An m × n matrix: the m rows are horizontal and the n columns are vertical. Each element of a matrix is often denoted by a variable with two subscripts. For example, a2,1 represents the element at the second row and first column of the matrix.
For example, denotes a matrix with two rows and three columns. This is often referred to as a "two-by-three matrix", a 2 × 3 matrix, or a matrix of dimension 2 × 3.
In linear algebra, matrices are used as linear maps. In geometry, matrices are used for geometric transformations (for example rotations) and coordinate changes. In numerical analysis, many computational problems are solved by reducing them to a matrix computation, and this often involves computing with matrices of huge dimensions. Matrices are used in most areas of mathematics and scientific fields, either directly, or through their use in geometry and numerical analysis.
Square matrices, matrices with the same number of rows and columns, play a major role in matrix theory. The determinant of a square matrix is a number associated with the matrix, which is fundamental for the study of a square matrix; for example, a square matrix is invertible if and only if it has a nonzero determinant and the eigenvalues of a square matrix are the roots of its characteristic polynomial, .
A matrix is a rectangular array of numbers (or other mathematical objects), called the "entries" of the matrix. Matrices are subject to standard operations such as addition and multiplication.[1] Most commonly, a matrix over a field is a rectangular array of elements of .[2][3] A real matrix and a complex matrix are matrices whose entries are respectively real numbers or complex numbers. More general types of entries are discussed below. For instance, this is a real matrix:
The numbers (or other objects) in the matrix are called its entries or its elements. The horizontal and vertical lines of entries in a matrix are respectively called rows and columns.[4]
Size
The size of a matrix is defined by the number of rows and columns it contains. There is no limit to the number of rows and columns that a matrix (in the usual sense) can have as long as they are positive integers. A matrix with m rows and n columns is called an m × n matrix,[4] or m-by-n matrix,[5] where m and n are called its dimensions.[6] For example, the matrix above is a 3 × 2 matrix.
Matrices with a single row are called row matrices or row vectors, and those with a single column are called column matrices or column vectors. A matrix with the same number of rows and columns is called a square matrix.[7] A matrix with an infinite number of rows or columns (or both) is called an infinite matrix. In some contexts, such as computer algebra programs, it is useful to consider a matrix with no rows or no columns, called an empty matrix.[8]
The specifics of symbolic matrix notation vary widely, with some prevailing trends. Matrices are commonly written in square brackets or parentheses,[9] so that an m × n matrix is represented as This may be abbreviated by writing only a single generic term, possibly along with indices, as in or in the case that .
Matrices are usually symbolized using upper-case letters (such as in the examples above),[10] while the corresponding lower-case letters, with two subscript indices (e.g., , or ), represent the entries.[11] In addition to using upper-case letters to symbolize matrices, many authors use a special typographical style, commonly boldface roman (non-italic), to further distinguish matrices from other mathematical objects. An alternative notation involves the use of a double-underline with the variable name, with or without boldface style, as in .[12]
The entry in the ith row and jth column of a matrix A is sometimes referred to as the or entry of the matrix, and commonly denoted by or .[13] Alternative notations for that entry are and . For example, the entry of the following matrix is 5 (also denoted , , or ):
Sometimes, the entries of a matrix can be defined by a formula such as . For example, each of the entries of the following matrix is determined by the formula . In this case, the matrix itself is sometimes defined by that formula, within square brackets or double parentheses. For example, the matrix above is defined as or . If matrix size is m × n, the above-mentioned formula is valid for any and any . This can be specified separately or indicated using m × n as a subscript. For instance, the matrix above is 3 × 4, and can be defined as or .
Some programming languages utilize doubly subscripted arrays (or arrays of arrays) to represent an {m-by-n matrix. Some programming languages start the numbering of array indexes at zero, in which case the entries of an m × n matrix are indexed by and .[14] This article follows the more common convention in mathematical writing where enumeration starts from 1.
The set of all m-by-n real matrices is often denoted , or . The set of all m × n matrices over another field, or over a ringR, is similarly denoted , or . If m = n, such as in the case of square matrices, one does not repeat the dimension: , or .[15] Often, , or , is used in place of .[16]
Basic operations
Several basic operations can be applied to matrices. Some, such as transposition and submatrix do not depend on the nature of the entries. Others, such as matrix addition, scalar multiplication, matrix multiplication, and row operations involve operations on matrix entries and therefore require that matrix entries are numbers or belong to a field or a ring.[17]
In this section, it is supposed that matrix entries belong to a fixed ring, which is typically a field of numbers.
