The dependency network approach provides a system level analysis of the activity and topology of directed networks. The approach extracts causal topological relations between the network's nodes (when the network structure is analyzed), and provides an important step towards inference of causal activity relations between the network nodes (when analyzing the network activity). This methodology has originally been introduced for the study of financial data,[1][2] it has been extended and applied to other systems, such as the immune system,[3]semantic networks,[4] and functional brain networks.[5][6][7]
In the case of network activity, the analysis is based on partial correlations.[8][9][10][11][12] In simple words, the partial (or residual) correlation is a measure of the effect (or contribution) of a given node, say j, on the correlations between another pair of nodes, say i and k. Using this concept, the dependency of one node on another node is calculated for the entire network. This results in a directed weighted adjacency matrix of a fully connected network. Once the adjacency matrix has been constructed, different algorithms can be used to construct the network, such as a threshold network, Minimal Spanning Tree (MST), Planar Maximally Filtered Graph (PMFG), and others.
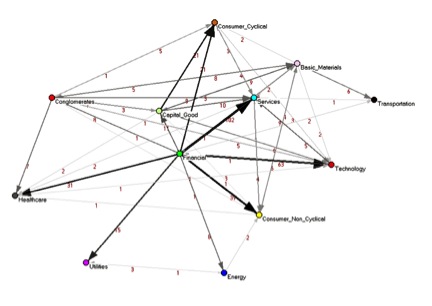
Dependency network of financial data, for 300 of the S&P500 stocks, traded between 2001–2003. Stocks are grouped by economic sectors, and the arrow points in the direction of influence. The hub of the network, the most influencing sector, is the Financial sector. Reproduction from Kenett et al., PLoS ONE 5(12), e15032 (2010)
Importance
The partial correlation based dependency network is a class of correlation network, capable of uncovering hidden relationships between its nodes.
This original methodology was first presented at the end of 2010, published in PLoS ONE.[1] The authors quantitatively uncovered hidden information about the underlying structure of the U.S. stock market, information that was not present in the standard correlation networks. One of the main results of this work is that for the investigated time period (2001–2003), the structure of the network was dominated by companies belonging to the financial sector, which are the hubs in the dependency network. Thus, they were able for the first time to quantitatively show the dependency relationships between the different economic sectors. Following this work, the dependency network methodology has been applied to the study of the immune system,[3]semantic networks,[4] and functional brain networks.[5][6][7]
Dependency Network of specific antibodies activity, measured for a group of mothers. Panel (a) presents the dependency network, and panel (b) the standard correlation network. Reproduction from Madi et al., Chaos 21, 016109 (2011)Example of Dependency Network of associations, constructed from a full semantic network. Reproduction from Kenett et al., PLoS ONE 6(8): e23912 (2011)
Overview
To be more specific, the partial correlation of the pair (i, k) given j, is the correlation between them after proper subtraction of the correlations between i and j and between k and j. Defined this way, the difference between the correlations and the partial correlations provides a measure of the influence of node j on the correlation. Therefore, we define the influence of node j on node i, or the dependency of node i on node j−D(i,j), to be the sum of the influence of node j on the correlations of node i with all other nodes.
In the case of network topology, the analysis is based on the effect of node deletion on the shortest paths between the network nodes. More specifically, we define the influence of node j on each pair of nodes (i,k) to be the inverse of the topological distance between these nodes in the presence of j minus the inverse distance between them in the absence of node j. Then we define the influence of node j on node i, or the dependency of node i on node j−D(i,j), to be the sum of the influence of node j on the distances between node i with all other nodesk.
Where and are the activity of nodes i and j of subject n, μ stands for average, and sigma the STD of the dynamics profiles of nodes i and j. Note that the node-node correlations (or for simplicity the node correlations) for all pairs of nodes define a symmetric correlation matrix whose element is the correlation between nodes i and j.
Partial correlations
Next we use the resulting node correlations to compute the partial correlations. The first order partial correlation coefficient is a statistical measure indicating how a third variable affects the correlation between two other variables. The partial correlation between nodes i and k with respect to a third node is defined as:
where and are the node correlations defined above.
