"Linear space" redirects here. For a structure in incidence geometry, see Linear space (geometry).
Vector addition and scalar multiplication: a vector v (blue) is added to another vector w (red, upper illustration). Below, w is stretched by a factor of 2, yielding the sum v + 2w.
In mathematics and physics, a vector space (also called a linear space) is a set whose elements, often called vectors, can be added together and multiplied ("scaled") by numbers called scalars. The operations of vector addition and scalar multiplication must satisfy certain requirements, called vector axioms. Real vector spaces and complex vector spaces are kinds of vector spaces based on different kinds of scalars: real numbers and complex numbers. Scalars can also be, more generally, elements of any field.
Vector spaces are characterized by their dimension, which, roughly speaking, specifies the number of independent directions in the space. This means that for two vector spaces over a given field and with the same dimension, the properties that depend only on the vector-space structure are exactly the same (technically, the vector spaces are isomorphic). A vector space is finite-dimensional if its dimension is a natural number. Otherwise, it is infinite-dimensional, and its dimension is an infinite cardinal. Finite-dimensional vector spaces occur naturally in geometry and related areas. Infinite-dimensional vector spaces occur in many areas of mathematics. For example, polynomial rings are countably infinite-dimensional vector spaces, and many function spaces have the cardinality of the continuum as a dimension.
In this article, vectors are represented in boldface to distinguish them from scalars.[nb 1][1]
A vector space over a fieldF is a non-empty setV together with a binary operation and a binary function that satisfy the eight axioms listed below. In this context, the elements of V are commonly called vectors, and the elements ofF are called scalars.[2]
The binary operation, called vector addition or simply addition assigns to any two vectorsv and w in V a third vector in V which is commonly written as v + w, and called the sum of these two vectors.
The binary function, called scalar multiplication, assigns to any scalara in F and any vectorv in V another vector in V, which is denotedav.[nb 2]
To have a vector space, the eight following axioms must be satisfied for every u, v and w in V, and a and b in F.[3]
Distributivity of scalar multiplication with respect to vector addition
a(u + v) = au + av
Distributivity of scalar multiplication with respect to field addition
(a + b)v = av + bv
When the scalar field is the real numbers, the vector space is called a real vector space, and when the scalar field is the complex numbers, the vector space is called a complex vector space.[4] These two cases are the most common ones, but vector spaces with scalars in an arbitrary field F are also commonly considered. Such a vector space is called an F-vector space or a vector space over F.[5]
An equivalent definition of a vector space can be given, which is much more concise but less elementary: the first four axioms (related to vector addition) say that a vector space is an abelian group under addition, and the four remaining axioms (related to the scalar multiplication) say that this operation defines a ring homomorphism from the field F into the endomorphism ring of this group.[6] Specifically, the distributivity of scalar multiplication with respect to vector addition means that multiplication by a scalar a is an endomorphism of the group. The remaining three axiom establish that the function that maps a scalar a to the multiplication by a is a ring homomorphism from the field to the endomorphism ring of the group.
Subtraction of two vectors can be defined as
Direct consequences of the axioms include that, for every and one has
implies or
Even more concisely, a vector space is a module over a field.[7]
Bases, vector coordinates, and subspaces
A vector v in R (blue) expressed in terms of different bases: using the standard basis of R: v = xe1 + ye2 (black), and using a different, non-orthogonal basis: v = f1 + f2 (red).
Given a set G of elements of a F-vector space V, a linear combination of elements of G is an element of V of the form where and The scalars are called the coefficients of the linear combination.[8]
The elements of a subset G of a F-vector space V are said to be linearly independent if no element of G can be written as a linear combination of the other elements of G. Equivalently, they are linearly independent if two linear combinations of elements of G define the same element of V if and only if they have the same coefficients. Also equivalently, they are linearly independent if a linear combination results in the zero vector if and only if all its coefficients are zero.[9]
A linear subspace or vector subspaceW of a vector space V is a non-empty subset of V that is closed under vector addition and scalar multiplication; that is, the sum of two elements of W and the product of an element of W by a scalar belong to W.[10] This implies that every linear combination of elements of W belongs to W. A linear subspace is a vector space for the induced addition and scalar multiplication; this means that the closure property implies that the axioms of a vector space are satisfied.[11] The closure property also implies that every intersection of linear subspaces is a linear subspace.[11]
Given a subset G of a vector space V, the linear span or simply the span of G is the smallest linear subspace of V that contains G, in the sense that it is the intersection of all linear subspaces that contain G. The span of G is also the set of all linear combinations of elements of G. If W is the span of G, one says that Gspans or generatesW, and that G is a spanning set or a generating set of W.[12]
A subset of a vector space is a basis if its elements are linearly independent and span the vector space.[13] Every vector space has at least one basis, or many in general (see Basis (linear algebra) §Proof that every vector space has a basis).[14] Moreover, all bases of a vector space have the same cardinality, which is called the dimension of the vector space (see Dimension theorem for vector spaces).[15] This is a fundamental property of vector spaces, which is detailed in the remainder of the section.