Matrix addition and subtraction require matrices of a consistent size, and are calculated entrywise. The sumA + B and the difference A − B of two m × n matrices are:[18]
For example,
Familiar properties of numbers extend to these operations on matrices: for example, addition is commutative, that is, the matrix sum does not depend on the order of the summands: A + B = B + A.[19]
The product cA of a number c (also called a scalar in this context) and a matrix A is computed by multiplying each entry of A by c:[20] This operation is called scalar multiplication, but its result is not named "scalar product" to avoid confusion, since "scalar product" is often used as a synonym for "inner product".[21] For example:
Matrix subtraction is consistent with composition of matrix addition with scalar multiplication by –1:[22]
Schematic depiction of the matrix product AB of two matrices A and B
Multiplication of two matrices corresponds to the composition of linear transformations represented by each matrix. It is defined if and only if the number of columns of the left matrix is the same as the number of rows of the right matrix. If A is an m × n matrix and B is an n × p matrix, then their matrix productAB is the m × p matrix whose entries are given by the dot product of the corresponding row of A and the corresponding column of B:[24] where 1 ≤ i ≤ m and 1 ≤ j ≤ p.[25] For example, the underlined entry 2340 in the product is calculated as (2 × 1000) + (3 × 100) + (4 × 10) = 2340:
Matrix multiplication satisfies the rules (AB)C = A(BC) (associativity), and (A + B)C = AC + BC as well as C(A + B) = CA + CB (left and right distributivity), whenever the size of the matrices is such that the various products are defined.[26] The product AB may be defined without BA being defined, namely if A and B are m × n and n × k matrices, respectively, and m ≠ k. Even if both products are defined, they generally need not be equal, that is:[27]
In other words, matrix multiplication is not commutative, in marked contrast to (rational, real, or complex) numbers, whose product is independent of the order of the factors.[24] An example of two matrices not commuting with each other is: whereas
Besides the ordinary matrix multiplication just described, other less frequently used operations on matrices that can be considered forms of multiplication also exist, such as the Hadamard product and the Kronecker product.[28] They arise in solving matrix equations such as the Sylvester equation.[29]
A submatrix of a matrix is a matrix obtained by deleting any collection of rows or columns or both.[33][34][35] For example, from the following 3 × 4 matrix, we can construct a 2 × 3 submatrix by removing row 3 and column 2:
The minors and cofactors of a matrix are found by computing the determinant of certain submatrices.[35][36]
A principal submatrix is a square submatrix obtained by removing certain rows and columns. The definition varies from author to author. According to some authors, a principal submatrix is a submatrix in which the set of row indices that remain is the same as the set of column indices that remain.[37][38] Other authors define a principal submatrix as one in which the first k rows and columns, for some number k, are the ones that remain;[39] this type of submatrix has also been called a leading principal submatrix.[40]
Matrices can be used to compactly write and work with multiple linear equations, that is, systems of linear equations. For example, if A is an m × n matrix, x designates a column vector (that is, n × 1 matrix) of n variables x1, x2, ..., xn, and b is an m × 1 column vector, then the matrix equation is equivalent to the system of linear equations[41]
Using matrices, this can be solved more compactly than would be possible by writing out all the equations separately. If n = m and the equations are independent, then this can be done by writing[42] where A−1 is the inverse matrix of A. If A has no inverse, solutions—if any—can be found using its generalized inverse.[43]
The vectors represented by a 2 × 2 matrix correspond to the sides of a unit square transformed into a parallelogram.
Matrices and matrix multiplication reveal their essential features when related to linear transformations, also known as linear maps. A real m-by-n matrix A gives rise to a linear transformation mapping each vector x in to the (matrix) product Ax, which is a vector in Conversely, each linear transformation arises from a unique m-by-n matrix A: explicitly, the (i, j)-entry of A is the ith coordinate of f(ej), where ej = (0, ..., 0, 1, 0, ..., 0) is the unit vector with 1 in the jth position and 0 elsewhere. The matrix A is said to represent the linear map f, and A is called the transformation matrix of f.[44]
For example, the 2 × 2 matrix can be viewed as the transform of the unit square into a parallelogram with vertices at (0, 0), (a, b), (a + c, b + d), and (c, d). The parallelogram pictured at the right is obtained by multiplying A with each of the column vectors , , , and in turn. These vectors define the vertices of the unit square.[45] The following table shows several 2 × 2 real matrices with the associated linear maps of . The blue original is mapped to the green grid and shapes. The origin (0, 0) is marked with a black point.
Under the 1-to-1 correspondence between matrices and linear maps, matrix multiplication corresponds to composition of maps:[50] if a k-by-m matrix B represents another linear map , then the composition g ∘ f is represented by BA since[51]
The last equality follows from the above-mentioned associativity of matrix multiplication.
The rank of a matrixA is the maximum number of linearly independent row vectors of the matrix, which is the same as the maximum number of linearly independent column vectors.[52] Equivalently it is the dimension of the image of the linear map represented by A.[53] The rank–nullity theorem states that the dimension of the kernel of a matrix plus the rank equals the number of columns of the matrix.[54]
A square matrix is a matrix with the same number of rows and columns. An n-by-n matrix is known as a square matrix of order n. Any two square matrices of the same order can be added and multiplied. The entries aii form the main diagonal of a square matrix. They lie on the imaginary line running from the top left corner to the bottom right corner of the matrix.[55]
Square matrices of a given dimension form a noncommutative ring, which is one of the most common examples of a noncommutative ring.[56]
If all entries of A below the main diagonal are zero, A is called an upper triangular matrix. Similarly, if all entries of A above the main diagonal are zero, A is called a lower triangular matrix.[57] If all entries outside the main diagonal are zero, A is called a diagonal matrix.[58]
The identity matrixIn of size n is the n-by-n matrix in which all the elements on the main diagonal are equal to 1 and all other elements are equal to 0,[59] for example, It is a square matrix of order n, and also a special kind of diagonal matrix. It is called an identity matrix because multiplication with it leaves a matrix unchanged:[59] for any m-by-n matrix A.
A scalar multiple of an identity matrix is called a scalar matrix.[60]
Symmetric or skew-symmetric matrix
A square matrix A that is equal to its transpose, that is, A = AT, is a symmetric matrix. If instead, A is equal to the negative of its transpose, that is, A = −AT, then A is a skew-symmetric matrix. In complex matrices, symmetry is often replaced by the concept of Hermitian matrices, which satisfies A∗ = A, where the star or asterisk denotes the conjugate transpose of the matrix, that is, the transpose of the complex conjugate of A.[61]
By the spectral theorem, real symmetric matrices and complex Hermitian matrices have an eigenbasis; that is, every vector is expressible as a linear combination of eigenvectors. In both cases, all eigenvalues are real.[62] This theorem can be generalized to infinite-dimensional situations related to matrices with infinitely many rows and columns.[63]
Invertible matrix and its inverse
A square matrix A is called invertible or non-singular if there exists a matrix B such that[64][65] where In is the n × nidentity matrix with 1 for each entry on the main diagonal and 0 elsewhere. If B exists, it is unique and is called the inverse matrix of A, denoted A−1.[66]
There are many algorithms for testing whether a square matrix is invertible, and, if it is, computing its inverse. One of the oldest, which is still in common use is Gaussian elimination.[67]
A symmetric real matrix A is called positive-definite if the associated quadratic form has a positive value for every nonzero vector x in . If f(x) yields only negative values then A is negative-definite; if f does produce both negative and positive values then A is indefinite.[68] If the quadratic form f yields only non-negative values (positive or zero), the symmetric matrix is called positive-semidefinite (or if only non-positive values, then negative-semidefinite); hence the matrix is indefinite precisely when it is neither positive-semidefinite nor negative-semidefinite.[69]
A symmetric matrix is positive-definite if and only if all its eigenvalues are positive, that is, the matrix is positive-semidefinite and it is invertible.[70] The table at the right shows two possibilities for 2-by-2 matrices. The eigenvalues of a diagonal matrix are simply the entries along the diagonal,[71] and so in these examples, the eigenvalues can be read directly from the matrices themselves. The first matrix has two eigenvalues that are both positive, while the second has one that is positive and another that is negative.