The correlation influence and correlation dependency
The relative effect of the correlations and of node j on the correlation C(i,k) is given by:
This avoids the trivial case were node j appears to strongly affect the correlation , mainly because and have small values. We note that this quantity can be viewed either as the correlation dependency of C(i,k) on node j (the term used here) or as the correlation influence of node j on the correlation C(i,k).
Node activity dependencies
Next, we define the total influence of node j on node i, or the dependency D(i,j) of node i on node j to be:
As defined,D(i,j) is a measure of the average influence of node j on the correlations C(i,k) over all nodes k not equal to j. The node activity dependencies define a dependency matrix D whose (i,j) element is the dependency of node i on node j. It is important to note that while the correlation matrix C is a symmetric matrix, the dependency matrix D is nonsymmetrical – since the influence of node j on node i is not equal to the influence of node i on node j. For this reason, some of the methods used in the analyses of the correlation matrix (e.g. the PCA) have to be replaced or are less efficient. Yet there are other methods, as the ones used here, that can properly account for the non-symmetric nature of the dependency matrix.
The structure dependency networks
The path influence and distance dependency: The relative effect of node j on the directed path – the shortest topological path with each segment corresponds to a distance 1, between nodes i and k is given:
where and are the shortest directed topological path from node i to node k in the presence and the absence of node j respectively.
Node structural dependencies
Next, we define the total influence of node j on node i, or the dependency D(i,j) of node i on node j to be:
As defined, D(i,j) is a measure of the average influence of node j on the directed paths from node i to all other nodes k. The node structural dependencies define a dependency matrix D whose (i,j) element is the dependency of node i on node j, or the influence of node j on node i. It is important to note that the dependency matrix D is nonsymmetrical – since the influence of node j on node i is not equal to the influence of node i on node j.
Visualization of the dependency network
The dependency matrix is the weighted adjacency matrix, representing the fully connected network. Different algorithms can be applied to filter the fully connected network to obtain the most meaningful information, such as using a threshold approach,[1] or different pruning algorithms. A widely used method to construct informative sub-graph of a complete network is the Minimum Spanning Tree (MST).[13][14][15][16][17] Another informative sub-graph, which retains more information (in comparison to the MST) is the Planar Maximally Filtered Graph (PMFG)[18] which is used here. Both methods are based on hierarchical clustering and the resulting sub-graphs include all the N nodes in the network whose edges represent the most relevant association correlations. The MST sub-graph contains edges with no loops while the PMFG sub-graph contains edges.
↑ Dror Y. Kenett, Yoash Shapira, Gitit Gur-Gershgoren, and Eshel Ben-Jacob (submitted), Index Cohesive Force analysis of the U.S. stock market, Proceedings of the 2011 International Conference on Econophysics, Kavala, Greece
1 2 Asaf Madi, Dror Y. Kenett, Sharron Bransburg-Zabary, Yifat Merbl, Francisco J. Quintana, Stefano Boccaletti, Alfred I. Tauber, Irun R. Cohen, and Eshel Ben-Jacob (2011), Analyses of antigen dependency networks unveil immune system reorganization between birth and adulthood, Chaos 21, 016109Archived 2012-03-30 at the Wayback Machine
↑ Kunihiro Baba, Ritel Shibata, Masaaki Sibuya (2004), Partial correlation and conditional correlation as measures of conditional independence, Aust New Zealand J Stat 46(4): 657–774
↑ Dror Y. Kenett, Matthias Raddant, Thomas Lux, and Eshel Ben-Jacob (submitted), Evolvement of uniformity and volatility in the stressed global market, PNAS
↑ Eran Stark, Rotem Drori and Moshe Abeles (2006), Partial Cross-Correlation Analysis Resolves Ambiguity in the Encoding of Multiple Movement Features, J Neurophysiol 95: 1966–1975
↑ Michele Tumminello, Claudia Coronnello, Fabrizio Lillo, Salvatore Miccichè and Rrosario N. Mantegna, Spanning trees and bootstrap reliability estimations in correlation based networks Archived 2021-10-27 at the Wayback Machine
↑ Douglas B. West, An Introduction to Graph Theory, edited by Prentice-Hall, Englewood Cliffs, NJ, 2001
↑ Michele Tumminello, Tomaso Aste, Tiziana Di Matteo and Rosario N. Mantegna, A tool for filtering information in complex systems, PNAS 102 (30), 10421–10426 (2005)
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.