening. Effect sizes complement statistical hypothesis testing, and play an important role in power analyses, sample size planning, and in meta-analyses. The cluster of data-analysis methods concerning effect sizes is referred to as estimation statistics.
Omnibus tests are a kind of statistical test. They test whether the explained variance in a set of data is significantly greater than the unexplained variance, overall. One example is the F-test in the analysis of variance. There can be legitimate significant effects within a model even if the omnibus test is not significant. For instance, in a model with two independent variables, if only one variable exerts a significant effect on the dependent variable and the other does not, then the omnibus test may be non-significant. This fact does not affect the conclusions that may be drawn from the one significant variable. In order to test effects within an omnibus test, researchers often use contrasts.
In statistics, the Kendall rank correlation coefficient, commonly referred to as Kendall's τ coefficient, is a statistic used to measure the ordinal association between two measured quantities. A τ test is a non-parametric hypothesis test for statistical dependence based on the τ coefficient. It is a measure of rank correlation: the similarity of the orderings of the data when ranked by each of the quantities. It is named after Maurice Kendall, who developed it in 1938, though Gustav Fechner had proposed a similar measure in the context of time series in 1897.
In probability theory and statistics, partial correlation measures the degree of association between two random variables, with the effect of a set of controlling random variables removed. When determining the numerical relationship between two variables of interest, using their correlation coefficient will give misleading results if there is another confounding variable that is numerically related to both variables of interest. This misleading information can be avoided by controlling for the confounding variable, which is done by computing the partial correlation coefficient. This is precisely the motivation for including other right-side variables in a multiple regression; but while multiple regression gives unbiased results for the effect size, it does not give a numerical value of a measure of the strength of the relationship between the two variables of interest.
In statistics, Goodman and Kruskal's gamma is a measure of rank correlation, i.e., the similarity of the orderings of the data when ranked by each of the quantities. It measures the strength of association of the cross tabulated data when both variables are measured at the ordinal level. It makes no adjustment for either table size or ties. Values range from −1 to +1. A value of zero indicates the absence of association.
Correspondence analysis (CA) is a multivariate statistical technique proposed by Herman Otto Hartley (Hirschfeld) and later developed by Jean-Paul Benzécri. It is conceptually similar to principal component analysis, but applies to categorical rather than continuous data. In a similar manner to principal component analysis, it provides a means of displaying or summarising a set of data in two-dimensional graphical form. Its aim is to display in a biplot any structure hidden in the multivariate setting of the data table. As such it is a technique from the field of multivariate ordination. Since the variant of CA described here can be applied either with a focus on the rows or on the columns it should in fact be called simple (symmetric) correspondence analysis.
In statistics, the phi coefficient is a measure of association for two binary variables.
A correlation coefficient is a numerical measure of some type of correlation, meaning a statistical relationship between two variables. The variables may be two columns of a given data set of observations, often called a sample, or two components of a multivariate random variable with a known distribution.
In statistics, the Cochran–Mantel–Haenszel test (CMH) is a test used in the analysis of stratified or matched categorical data. It allows an investigator to test the association between a binary predictor or treatment and a binary outcome such as case or control status while taking into account the stratification. Unlike the McNemar test, which can only handle pairs, the CMH test handles arbitrary strata size. It is named after William G. Cochran, Nathan Mantel and William Haenszel. Extensions of this test to a categorical response and/or to several groups are commonly called Cochran–Mantel–Haenszel statistics. It is often used in observational studies where random assignment of subjects to different treatments cannot be controlled, but confounding covariates can be measured.
In statistics, Cramér's V is a measure of association between two nominal variables, giving a value between 0 and +1 (inclusive). It is based on Pearson's chi-squared statistic and was published by Harald Cramér in 1946.
In statistics, Tschuprow's T is a measure of association between two nominal variables, giving a value between 0 and 1 (inclusive). It is closely related to Cramér's V, coinciding with it for square contingency tables. It was published by Alexander Tschuprow in 1939.
Log-linear analysis is a technique used in statistics to examine the relationship between more than two categorical variables. The technique is used for both hypothesis testing and model building. In both these uses, models are tested to find the most parsimonious model that best accounts for the variance in the observed frequencies.
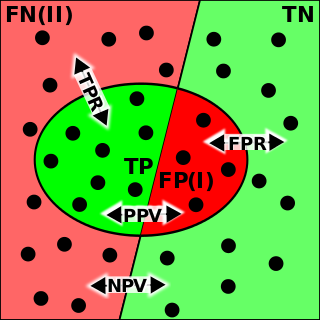
The evaluation of binary classifiers compares two methods of assigning a binary attribute, one of which is usually a standard method and the other is being investigated. There are many metrics that can be used to measure the performance of a classifier or predictor; different fields have different preferences for specific metrics due to different goals. For example, in medicine sensitivity and specificity are often used, while in computer science precision and recall are preferred. An important distinction is between metrics that are independent on the prevalence, and metrics that depend on the prevalence – both types are useful, but they have very different properties.
In statistics, Yule's Y, also known as the coefficient of colligation, is a measure of association between two binary variables. The measure was developed by George Udny Yule in 1912, and should not be confused with Yule's coefficient for measuring skewness based on quartiles.
Ordinal data is a categorical, statistical data type where the variables have natural, ordered categories and the distances between the categories are not known. These data exist on an ordinal scale, one of four levels of measurement described by S. S. Stevens in 1946. The ordinal scale is distinguished from the nominal scale by having a ranking. It also differs from the interval scale and ratio scale by not having category widths that represent equal increments of the underlying attribute.