Allowing as input two different vectors instead yields the bilinear form associated to A:[72]
An orthogonal matrix A is necessarily invertible (with inverse A−1 = AT), unitary (A−1 = A*), and normal (A*A = AA*). The determinant of any orthogonal matrix is either +1 or −1. A special orthogonal matrix is an orthogonal matrix with determinant+1. As a linear transformation, every orthogonal matrix with determinant +1 is a pure rotation without reflection, i.e., the transformation preserves the orientation of the transformed structure, while every orthogonal matrix with determinant −1 reverses the orientation, i.e., is a composition of a pure reflection and a (possibly null) rotation. The identity matrices have determinant 1 and are pure rotations by an angle zero.[76]
The trace, tr(A) of a square matrix A is the sum of its diagonal entries. While matrix multiplication is not commutative as mentioned above, the trace of the product of two matrices is independent of the order of the factors:[78] This is immediate from the definition of matrix multiplication:[79] It follows that the trace of the product of more than two matrices is independent of cyclic permutations of the matrices; however, this does not in general apply for arbitrary permutations. For example, tr(ABC) ≠ tr(BAC), in general.[80] Also, the trace of a matrix is equal to that of its transpose,[81] that is,
A linear transformation on given by the indicated matrix. The determinant of this matrix is −1, as the area of the green parallelogram at the right is 1, but the map reverses the orientation, since it turns the counterclockwise orientation of the vectors to a clockwise one.
The determinant of a square matrix A (denoted det(A) or |A|) is a number encoding certain properties of the matrix. A matrix is invertible if and only if its determinant is nonzero.[82] Its absolute value equals the area (in ) or volume (in ) of the image of the unit square (or cube), while its sign corresponds to the orientation of the corresponding linear map: the determinant is positive if and only if the orientation is preserved.[83]
The determinant of 2 × 2 matrices is given by[84] The determinant of 3 × 3 matrices involves six terms (rule of Sarrus). The more lengthy Leibniz formula generalizes these two formulae to all dimensions.[85]
The determinant of a product of square matrices equals the product of their determinants: or using alternate notation:[86] Adding a multiple of any row to another row, or a multiple of any column to another column, does not change the determinant. Interchanging two rows or two columns affects the determinant by multiplying it by −1.[87] Using these operations, any matrix can be transformed to a lower (or upper) triangular matrix, and for such matrices, the determinant equals the product of the entries on the main diagonal; this provides a method to calculate the determinant of any matrix. Finally, the Laplace expansion expresses the determinant in terms of minors, that is, determinants of smaller matrices.[88] This expansion can be used for a recursive definition of determinants (taking as starting case the determinant of a 1 × 1 matrix, which is its unique entry, or even the determinant of a 0 × 0 matrix, which is 1), that can be seen to be equivalent to the Leibniz formula. Determinants can be used to solve linear systems using Cramer's rule, where the division of the determinants of two related square matrices equates to the value of each of the system's variables.[89]
A number and a nonzero vector v satisfying are called an eigenvalue and an eigenvector of A, respectively.[90][91] The number λ is an eigenvalue of an n × n matrix A if and only if (A − λIn) is not invertible, which is equivalent to[92] The polynomial pA in an indeterminateX given by evaluation of the determinant det(XIn − A) is called the characteristic polynomial of A. It is a monic polynomial of degreen. Therefore the polynomial equation pA(λ) = 0 has at most n different solutions, that is, eigenvalues of the matrix.[93] They may be complex even if the entries of A are real.[94] According to the Cayley–Hamilton theorem, pA(A) = 0, that is, the result of substituting the matrix itself into its characteristic polynomial yields the zero matrix.[95]
Computational aspects
Matrix calculations can be often performed with different techniques. Many problems can be solved by both direct algorithms and iterative approaches. For example, the eigenvectors of a square matrix can be obtained by finding a sequence of vectors xnconverging to an eigenvector when n tends to infinity.[96]
To choose the most appropriate algorithm for each specific problem, it is important to determine both the effectiveness and precision of all the available algorithms. The domain studying these matters is called numerical linear algebra.[97] As with other numerical situations, two main aspects are the complexity of algorithms and their numerical stability.
Determining the complexity of an algorithm means finding upper bounds or estimates of how many elementary operations such as additions and multiplications of scalars are necessary to perform some algorithm, for example, multiplication of matrices. Calculating the matrix product of two n-by-n matrices using the definition given above needs n3 multiplications, since for any of the n2 entries of the product, n multiplications are necessary. The Strassen algorithm outperforms this "naive" algorithm; it needs only n2.807 multiplications.[98] Theoretically faster but impractical matrix multiplication algorithms have been developed,[99] as have speedups to this problem using parallel algorithms or distributed computation systems such as MapReduce.[100]
In many practical situations, additional information about the matrices involved is known. An important case concerns sparse matrices, that is, matrices whose entries are mostly zero. There are specifically adapted algorithms for, say, solving linear systems Ax = b for sparse matrices A, such as the conjugate gradient method.[101]
An algorithm is, roughly speaking, numerically stable if little deviations in the input values do not lead to big deviations in the result. For example, one can calculate the inverse of a matrix by computing its adjugate matrix: However, this may lead to significant rounding errors if the determinant of the matrix is very small. The norm of a matrix can be used to capture the conditioning of linear algebraic problems, such as computing a matrix's inverse.[102]
There are several methods to render matrices into a more easily accessible form. They are generally referred to as matrix decomposition or matrix factorization techniques. These techniques are of interest because they can make computations easier.
