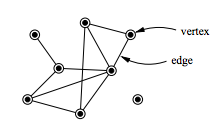
The analysis of electric power systems could be conducted using network theory from two main points of view:
An abstract perspective (i.e., as a graph consists from nodes and edges), regardless of the electric power aspects (e.g., transmission line impedances). Most of these studies focus only on the abstract structure of the power grid using node degree distribution and betweenness distribution, which introduces substantial insight regarding the vulnerability assessment of the grid. Through these types of studies, the category of the grid structure could be identified from the complex network perspective (e.g., single-scale, scale-free). This classification might help the electric power system engineers in the planning stage or while upgrading the infrastructure (e.g., add a new transmission line) to maintain a proper redundancy level in the transmission system.[1]
Weighted graphs that blend an abstract understanding of complex network theories and electric power systems properties.[2]
Since the 1970s, the empirical study of networks has played a central role in social science, and many of the mathematical and statistical tools used for studying networks have been first developed in sociology.[19] Amongst many other applications, social network analysis has been used to understand the diffusion of innovations, news and rumors.[20] Similarly, it has been used to examine the spread of both diseases and health-related behaviors.[21] It has also been applied to the study of markets, where it has been used to examine the role of trust in exchange relationships and of social mechanisms in setting prices.[22] It has been used to study recruitment into political movements, armed groups, and other social organizations.[23] It has also been used to conceptualize scientific disagreements[24] as well as academic prestige.[25] More recently, network analysis (and its close cousin traffic analysis) has gained a significant use in military intelligence.[26]
With the recent explosion of publicly available high throughput biological data, the analysis of molecular networks has gained significant interest.[27] The type of analysis in this context is closely related to social network analysis, but often focusing on local patterns in the network. For example, network motifs are small subgraphs that are over-represented in the network. Similarly, activity motifs are patterns in the attributes of nodes and edges in the network that are over-represented given the network structure. Using networks to analyze patterns in biological systems, such as food-webs, allows us to visualize the nature and strength of interactions between species. The analysis of biological networks with respect to diseases has led to the development of the field of network medicine.[28] Recent examples of application of network theory in biology include applications to understanding the cell cycle[29] as well as a quantitative framework for developmental processes.[30]
Narrative network analysis
Narrative network of US Elections 2012
The automatic parsing of textual corpora has enabled the extraction of actors and their relational networks on a vast scale. The resulting narrative networks, which can contain thousands of nodes, are then analyzed by using tools from Network theory to identify the key actors, the key communities or parties, and general properties such as robustness or structural stability of the overall network, or centrality of certain nodes.[32] This automates the approach introduced by Quantitative Narrative Analysis,[33] whereby subject-verb-object triplets are identified with pairs of actors linked by an action, or pairs formed by actor-object.[31]
Link analysis
Link analysis is a subset of network analysis, exploring associations between objects. An example may be examining the addresses of suspects and victims, the telephone numbers they have dialed, and financial transactions that they have partaken in during a given timeframe, and the familial relationships between these subjects as a part of police investigation. Link analysis here provides the crucial relationships and associations between very many objects of different types that are not apparent from isolated pieces of information. Computer-assisted or fully automatic computer-based link analysis is increasingly employed by banks and insurance agencies in fraud detection, by telecommunication operators in telecommunication network analysis, by medical sector in epidemiology and pharmacology, in law enforcement investigations, by search engines for relevance rating (and conversely by the spammers for spamdexing and by business owners for search engine optimization), and everywhere else where relationships between many objects have to be analyzed. Links are also derived from similarity of time behavior in both nodes. Examples include climate networks where the links between two locations (nodes) are determined, for example, by the similarity of the rainfall or temperature fluctuations in both sites.[34][35]
Web link analysis
Several Web searchranking algorithms use link-based centrality metrics, including Google's PageRank, Kleinberg's HITS algorithm, the CheiRank and TrustRank algorithms. Link analysis is also conducted in information science and communication science in order to understand and extract information from the structure of collections of web pages. For example, the analysis might be of the interlinking between politicians' websites or blogs. Another use is for classifying pages according to their mention in other pages.[36]
These concepts are used to characterize the linking preferences of hubs in a network. Hubs are nodes which have a large number of links. Some hubs tend to link to other hubs while others avoid connecting to hubs and prefer to connect to nodes with low connectivity. We say a hub is assortative when it tends to connect to other hubs. A disassortative hub avoids connecting to other hubs. If hubs have connections with the expected random probabilities, they are said to be neutral. There are three methods to quantify degree correlations.[38]
Recurrence networks
The recurrence matrix of a recurrence plot can be considered as the adjacency matrix of an undirected and unweighted network. This allows for the analysis of time series by network measures. Applications range from detection of regime changes over characterizing dynamics to synchronization analysis.[39][40][41]
Spatial networks
Many real networks are embedded in space. Examples include, transportation and other infrastructure networks, brain neural networks. Several models for spatial networks have been developed.[42]
Temporal networks
Other networks emphasise the evolution over time of systems of nodes and their interconnections. Temporal networks are used for example to study how financial risk has spread across countries.[43] In this study, temporal networks are used to also visually trace the intricate dynamics of financial contagion during crises. Unlike traditional network approaches that aggregate or analyze static snapshots, the study uses a time-respecting path methodology to preserve the sequence and timing of financial crises contagion events. This enables the identification of nodes as sources, transmitters, or receivers of financial stress, avoiding mischaracterizations inherent in static or aggregated methods. Following this approach, banks are found to serve as key intermediaries in contagion paths, and temporal analysis pinpoints smaller countries like Greece and Italy as significant origins of shocks during crises—insights obscured by static approaches that overemphasize large economies like the US or Japan.
