
The Cauchy distribution, named after Augustin Cauchy, is a continuous probability distribution. It is also known, especially among physicists, as the Lorentz distribution, Cauchy–Lorentz distribution, Lorentz(ian) function, or Breit–Wigner distribution. The Cauchy distribution is the distribution of the x-intercept of a ray issuing from with a uniformly distributed angle. It is also the distribution of the ratio of two independent normally distributed random variables with mean zero.

In probability theory and statistics, the negative binomial distribution is a discrete probability distribution that models the number of failures in a sequence of independent and identically distributed Bernoulli trials before a specified (non-random) number of successes occurs. For example, we can define rolling a 6 on a dice as a success, and rolling any other number as a failure, and ask how many failure rolls will occur before we see the third success. In such a case, the probability distribution of the number of failures that appear will be a negative binomial distribution.
In statistics, the Gauss–Markov theorem states that the ordinary least squares (OLS) estimator has the lowest sampling variance within the class of linear unbiased estimators, if the errors in the linear regression model are uncorrelated, have equal variances and expectation value of zero. The errors do not need to be normal, nor do they need to be independent and identically distributed. The requirement that the estimator be unbiased cannot be dropped, since biased estimators exist with lower variance. See, for example, the James–Stein estimator, ridge regression, or simply any degenerate estimator.

In probability theory and statistics, the gamma distribution is a two-parameter family of continuous probability distributions. The exponential distribution, Erlang distribution, and chi-squared distribution are special cases of the gamma distribution. There are two equivalent parameterizations in common use:
- With a shape parameter and a scale parameter .
- With a shape parameter and an inverse scale parameter , called a rate parameter.

In statistics, originally in geostatistics, kriging or Kriging, also known as Gaussian process regression, is a method of interpolation based on Gaussian process governed by prior covariances. Under suitable assumptions of the prior, kriging gives the best linear unbiased prediction (BLUP) at unsampled locations. Interpolating methods based on other criteria such as smoothness may not yield the BLUP. The method is widely used in the domain of spatial analysis and computer experiments. The technique is also known as Wiener–Kolmogorov prediction, after Norbert Wiener and Andrey Kolmogorov.
In statistics, a generalized linear model (GLM) is a flexible generalization of ordinary linear regression. The GLM generalizes linear regression by allowing the linear model to be related to the response variable via a link function and by allowing the magnitude of the variance of each measurement to be a function of its predicted value.
The Newmark-beta method is a method of numerical integration used to solve certain differential equations. It is widely used in numerical evaluation of the dynamic response of structures and solids such as in finite element analysis to model dynamic systems. The method is named after Nathan M. Newmark, former Professor of Civil Engineering at the University of Illinois at Urbana–Champaign, who developed it in 1959 for use in structural dynamics. The semi-discretized structural equation is a second order ordinary differential equation system,

Statistical learning theory is a framework for machine learning drawing from the fields of statistics and functional analysis. Statistical learning theory deals with the statistical inference problem of finding a predictive function based on data. Statistical learning theory has led to successful applications in fields such as computer vision, speech recognition, and bioinformatics.

In probability theory and statistics, the Laplace distribution is a continuous probability distribution named after Pierre-Simon Laplace. It is also sometimes called the double exponential distribution, because it can be thought of as two exponential distributions spliced together along the abscissa, although the term is also sometimes used to refer to the Gumbel distribution. The difference between two independent identically distributed exponential random variables is governed by a Laplace distribution, as is a Brownian motion evaluated at an exponentially distributed random time. Increments of Laplace motion or a variance gamma process evaluated over the time scale also have a Laplace distribution.
In probability theory and statistics, the generalized extreme value (GEV) distribution is a family of continuous probability distributions developed within extreme value theory to combine the Gumbel, Fréchet and Weibull families also known as type I, II and III extreme value distributions. By the extreme value theorem the GEV distribution is the only possible limit distribution of properly normalized maxima of a sequence of independent and identically distributed random variables. Note that a limit distribution needs to exist, which requires regularity conditions on the tail of the distribution. Despite this, the GEV distribution is often used as an approximation to model the maxima of long (finite) sequences of random variables.

In probability theory and statistics, the inverse gamma distribution is a two-parameter family of continuous probability distributions on the positive real line, which is the distribution of the reciprocal of a variable distributed according to the gamma distribution.

In probability and statistics, the Kumaraswamy's double bounded distribution is a family of continuous probability distributions defined on the interval (0,1). It is similar to the Beta distribution, but much simpler to use especially in simulation studies since its probability density function, cumulative distribution function and quantile functions can be expressed in closed form. This distribution was originally proposed by Poondi Kumaraswamy for variables that are lower and upper bounded with a zero-inflation. This was extended to inflations at both extremes [0,1] in later work with S. G. Fletcher.

In statistics and numerical analysis, isotonic regression or monotonic regression is the technique of fitting a free-form line to a sequence of observations such that the fitted line is non-decreasing everywhere, and lies as close to the observations as possible.
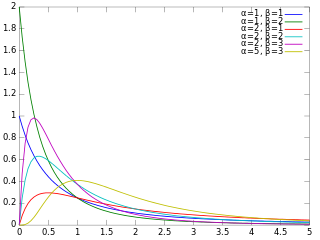
In probability theory and statistics, the beta prime distribution is an absolutely continuous probability distribution. If has a beta distribution, then the odds has a beta prime distribution.
In statistics, M-estimators are a broad class of extremum estimators for which the objective function is a sample average. Both non-linear least squares and maximum likelihood estimation are special cases of M-estimators. The definition of M-estimators was motivated by robust statistics, which contributed new types of M-estimators. However, M-estimators are not inherently robust, as is clear from the fact that they include maximum likelihood estimators, which are in general not robust. The statistical procedure of evaluating an M-estimator on a data set is called M-estimation.
The cross-entropy (CE) method is a Monte Carlo method for importance sampling and optimization. It is applicable to both combinatorial and continuous problems, with either a static or noisy objective.
In statistics, explained variation measures the proportion to which a mathematical model accounts for the variation (dispersion) of a given data set. Often, variation is quantified as variance; then, the more specific term explained variance can be used.

In probability and statistics, the log-logistic distribution is a continuous probability distribution for a non-negative random variable. It is used in survival analysis as a parametric model for events whose rate increases initially and decreases later, as, for example, mortality rate from cancer following diagnosis or treatment. It has also been used in hydrology to model stream flow and precipitation, in economics as a simple model of the distribution of wealth or income, and in networking to model the transmission times of data considering both the network and the software.
The Vanna–Volga method is a mathematical tool used in finance. It is a technique for pricing first-generation exotic options in foreign exchange market (FX) derivatives.
Inverse probability weighting is a statistical technique for calculating statistics standardized to a pseudo-population different from that in which the data was collected. Study designs with a disparate sampling population and population of target inference are common in application. There may be prohibitive factors barring researchers from directly sampling from the target population such as cost, time, or ethical concerns. A solution to this problem is to use an alternate design strategy, e.g. stratified sampling. Weighting, when correctly applied, can potentially improve the efficiency and reduce the bias of unweighted estimators.




























![Examples of UDD stationary distributions with
M
=
10
{\displaystyle M=10}
. Left: original ("classical") UDD,
x
*
=
5.6
{\displaystyle x^{*}=5.6}
. Right: biased-coin targeting the 30th percentile,
x
*
[?]
3.9.
{\displaystyle x^{*}\approx 3.9.} Pifig.pdf](http://upload.wikimedia.org/wikipedia/commons/thumb/1/1a/Pifig.pdf/page1-600px-Pifig.pdf.jpg)



























