The LU decomposition factors matrices as a product of lower (L) and an upper triangular matrices (U).[103] Once this decomposition is calculated, linear systems can be solved more efficiently by a simple technique called forward and back substitution. Likewise, inverses of triangular matrices are algorithmically easier to calculate. The Gaussian elimination is a similar algorithm; it transforms any matrix to row echelon form.[104] Both methods proceed by multiplying the matrix by suitable elementary matrices, which correspond to permuting rows or columns and adding multiples of one row to another row. Singular value decomposition (SVD) expresses any matrix A as a product UDV∗, where U and V are unitary matrices and D is a diagonal matrix.[105]
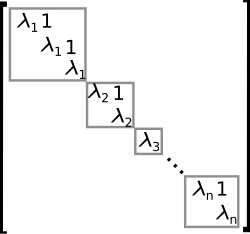
An example of a matrix in Jordan normal form. The grey blocks are called Jordan blocks.
The eigendecomposition or diagonalization expresses A as a product VDV−1, where D is a diagonal matrix and V is a suitable invertible matrix.[106] If A can be written in this form, it is called diagonalizable. More generally, and applicable to all matrices, the Jordan decomposition transforms a matrix into Jordan normal form, that is to say matrices whose only nonzero entries are the eigenvalues λ1 to λn of A, placed on the main diagonal and possibly entries equal to one directly above the main diagonal, as shown at the right.[107] Given the eigendecomposition, the nth power of A (that is, n-fold iterated matrix multiplication) can be calculated via and the power of a diagonal matrix can be calculated by taking the corresponding powers of the diagonal entries, which is much easier than doing the exponentiation for A instead. This can be used to compute the matrix exponentialeA, a need frequently arising in solving linear differential equations, matrix logarithms and square roots of matrices.[108] To avoid numerically ill-conditioned situations, further algorithms such as the Schur decomposition can be employed.[109]
Abstract algebraic aspects and generalizations
Matrices can be generalized in different ways. Abstract algebra uses matrices with entries in more general fields or even rings, while linear algebra codifies properties of matrices in the notion of linear maps. It is possible to consider matrices with infinitely many columns and rows. Another extension is tensors, which can be seen as higher-dimensional arrays of numbers, as opposed to vectors, which can often be realized as sequences of numbers, while matrices are rectangular or two-dimensional arrays of numbers.[110] Matrices, subject to certain requirements tend to form groups known as matrix groups.[111] Similarly under certain conditions matrices form rings known as matrix rings.[112] Though the product of matrices is not in general commutative, certain matrices form fields sometimes called matrix fields.[113] (However the term "matrix field" is ambiguous, also referring to certain forms of physical fields that continuously map points of some space to matrices.[114]) In general, matrices over any ring and their multiplication can be represented as the arrows and composition of arrows in a category, the category of matrices over that ring. The objects of this category are natural numbers, representing the dimensions of the matrices.[115]
Matrices with entries in a field or ring
This article focuses on matrices whose entries are real or complex numbers. However, matrices can be considered with much more general types of entries than real or complex numbers. As a first step of generalization, any field, that is, a set where addition, subtraction, multiplication, and division operations are defined and well-behaved, may be used instead of or , for example rational numbers or finite fields. For example, coding theory makes use of matrices over finite fields.[116] Wherever eigenvalues are considered, as these are roots of a polynomial, they may exist only in a larger field than that of the entries of the matrix. For instance, they may be complex in the case of a matrix with real entries. The possibility to reinterpret the entries of a matrix as elements of a larger field (for example, to view a real matrix as a complex matrix whose entries happen to be all real) then allows considering each square matrix to possess a full set of eigenvalues.[117] Alternatively one can consider only matrices with entries in an algebraically closed field, such as from the outset.[118]
Matrices whose entries are polynomials,[119] and more generally, matrices with entries in a ringR are widely used in mathematics.[1] Rings are a more general notion than fields in that a division operation need not exist. The very same addition and multiplication operations of matrices extend to this setting, too. The set M(n, R) (also denoted Mn(R)[15]) of all square n-by-n matrices over R is a ring called matrix ring, isomorphic to the endomorphism ring of the left R-moduleRn.[120] If the ring R is commutative, that is, its multiplication is commutative, then the ring M(n, R) is also an associative algebra over R. The determinant of square matrices over a commutative ring R can still be defined using the Leibniz formula; such a matrix is invertible if and only if its determinant is invertible in R, generalizing the situation over a field F, where every nonzero element is invertible.[121] Matrices over superrings are called supermatrices.[122]
Matrices do not always have all their entries in the same ring– or even in any ring at all. One special but common case is block matrices, which may be considered as matrices whose entries themselves are matrices. The entries need not be square matrices, and thus need not be members of any ring; but in order to multiply them, their sizes must fulfill certain conditions: each pair of submatrices that are multiplied in forming the overall product must have compatible sizes.[123]
Relationship to linear maps
Linear maps are equivalent to m-by-n matrices, as described above. More generally, any linear map f: V → W between finite-dimensionalvector spaces can be described by a matrix A = (aij), after choosing basesv1, ..., vn of V, and w1, ..., wm of W (so n is the dimension of V and m is the dimension of W), which is such that In other words, column j of A expresses the image of vj in terms of the basis vectors wi of W; thus this relation uniquely determines the entries of the matrix A. The matrix depends on the choice of the bases: different choices of bases give rise to different, but equivalent matrices.[124] Many of the above concrete notions can be reinterpreted in this light, for example, the transpose matrix AT describes the transpose of the linear map given by A, concerning the dual bases.[125]
These properties can be restated more naturally: the category of matrices with entries in a field with multiplication as composition is equivalent to the category of finite-dimensional vector spaces and linear maps over this field.[126]
More generally, the set of m × n matrices can be used to represent the R-linear maps between the free modules Rm and Rn for an arbitrary ring R with unity. When n = m composition of these maps is possible, and this gives rise to the matrix ring of n × n matrices representing the endomorphism ring of Rn.[127]
A group is a mathematical structure consisting of a set of objects together with a binary operation, that is, an operation combining any two objects to a third, subject to certain requirements.[128] A group in which the objects are invertible matrices and the group operation is matrix multiplication is called a matrix group of degree .[129] Every such matrix group is a subgroup of (that is, a smaller group contained within) the group of all invertible matrices, the general linear group of degree .[130]
Any property of square matrices that is preserved under matrix products and inverses can be used to define a matrix group. For example, the set of all matrices whose determinant is 1 form a group called the special linear group of degree .[131] The set of orthogonal matrices, determined by the condition form the orthogonal group.[132] Every orthogonal matrix has determinant1 or −1. Orthogonal matrices with determinant 1 form a group called the special orthogonal group.[133]
It is also possible to consider matrices with infinitely many rows and columns.[136] The basic operations introduced above are defined the same way in this case. Matrix multiplication, however, and all operations stemming therefrom are only meaningful when restricted to certain matrices, since the sum featuring in the above definition of the matrix product will contain an infinity of summands.[137] An easy way to circumvent this issue is to restrict to finitary matrices all of whose rows (or columns) contain only finitely many nonzero terms.[138] As in the finite case (see above), where matrices describe linear maps, infinite matrices can be used to describe operators on Hilbert spaces, where convergence and continuity questions arise. However, the explicit point of view of matrices tends to obfuscate the matter,[139] and the abstract and more powerful tools of functional analysis are used instead, by relating matrices to linear maps (as in the finite case above), but imposing additional convergence and continuity constraints.
