
In statistics, stratified sampling is a method of sampling from a population which can be partitioned into subpopulations.
The weighted arithmetic mean is similar to an ordinary arithmetic mean, except that instead of each of the data points contributing equally to the final average, some data points contribute more than others. The notion of weighted mean plays a role in descriptive statistics and also occurs in a more general form in several other areas of mathematics.
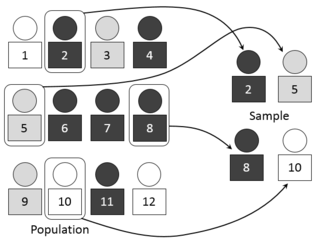
In statistics, multistage sampling is the taking of samples in stages using smaller and smaller sampling units at each stage.
In statistics, quality assurance, and survey methodology, sampling is the selection of a subset or a statistical sample of individuals from within a statistical population to estimate characteristics of the whole population. The subset is meant to reflect the whole population and statisticians attempt to collect samples that are representative of the population. Sampling has lower costs and faster data collection compared to recording data from the entire population, and thus, it can provide insights in cases where it is infeasible to measure an entire population.

In statistics, the Pearson correlation coefficient (PCC) is a correlation coefficient that measures linear correlation between two sets of data. It is the ratio between the covariance of two variables and the product of their standard deviations; thus, it is essentially a normalized measurement of the covariance, such that the result always has a value between −1 and 1. As with covariance itself, the measure can only reflect a linear correlation of variables, and ignores many other types of relationships or correlations. As a simple example, one would expect the age and height of a sample of children from a primary school to have a Pearson correlation coefficient significantly greater than 0, but less than 1.