Bases are a fundamental tool for the study of vector spaces, especially when the dimension is finite. In the infinite-dimensional case, the existence of infinite bases, often called Hamel bases, depends on the axiom of choice. It follows that, in general, no base can be explicitly described.[16] For example, the real numbers form an infinite-dimensional vector space over the rational numbers, for which no specific basis is known.
Consider a basis of a vector space V of dimension n over a field F. The definition of a basis implies that every may be written with in F, and that this decomposition is unique. The scalars are called the coordinates of v on the basis. They are also said to be the coefficients of the decomposition of v on the basis. One also says that the n-tuple of the coordinates is the coordinate vector of v on the basis, since the set of the n-tuples of elements of F is a vector space for componentwise addition and scalar multiplication, whose dimension is n.
The one-to-one correspondence between vectors and their coordinate vectors maps vector addition to vector addition and scalar multiplication to scalar multiplication. It is thus a vector space isomorphism, which allows translating reasonings and computations on vectors into reasonings and computations on their coordinates.[17]
In 1857, Cayley introduced the matrix notation which allows for harmonization and simplification of linear maps. Around the same time, Grassmann studied the barycentric calculus initiated by Möbius. He envisaged sets of abstract objects endowed with operations.[24] In his work, the concepts of linear independence and dimension, as well as scalar products are present. Grassmann's 1844 work exceeds the framework of vector spaces as well since his considering multiplication led him to what are today called algebras. Italian mathematician Peano was the first to give the modern definition of vector spaces and linear maps in 1888,[25] although he called them "linear systems".[26] Peano's axiomatization allowed for vector spaces with infinite dimension, but Peano did not develop that theory further. In 1897, Salvatore Pincherle adopted Peano's axioms and made initial inroads into the theory of infinite-dimensional vector spaces.[27]
Vector addition: the sum v + w (black) of the vectors v (blue) and w (red) is shown.
Scalar multiplication: the multiples −v and 2w are shown.
The first example of a vector space consists of arrows in a fixed plane, starting at one fixed point. This is used in physics to describe forces or velocities.[30] Given any two such arrows, v and w, the parallelogram spanned by these two arrows contains one diagonal arrow that starts at the origin, too. This new arrow is called the sum of the two arrows, and is denoted v + w. In the special case of two arrows on the same line, their sum is the arrow on this line whose length is the sum or the difference of the lengths, depending on whether the arrows have the same direction. Another operation that can be done with arrows is scaling: given any positive real numbera, the arrow that has the same direction as v, but is dilated or shrunk by multiplying its length by a, is called multiplication of v by a. It is denoted av. When a is negative, av is defined as the arrow pointing in the opposite direction instead.[31]
The following shows a few examples: if a = 2, the resulting vector aw has the same direction as w, but is stretched to the double length of w (the second image). Equivalently, 2w is the sum w + w. Moreover, (−1)v = −v has the opposite direction and the same length as v (blue vector pointing down in the second image).
Ordered pairs of numbers
A second key example of a vector space is provided by pairs of real numbers x and y. The order of the components x and y is significant, so such a pair is also called an ordered pair. Such a pair is written as (x, y). The sum of two such pairs and the multiplication of a pair with a number is defined as follows:[32]
The first example above reduces to this example if an arrow is represented by a pair of Cartesian coordinates of its endpoint.
Coordinate space
The simplest example of a vector space over a field F is the field F itself with its addition viewed as vector addition and its multiplication viewed as scalar multiplication. More generally, all n-tuples (sequences of length n) of elements ai of F form a vector space that is usually denoted Fn and called a coordinate space.[33] The case n = 1 is the above-mentioned simplest example, in which the field F is also regarded as a vector space over itself. The case F = R and n = 2 (so R2) reduces to the previous example.
Complex numbers and other field extensions
The set of complex numbersC, numbers that can be written in the form x + iy for real numbersx and y where i is the imaginary unit, form a vector space over the reals with the usual addition and multiplication: (x + iy) + (a + ib) = (x + a) + i(y + b) and c ⋅ (x + iy) = (c ⋅ x) + i(c ⋅ y) for real numbers x, y, a, b and c. The various axioms of a vector space follow from the fact that the same rules hold for complex number arithmetic. The example of complex numbers is essentially the same as (that is, it is isomorphic to) the vector space of ordered pairs of real numbers mentioned above: if we think of the complex number x + iy as representing the ordered pair (x, y) in the complex plane then we see that the rules for addition and scalar multiplication correspond exactly to those in the earlier example.
More generally, field extensions provide another class of examples of vector spaces, particularly in algebra and algebraic number theory: a field F containing a smaller field E is an E-vector space, by the given multiplication and addition operations of F.[34] For example, the complex numbers are a vector space over R, and the field extension is a vector space over Q.
Addition of functions: the sum of the sine and the exponential function is with .