Empty matrix
An empty matrix is a matrix in which the number of rows or columns (or both) is zero.[140][8] Empty matrices can be a useful base case for certain recursive constructions,[141] and can help to deal with maps involving the zero vector space.[142] For example, if A is a 3 × 0 matrix and B is a 0 × 3 matrix, then AB is the 3 × 3zero matrix corresponding to the null map from a 3-dimensional space V to itself, while BA is a 0 × 0 matrix. There is no common notation for empty matrices, but most computer algebra systems allow creating and computing with them.[143] The determinant of the 0 × 0 matrix is conventionally defined to be 1, consistent with the empty product occurring in the Leibniz formula for the determinant.[144] This value is also needed for consistency with the 2 × 2 case of the Desnanot–Jacobi identity relating determinants to the determinants of smaller matrices.[145]
Matrices with entries in a semiring
A semiring is similar to a ring, but elements need not have additive inverses, therefore one cannot do subtraction freely there. The definition of addition and multiplication of matrices with entries in a ring applies to matrices with entries in a semiring without modification. Matrices of fixed size with entries in a semiring form a commutative monoid under addition.[146] Square matrices of fixed size with entries in a semiring form a semiring under addition and multiplication.[146]
The determinant of an n × n square matrix with entries in a commutative semiring cannot be defined in general because the definition would involve additive inverses of semiring elements. What plays its role instead is the pair of positive and negative determinants
Matrices and their multiplication can be defined with entries objects of a category equipped with a "tensor product" similar to multiplication in a ring, having coproducts similar to addition in a ring, in that the former is distributive over the latter.[149] However, the multiplication thus defined may be only associative in a sense weaker than usual. These are part of a bigger structure called the bicategory of matrices. The complete description of the above summary for interested readers follows.
The functor is distributive over coproducts; i.e., for all object and a family of objects in , the canonical -morphisms are isomorphisms. In particular, the canonical morphisms and are isomorphisms.
A 1-morphism is a map ; this is just a matrix over .
The composition of 1-morphisms and , which can be understood as matrix multiplication, is
The identity 1-morphism on is
A 2-morphism between 1-morphisms is a family of -morphisms . The definition of vertical and horizontal composition of 2-morphisms is natural: the vertical composition is componentwise composition of -morphisms; the horizontal composition is that derived from the functoriality of and the universal property of coproducts.
In general, the bicategory of matrices need not be a strict 2-category. For example, the composition of 1-morphisms may not be associative in the usual strict sense, but only up to coherent isomorphism.
Applications
There are numerous applications of matrices, both in mathematics and other sciences. Some of them merely take advantage of the compact representation of a set of numbers in a matrix. For example, Text mining and automated thesaurus compilation makes use of document-term matrices such as tf-idf to track frequencies of certain words in several documents.[150]
Complex numbers can be represented by particular real 2-by-2 matrices via under which addition and multiplication of complex numbers and matrices correspond to each other. For example, 2-by-2 rotation matrices represent the multiplication with some complex number of absolute value 1, as above. A similar interpretation is possible for quaternions[151] and Clifford algebras in general.[152]
In game theory and economics, the payoff matrix encodes the payoff for two players, depending on which out of a given (finite) set of strategies the players choose.[153] The expected outcome of the game, when both players play mixed strategies, is obtained by multiplying this matrix on both sides by vectors representing the strategies.[154] The minimax theorem central to game theory is closely related to the duality theory of linear programs, which are often formulated in terms of matrix-vector products.[155]
Early encryption techniques such as the Hill cipher also used matrices. However, due to the linear nature of matrices, these codes are comparatively easy to break.[156]Computer graphics uses matrices to represent objects; to calculate transformations of objects using affine rotation matrices to accomplish tasks such as projecting a three-dimensional object onto a two-dimensional screen, corresponding to a theoretical camera observation; and to apply image convolutions such as sharpening, blurring, edge detection, and more.[157] Matrices over a polynomial ring are important in the study of control theory.[158]
The adjacency matrix of a finite graph is a basic notion of graph theory.[160] It records which vertices of the graph are connected by an edge. Matrices containing just two different values (1 and 0 meaning for example "yes" and "no", respectively) are called logical matrices. The distance (or cost) matrix contains information about the distances of the edges.[161] These concepts can be applied to websites connected by hyperlinks,[162] or cities connected by roads etc., in which case (unless the connection network is extremely dense) the matrices tend to be sparse, that is, contain few nonzero entries. Therefore, specifically tailored matrix algorithms can be used in network theory.[163]
At the saddle point(x = 0, y = 0) (red) of the function f(x,−y) = x − y, the Hessian matrix is indefinite.
It encodes information about the local growth behavior of the function: given a critical pointx = (x1, ..., xn), that is, a point where the first partial derivatives of f vanish, the function has a local minimum if the Hessian matrix is positive definite. Quadratic programming can be used to find global minima or maxima of quadratic functions closely related to the ones attached to matrices (see above).[165]
Another matrix frequently used in geometrical situations is the Jacobi matrix of a differentiable map . If f1, ..., fm denote the components of f, then the Jacobi matrix is defined as[166] If n > m, and if the rank of the Jacobi matrix attains its maximal value m, f is locally invertible at that point, by the implicit function theorem.[167]
Partial differential equations can be classified by considering the matrix of coefficients of the highest-order differential operators of the equation. For elliptic partial differential equations this matrix is positive definite, which has a decisive influence on the set of possible solutions of the equation in question.[168]
The finite element method is an important numerical method to solve partial differential equations, widely applied in simulating complex physical systems. It attempts to approximate the solution to some equation by piecewise linear functions, where the pieces are chosen concerning a sufficiently fine grid, which in turn can be recast as a matrix equation.[169]
Probability theory and statistics
Two different Markov chains. The chart depicts the number of particles (of a total of 1000) in state "2". Both limiting values can be determined from the transition matrices, which are given by (red) and (black).