Temporal networks can also be used to explore how cooperation evolves in dynamic, real-world population structures where interactions are time-dependent.[44] Here the authors find that network temporality enhances cooperation compared to static networks, even though "bursty" interaction patterns typically hinder it. This finding also shows how cooperation and other emergent behaviours can thrive in realistic, time-varying population structures, challenging conventional assumptions rooted in static models.
In psychology, temporal networks enable the understanding of psychological disorders by framing them as dynamic systems of interconnected symptoms rather than outcomes of a single underlying cause. Using "nodes" to represent symptoms and "edges" to signify their direct interactions, symptoms like insomnia and fatigue are shown how they influence each other over time; also, disorders such as depression are shown not to be fixed entities but evolving networks, where identifying "bridge symptoms" like concentration difficulties can explain comorbidity between conditions such as depression and anxiety.[45]
Lastly, temporal networks enable a better understanding and controlling of the spread of infectious diseases.[46] Unlike traditional static networks, which assume continuous, unchanging connections, temporal networks account for the precise timing and duration of interactions between individuals. This dynamic approach reveals critical nuances, such as how diseases can spread via time-sensitive pathways that static models miss. Temporal data, such as interactions captured through Bluetooth sensors or in hospital wards, can improve predictions of outbreak speed and extent. Overlooking temporal correlations can lead to significant errors in estimating epidemic dynamics, emphasizing the need for a temporal framework to develop more accurate strategies for disease control.
Spread
Content in a complex network can spread via two major methods: conserved spread and non-conserved spread.[47] In conserved spread, the total amount of content that enters a complex network remains constant as it passes through. The model of conserved spread can best be represented by a pitcher containing a fixed amount of water being poured into a series of funnels connected by tubes. Here, the pitcher represents the original source and the water is the content being spread. The funnels and connecting tubing represent the nodes and the connections between nodes, respectively. As the water passes from one funnel into another, the water disappears instantly from the funnel that was previously exposed to the water. In non-conserved spread, the amount of content changes as it enters and passes through a complex network. The model of non-conserved spread can best be represented by a continuously running faucet running through a series of funnels connected by tubes. Here, the amount of water from the original source is infinite. Also, any funnels that have been exposed to the water continue to experience the water even as it passes into successive funnels. The non-conserved model is the most suitable for explaining the transmission of most infectious diseases, neural excitation, information and rumors, etc.
Network immunization
The question of how to immunize efficiently scale free networks which represent realistic networks such as the Internet and social networks has been studied extensively. One such strategy is to immunize the largest degree nodes, i.e., targeted (intentional) attacks[48] since for this case is relatively high and fewer nodes are needed to be immunized. However, in most realistic networks the global structure is not available and the largest degree nodes are unknown.
↑Sindbæk S (2007). Networks and nodal points: the emergence of towns in early Viking Age Scandinavia - Antiquity 81(311). Cambridge University Press. pp.119–132.
↑Harris JK, Luke DA, Zuckerman RB, Shelton SC (June 2009). "Forty years of secondhand smoke research: the gap between discovery and delivery". American Journal of Preventive Medicine. 36 (6): 538–548. doi:10.1016/j.amepre.2009.01.039. OCLC5899755895. PMID19372026.
↑Varda DM, Forgette R, Banks D, Contractor N (2009). "Social Network Methodology in the Study of Disasters: Issues and Insights Prompted by Post-Katrina Research". Population Research and Policy Review. 28 (1): 11–29. doi:10.1007/s11113-008-9110-9. ISSN0167-5923. OCLC5659930640. S2CID144130904.
↑Wasserman, Stanley and Katherine Faust. 1994. Social Network Analysis: Methods and Applications. Cambridge: Cambridge University Press. Rainie, Lee and Barry Wellman, Networked: The New Social Operating System. Cambridge, MA: MIT Press, 2012.
↑Newman, M.E.J. Networks: An Introduction. Oxford University Press. 2010
↑Odabaş M, Holt TJ, Breiger RL (October 2017). "Markets as Governance Environments for Organizations at the Edge of Illegality: Insights From Social Network Analysis". American Behavioral Scientist. 61 (11): 1267–1288. doi:10.1177/0002764217734266. hdl:10150/631238. S2CID158776581.
↑Jordan, D.G.; Winer, E.S.; Salem, T. (2020). "The current status of temporal network analysis for clinical science: Considerations as the paradigm shifts?". J Clin Psychol. 76 (9): 1591–1612. doi:10.1002/jclp.22957. PMID32386334.
Dorogovtsev SN, Mendes JR (2003). Evolution of Networks: from biological networks to the Internet and WWW. Oxford University Press. ISBN978-0-19-851590-6.
Caldarelli G (2007). Scale-Free Networks. Oxford University Press. ISBN978-0-19-921151-7.
Barrat A, Barthelemy M, Vespignani A (2008). Dynamical Processes on Complex Networks. Cambridge University Press. ISBN978-0-521-87950-7.
Estrada E (2011). The Structure of Complex Networks: Theory and Applications. Oxford University Press. ISBN978-0-199-59175-6.
Soramaki K, Cook S (2016). Network Theory and Financial Risk. Risk Books. ISBN978-1-78272-219-9.
Latora V, Nicosia V, Russo G (2017). Complex Networks: Principles, Methods and Applications. Cambridge University Press. ISBN978-1-107-10318-4.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.