The standard error (SE) of a statistic is the standard deviation of its sampling distribution or an estimate of that standard deviation. If the statistic is the sample mean, it is called the standard error of the mean (SEM). The standard error is a key ingredient in producing confidence intervals.
In statistics, sometimes the covariance matrix of a multivariate random variable is not known but has to be estimated. Estimation of covariance matrices then deals with the question of how to approximate the actual covariance matrix on the basis of a sample from the multivariate distribution. Simple cases, where observations are complete, can be dealt with by using the sample covariance matrix. The sample covariance matrix (SCM) is an unbiased and efficient estimator of the covariance matrix if the space of covariance matrices is viewed as an extrinsic convex cone in Rp×p; however, measured using the intrinsic geometry of positive-definite matrices, the SCM is a biased and inefficient estimator. In addition, if the random variable has a normal distribution, the sample covariance matrix has a Wishart distribution and a slightly differently scaled version of it is the maximum likelihood estimate. Cases involving missing data, heteroscedasticity, or autocorrelated residuals require deeper considerations. Another issue is the robustness to outliers, to which sample covariance matrices are highly sensitive.
This glossary of statistics and probability is a list of definitions of terms and concepts used in the mathematical sciences of statistics and probability, their sub-disciplines, and related fields. For additional related terms, see Glossary of mathematics and Glossary of experimental design.
In statistics, resampling is the creation of new samples based on one observed sample. Resampling methods are:
- Permutation tests
- Bootstrapping
- Cross validation
- Jackknife
Bootstrapping is a procedure for estimating the distribution of an estimator by resampling one's data or a model estimated from the data. Bootstrapping assigns measures of accuracy to sample estimates. This technique allows estimation of the sampling distribution of almost any statistic using random sampling methods.
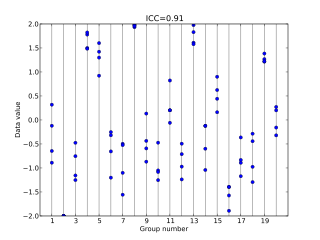
In statistics, the intraclass correlation, or the intraclass correlation coefficient (ICC), is a descriptive statistic that can be used when quantitative measurements are made on units that are organized into groups. It describes how strongly units in the same group resemble each other. While it is viewed as a type of correlation, unlike most other correlation measures, it operates on data structured as groups rather than data structured as paired observations.
Forest inventory is the systematic collection of data and forest information for assessment or analysis. An estimate of the value and possible uses of timber is an important part of the broader information required to sustain ecosystems. When taking forest inventory the following are important things to measure and note: species, diameter at breast height (DBH), height, site quality, age, and defects. From the data collected one can calculate the number of trees per acre, the basal area, the volume of trees in an area, and the value of the timber. Inventories can be done for other reasons than just calculating the value. A forest can be cruised to visually assess timber and determine potential fire hazards and the risk of fire. The results of this type of inventory can be used in preventive actions and also awareness. Wildlife surveys can be undertaken in conjunction with timber inventory to determine the number and type of wildlife within a forest. The aim of the statistical forest inventory is to provide comprehensive information about the state and dynamics of forests for strategic and management planning. Merely looking at the forest for assessment is called taxation.
The Heckman correction is a statistical technique to correct bias from non-randomly selected samples or otherwise incidentally truncated dependent variables, a pervasive issue in quantitative social sciences when using observational data. Conceptually, this is achieved by explicitly modelling the individual sampling probability of each observation together with the conditional expectation of the dependent variable. The resulting likelihood function is mathematically similar to the tobit model for censored dependent variables, a connection first drawn by James Heckman in 1974. Heckman also developed a two-step control function approach to estimate this model, which avoids the computational burden of having to estimate both equations jointly, albeit at the cost of inefficiency. Heckman received the Nobel Memorial Prize in Economic Sciences in 2000 for his work in this field.
In statistics, a simple random sample is a subset of individuals chosen from a larger set in which a subset of individuals are chosen randomly, all with the same probability. It is a process of selecting a sample in a random way. In SRS, each subset of k individuals has the same probability of being chosen for the sample as any other subset of k individuals. Simple random sampling is a basic type of sampling and can be a component of other more complex sampling methods.
In survey research, the design effect is a number that shows how well a sample of people may represent a larger group of people for a specific measure of interest. This is important when the sample comes from a sampling method that is different than just picking people using a simple random sample.
In statistics, the Horvitz–Thompson estimator, named after Daniel G. Horvitz and Donovan J. Thompson, is a method for estimating the total and mean of a pseudo-population in a stratified sample by applying inverse probability weighting to account for the difference in the sampling distribution between the collected data and the a target population. The Horvitz–Thompson estimator is frequently applied in survey analyses and can be used to account for missing data, as well as many sources of unequal selection probabilities.
The ratio estimator is a statistical estimator for the ratio of means of two random variables. Ratio estimates are biased and corrections must be made when they are used in experimental or survey work. The ratio estimates are asymmetrical and symmetrical tests such as the t test should not be used to generate confidence intervals.
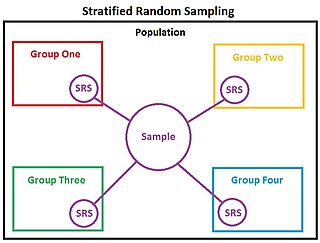
In statistics, stratified randomization is a method of sampling which first stratifies the whole study population into subgroups with same attributes or characteristics, known as strata, then followed by simple random sampling from the stratified groups, where each element within the same subgroup are selected unbiasedly during any stage of the sampling process, randomly and entirely by chance. Stratified randomization is considered a subdivision of stratified sampling, and should be adopted when shared attributes exist partially and vary widely between subgroups of the investigated population, so that they require special considerations or clear distinctions during sampling. This sampling method should be distinguished from cluster sampling, where a simple random sample of several entire clusters is selected to represent the whole population, or stratified systematic sampling, where a systematic sampling is carried out after the stratification process.

In statistics, a sequence of random variables is homoscedastic if all its random variables have the same finite variance; this is also known as homogeneity of variance. The complementary notion is called heteroscedasticity, also known as heterogeneity of variance. The spellings homoskedasticity and heteroskedasticity are also frequently used. Skedasticity comes from the Ancient Greek word skedánnymi, meaning “to scatter”. Assuming a variable is homoscedastic when in reality it is heteroscedastic results in unbiased but inefficient point estimates and in biased estimates of standard errors, and may result in overestimating the goodness of fit as measured by the Pearson coefficient.