Stochastic matrices are square matrices whose rows are probability vectors, that is, whose entries are non-negative and sum up to one. Stochastic matrices are used to define Markov chains with finitely many states.[170] A row of the stochastic matrix gives the probability distribution for the next position of some particle currently in the state that corresponds to the row. Properties of the Markov chain—like absorbing states, that is, states that any particle attains eventually—can be read off the eigenvectors of the transition matrices.[171]
The first model of quantum mechanics (Heisenberg, 1925) used infinite-dimensional matrices to define the operators that took over the role of variables like position, momentum and energy from classical physics.[177] (This is sometimes referred to as matrix mechanics.[178]) Matrices, both finite and infinite-dimensional, have since been employed for many purposes in quantum mechanics. One particular example is the density matrix, a tool used in calculating the probabilities of the outcomes of measurements performed on physical systems.[179][180]
Another matrix serves as a key tool for describing the scattering experiments that form the cornerstone of experimental particle physics: Collision reactions such as occur in particle accelerators, where non-interacting particles head towards each other and collide in a small interaction zone, with a new set of non-interacting particles as the result, can be described as the scalar product of outgoing particle states and a linear combination of ingoing particle states. The linear combination is given by a matrix known as the S-matrix, which encodes all information about the possible interactions between particles.[183]
Normal modes
A general application of matrices in physics is the description of linearly coupled harmonic systems. The equations of motion of such systems can be described in matrix form, with a mass matrix multiplying a generalized velocity to give the kinetic term, and a force matrix multiplying a displacement vector to characterize the interactions. The best way to obtain solutions is to determine the system's eigenvectors, its normal modes, by diagonalizing the matrix equation. Techniques like this are crucial when it comes to the internal dynamics of molecules: the internal vibrations of systems consisting of mutually bound component atoms.[184] They are also needed for describing mechanical vibrations, and oscillations in electrical circuits.[185]
Geometrical optics
Geometrical optics provides further matrix applications. In this approximative theory, the wave nature of light is neglected. The result is a model in which light rays are indeed geometrical rays. If the deflection of light rays by optical elements is small, the action of a lens or reflective element on a given light ray can be expressed as multiplication of a two-component vector with a two-by-two matrix called ray transfer matrix analysis: the vector's components are the light ray's slope and its distance from the optical axis, while the matrix encodes the properties of the optical element. There are two kinds of matrices, viz. a refraction matrix describing the refraction at a lens surface, and a translation matrix, describing the translation of the plane of reference to the next refracting surface, where another refraction matrix applies. The optical system, consisting of a combination of lenses and reflective elements, is simply described by the matrix resulting from the product of the components' matrices.[186]
Electronic circuits that are composed of linear components (such as resistors, inductors and capacitors) obey Kirchhoff's circuit laws, which leads to a system of linear equations, which can be described with a matrix equation that relates the source currents and voltages to the resultant currents and voltages at each point in the circuit, and where the matrix entries are determined by the circuit.[187]
This use of the term matrix in mathematics (an English word for "womb" in the 19th century, from Latin, as well as a jargon word in printing, in biology and in geology[194]) was coined by James Joseph Sylvester in 1850,[195] who understood a matrix as an object giving rise to several determinants today called minors, that is to say, determinants of smaller matrices that derive from the original one by removing columns and rows. In an 1851 paper, Sylvester explains:[196]
I have in previous papers defined a "Matrix" as a rectangular array of terms, out of which different systems of determinants may be engendered from the womb of a common parent.
Arthur Cayley published a treatise on geometric transformations using matrices that were not rotated versions of the coefficients being investigated as had previously been done. Instead, he defined operations such as addition, subtraction, multiplication, and division as transformations of those matrices and showed the associative and distributive properties held. Cayley investigated and demonstrated the non-commutative property of matrix multiplication as well as the commutative property of matrix addition.[189] Early matrix theory had limited the use of arrays almost exclusively to determinants and Cayley's abstract matrix operations were revolutionary. He was instrumental in proposing a matrix concept independent of equation systems. In 1858, Cayley published his A memoir on the theory of matrices[197][198] in which he proposed and demonstrated the Cayley–Hamilton theorem.[189]
The English mathematician Cuthbert Edmund Cullis was the first to use modern bracket notation for matrices in 1913 and he simultaneously demonstrated the first significant use of the notation A = [ai,j] to represent a matrix where ai,j refers to the ith row and the jth column.[189]
The modern study of determinants sprang from several sources.[199]Number-theoretical problems led Gauss to relate coefficients of quadratic forms, that is, expressions such as x2 + xy − 2y2, and linear maps in three dimensions to matrices. Eisenstein further developed these notions, including the remark that, in modern parlance, matrix products are non-commutative. Cauchy was the first to prove general statements about determinants, using as the definition of the determinant of a matrix A = [ai,j] the following: replace the powers ajk by aj,k in the polynomial where denotes the product of the indicated terms. He also showed, in 1829, that the eigenvalues of symmetric matrices are real.[200]Jacobi studied "functional determinants"—later called Jacobi determinants by Sylvester—which can be used to describe geometric transformations at a local (or infinitesimal) level, see above. Kronecker's Vorlesungen über die Theorie der Determinanten[201] and Weierstrass's Zur Determinantentheorie,[202] both published in 1903, first treated determinants axiomatically, as opposed to previous more concrete approaches such as the mentioned formula of Cauchy. At that point, determinants were firmly established.[203][199]
Many theorems were first established for small matrices only, for example, the Cayley–Hamilton theorem was proved for 2 × 2 matrices by Cayley in the aforementioned memoir, and by Hamilton for 4 × 4 matrices. Frobenius, working on bilinear forms, generalized the theorem to all dimensions (1898). Also at the end of the 19th century, the Gauss–Jordan elimination (generalizing a special case now known as Gauss elimination) was established by Wilhelm Jordan. In the early 20th century, matrices attained a central role in linear algebra,[204] partially due to their use in the classification of the hypercomplex number systems of the previous century.[205]
Let us give the name of matrix to any function, of however many variables, that does not involve any apparent variables. Then, any possible function other than a matrix derives from a matrix using generalization, that is, by considering the proposition that the function in question is true with all possible values or with some value of one of the arguments, the other argument or arguments remaining undetermined.
For example, a function Φ(x, y) of two variables x and y can be reduced to a collection of functions of a single variable, such as y, by "considering" the function for all possible values of "individuals" ai substituted in place of a variable x. And then the resulting collection of functions of the single variable y, that is, ∀ai: Φ(ai, y), can be reduced to a "matrix" of values by "considering" the function for all possible values of "individuals" bi substituted in place of variable y:
Alfred Tarski in his 1941 Introduction to Logic used the word "matrix" synonymously with the notion of truth table as used in mathematical logic.[209]
↑Greub (1975, p.90). Note however that Greub follows a transposed convention of representing a transformation by multiplying a row vector by a matrix, rather than multiplying a matrix by a column vector, leading to the reversed order for the two matrices in the product that represents a composition.
↑ "Not much of matrix theory carries over to infinite-dimensional spaces, and what does is not so useful, but it sometimes helps." Halmos1982,p. 23, Chapter 5.
↑"Empty Matrix: A matrix is empty if either its row or column dimension is zero", GlossaryArchived 2009-04-29 at the Wayback Machine , O-Matrix v6 User Guide
↑The earliest published example is J. J. Sylvester (1850) "Additions to the articles in the September number of this journal, 'On a new class of theorems,' and on Pascal's theorem," The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science, 37: 363-370. From page 369: "For this purpose, we must commence, not with a square, but with an oblong arrangement of terms consisting, suppose, of m lines and n columns. This does not in itself represent a determinant, but is, as it were, a Matrix out of which we may form various systems of determinants ... "
↑Whitehead, Alfred North; and Russell, Bertrand (1913) Principia Mathematica to *56, Cambridge at the University Press, Cambridge UK (republished 1962) cf page 162ff.
Bernstein, Dennis S. (2009), Matrix mathematics: theory, facts, and formulas (2nded.), Princeton, N.J: Princeton University Press, ISBN978-1-4008-3334-4
Bhaya, Amit; Kaszkurewicz, Eugenius (2006), Control Perspectives on Numerical Algorithms and Matrix Problems, Advances in Design and Control, vol.10, SIAM, ISBN9780898716023
Bierens, Herman J. (2004), Introduction to the Mathematical and Statistical Foundations of Econometrics, Cambridge University Press, ISBN9780521542241
Boos, Johann (2000), Classical and Modern Methods in Summability, Oxford mathematical monographs, Oxford University Press, ISBN9780198501657
Bretscher, Otto (2005), Linear Algebra with Applications (3rded.), Prentice Hall
Cameron, Peter J. (2014), "Matrix groups"(PDF), in Hogben, Leslie (ed.), Handbook of Linear Algebra, Discrete Mathematics and its Applications (Boca Raton) (2nded.), CRC Press, Boca Raton, FL, ISBN978-1-4665-0728-9, MR3013937
Carboni, Aurelio; Kasangian, Stefano; Walters, Robert (1987), "An axiomatics for bicategories of modules", Journal of Pure and Applied Algebra, 45 (2): 127–141, doi:10.1016/0022-4049(87)90065-X, MR0889588, Zbl0615.18006
Chahal, J. S. (2018), Fundamentals of Linear Algebra, CRC Press, ISBN9780429758119
Coburn, Nathaniel (1955), Vector and tensor analysis, New York, NY: Macmillan, OCLC1029828
Coleman, Thomas F.; Van Loan, Charles (1988), Handbook for Matrix Computations, Frontiers in Applied Mathematics, vol.4, SIAM, ISBN9780898712278
Farid, F. O.; Khan, Israr Ali; Wang, Qing-Wen (2013), "On matrices over an arbitrary semiring and their generalized inverses", Linear Algebra and its Applications, 439 (7): 2085–2105, doi:10.1016/j.laa.2013.06.002, MR3090456, Zbl1283.15016
Gilbarg, David; Trudinger, Neil S. (2001), Elliptic partial differential equations of second order (2nded.), Berlin, DE; New York, NY: Springer-Verlag, ISBN978-3-540-41160-4
Latouche, Guy; Ramaswami, Vaidyanathan (1999), Introduction to matrix analytic methods in stochastic modeling (1sted.), Philadelphia, PA: Society for Industrial and Applied Mathematics, ISBN978-0-89871-425-8
Manning, Christopher D.; Schütze, Hinrich (1999), Foundations of statistical natural language processing, MIT Press, ISBN978-0-262-13360-9
Margalit, Dan; Rabinoff, Joseph (2019), "Determinants and Volumes", Interactive Linear Algebra, Georgia Institute of Technology, retrieved 2025-05-10
Matoušek, Jiří; Gärtner, Bernd (2007), Understanding and Using Linear Programming, Springer Science & Business Media, ISBN9783540307174
Maxwell, E. A. (1969), Algebraic Structure and Matrices, Being Part II of Advanced Algebra, Cambridge University Press
McHugh, Andrew (2025), Finite Mathematics: An Introduction with Applications in Business, Social Sciences, and Music, Academic Press, ISBN9780443290954
Misra, Chandan; Bhattacharya, Sourangshu; Ghosh, Soumya K. (June 2022), "Stark: Fast and scalable Strassen's matrix multiplication using Apache Spark", IEEE Transactions on Big Data, 8 (3): 699–710, arXiv:1811.07325, doi:10.1109/tbdata.2020.2977326
Nering, Evar D. (1970), Linear Algebra and Matrix Theory (2nded.), New York: Wiley, LCCN76-91646
Nocedal, Jorge; Wright, Stephen J. (2006), Numerical Optimization (2nded.), Berlin, DE; New York, NY: Springer-Verlag, p.449, ISBN978-0-387-30303-1
Pop; Furdui (2017), Square Matrices of Order 2, Springer International Publishing, ISBN978-3-319-54938-5
Press, William H.; Flannery, Brian P.; Teukolsky, Saul A.; Vetterling, William T. (1992), "LU Decomposition and Its Applications"(PDF), Numerical Recipes in FORTRAN: The Art of Scientific Computing (2nded.), Cambridge University Press, pp.34–42, archived from the original on 2009-09-06
Protter, Murray H.; Morrey, Charles B. Jr. (1970), College Calculus with Analytic Geometry (2nded.), Reading: Addison-Wesley, LCCN76087042
Punnen, Abraham P.; Gutin, Gregory (2002), The traveling salesman problem and its variations, Boston, MA: Kluwer Academic Publishers, ISBN978-1-4020-0664-7
Ramachandra Rao, A.; Bhimasankaram, P. (2000), Linear Algebra, Texts and Readings in Mathematics, vol.19 (2nded.), Springer, ISBN9789386279019
Reyes, Manuel (2025), "A tour of noncommutative spectral theories", Notices of the American Mathematical Society, 72 (2): 145–153, arXiv:2409.08421, doi:10.1090/noti3100, MR4854325
Scott, J.; Tůma, M. (2023), "Sparse Matrices and Their Graphs", Algorithms for Sparse Linear Systems, Nečas Center Series, Cham: Birkhäuser, pp.19–30, doi:10.1007/978-3-031-25820-6_2, ISBN978-3-031-25819-0
Vassilevska Williams, Virginia; Xu, Yinzhan; Xu, Zixuan; Zhou, Renfei (2024), "New bounds for matrix multiplication: from alpha to omega", Proceedings of the 2024 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pp.3792–3835, arXiv:2307.07970, doi:10.1137/1.9781611977912.134, ISBN978-1-61197-791-2
Zhang, Yanchun; Yu, Jeffrey Xu; Hou, Jingyu (2006), Web Communities: Analysis and Construction, Springer, ISBN978-3-540-27737-8
Physics references
Abłamowicz, Rafał (2000), Clifford Algebras and their Applications in Mathematical Physics, Volume 1: Algebra and Physics, Progress in Mathematical Physics, vol.18, Birkhäuser / Springer, ISBN9780817641825
Bauchau, O. A.; Craig, J. I. (2009), Structural Analysis: With Applications to Aerospace Structures, Solid Mechanics and Its Applications, vol.163, Springer, ISBN9789048125166
Reichl, Linda E. (2004), The transition to chaos: conservative classical systems and quantum manifestations, Berlin, DE; New York, NY: Springer-Verlag, ISBN978-0-387-98788-0
Riley, Kenneth F.; Hobson, Michael P.; Bence, Stephen J. (1997), Mathematical methods for physics and engineering, Cambridge University Press, ISBN0-521-55506-X
Wherrett, Brian S. (1987), Group Theory for Atoms, Molecules and Solids, Prentice–Hall International, ISBN0-13-365461-3
Ydri, Badis (2016), Lectures on Matrix Field Theory, Lecture Notes in Physics, vol.929, Springer, ISBN9783319460031
Zabrodin, Anton; Brézin, Édouard; Kazakov, Vladimir; Serban, Didina; Wiegmann, Paul (2006), Applications of Random Matrices in Physics (NATO Science Series II: Mathematics, Physics and Chemistry), Berlin, DE; New York, NY: Springer-Verlag, ISBN978-1-4020-4530-1
Knobloch, Eberhard (1994), "From Gauß to Weierstraß: determinant theory and its historical evaluations", in Sasaki, Chikara; Sugiura, Mitsuo; Dauben, Joseph W. (eds.), The Intersection of History and Mathematics, Science Networks: Historical Studies, vol.15, Birkhäuser, pp.51–66, doi:10.1007/978-3-0348-7521-9_5, ISBN3-7643-5029-6, MR1308079
Tarski, Alfred (1941), Introduction to Logic and the Methodology of Deductive Sciences, Oxford University Press, MR0003375 ; reprint of 1946 corrected printing, Dover Publications, 1995, ISBN0-486-28462-X
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.




























































































































































![An undirected graph with adjacency matrix:
[
1
1
0
1
0
1
0
1
0
]
.
{\displaystyle {\begin{bmatrix}1&1&0\\1&0&1\\0&1&0\end{bmatrix}}.} Labelled undirected graph.svg](http://upload.wikimedia.org/wikipedia/commons/thumb/a/a5/Labelled_undirected_graph.svg/250px-Labelled_undirected_graph.svg.png)



![At the saddle point (x = 0, y = 0) (red) of the function f (x,-y) = x - y, the Hessian matrix
[
2
0
0
-
2
]
{\displaystyle {\begin{bmatrix}2&0\\0&-2\end{bmatrix}}}
is indefinite. Saddle Point SVG.svg](http://upload.wikimedia.org/wikipedia/commons/thumb/0/0d/Saddle_Point_SVG.svg/250px-Saddle_Point_SVG.svg.png)



![Two different Markov chains. The chart depicts the number of particles (of a total of 1000) in state "2". Both limiting values can be determined from the transition matrices, which are given by
[
0.7
0
0.3
1
]
{\displaystyle \left[{\begin{smallmatrix}0.7&0\\0.3&1\end{smallmatrix}}\right]}
(red) and
[
0.7
0.2
0.3
0.8
]
{\displaystyle \left[{\begin{smallmatrix}0.7&0.2\\0.3&0.8\end{smallmatrix}}\right]}
(black). Markov chain SVG.svg](http://upload.wikimedia.org/wikipedia/commons/thumb/2/29/Markov_chain_SVG.svg/330px-Markov_chain_SVG.svg.png)