Functions from any fixed set Ω to a field F also form vector spaces, by performing addition and scalar multiplication pointwise. That is, the sum of two functions f and g is the function given by and similarly for multiplication. Such function spaces occur in many geometric situations, when Ω is the real line or an interval, or other subsets of R. Many notions in topology and analysis, such as continuity, integrability or differentiability are well-behaved with respect to linearity: sums and scalar multiples of functions possessing such a property still have that property.[35] Therefore, the set of such functions are vector spaces, whose study belongs to functional analysis.
Systems of homogeneous linear equations are closely tied to vector spaces.[36] For example, the solutions of are given by triples with arbitrary and They form a vector space: sums and scalar multiples of such triples still satisfy the same ratios of the three variables; thus they are solutions, too. Matrices can be used to condense multiple linear equations as above into one vector equation, namely
where is the matrix containing the coefficients of the given equations, is the vector denotes the matrix product, and is the zero vector. In a similar vein, the solutions of homogeneous linear differential equations form vector spaces. For example,
The relation of two vector spaces can be expressed by linear map or linear transformation. They are functions that reflect the vector space structure, that is, they preserve sums and scalar multiplication: for all and in all in [37]
An isomorphism is a linear map f: V → W such that there exists an inverse mapg: W → V, which is a map such that the two possible compositionsf ∘ g: W → W and g ∘ f: V → V are identity maps. Equivalently, f is both one-to-one (injective) and onto (surjective).[38] If there exists an isomorphism between V and W, the two spaces are said to be isomorphic; they are then essentially identical as vector spaces, since all identities holding in V are, via f, transported to similar ones in W, and vice versa via g.
Describing an arrow vector v by its coordinates x and y yields an isomorphism of vector spaces.
For example, the arrows in the plane and the ordered pairs of numbers vector spaces in the introduction above (see §Examples) are isomorphic: a planar arrow v departing at the origin of some (fixed) coordinate system can be expressed as an ordered pair by considering the x- and y-component of the arrow, as shown in the image at the right. Conversely, given a pair (x, y), the arrow going by x to the right (or to the left, if x is negative), and y up (down, if y is negative) turns back the arrow v.[39]
Linear maps V → W between two vector spaces form a vector space HomF(V, W), also denoted L(V, W), or 𝓛(V, W).[40] The space of linear maps from V to F is called the dual vector space, denoted V∗.[41] Via the injective natural map V → V∗∗, any vector space can be embedded into its bidual; the map is an isomorphism if and only if the space is finite-dimensional.[42]
Once a basis of V is chosen, linear maps f: V → W are completely determined by specifying the images of the basis vectors, because any element of V is expressed uniquely as a linear combination of them.[43] If dim V = dim W, a 1-to-1 correspondence between fixed bases of V and W gives rise to a linear map that maps any basis element of V to the corresponding basis element of W. It is an isomorphism, by its very definition.[44] Therefore, two vector spaces over a given field are isomorphic if their dimensions agree and vice versa. Another way to express this is that any vector space over a given field is completely classified (up to isomorphism) by its dimension, a single number. In particular, any n-dimensional F-vector space V is isomorphic to Fn. However, there is no "canonical" or preferred isomorphism; an isomorphism φ: Fn → V is equivalent to the choice of a basis of V, by mapping the standard basis of Fn to V, via φ.
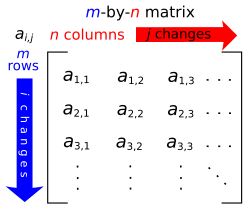
Matrices are a useful notion to encode linear maps.[45] They are written as a rectangular array of scalars as in the image at the right. Any m-by-n matrix gives rise to a linear map from Fn to Fm, by the following where denotes summation, or by using the matrix multiplication of the matrix with the coordinate vector :
Moreover, after choosing bases of V and W, any linear map f: V → W is uniquely represented by a matrix via this assignment.[46]
The volume of this parallelepiped is the absolute value of the determinant of the 3-by-3 matrix formed by the vectors r1, r2, and r3.
The determinantdet (A) of a square matrixA is a scalar that tells whether the associated map is an isomorphism or not: to be so it is sufficient and necessary that the determinant is nonzero.[47] The linear transformation of Rn corresponding to a real n-by-n matrix is orientation preserving if and only if its determinant is positive.
Endomorphisms, linear maps f: V → V, are particularly important since in this case vectors v can be compared with their image under f, f(v). Any nonzero vector v satisfying λv = f(v), where λ is a scalar, is called an eigenvector of f with eigenvalueλ.[48] Equivalently, v is an element of the kernel of the difference f − λ · Id (where Id is the identity mapV → V). If V is finite-dimensional, this can be rephrased using determinants: f having eigenvalue λ is equivalent to By spelling out the definition of the determinant, the expression on the left hand side can be seen to be a polynomial function in λ, called the characteristic polynomial of f.[49] If the field F is large enough to contain a zero of this polynomial (which automatically happens for Falgebraically closed, such as F = C) any linear map has at least one eigenvector. The vector space V may or may not possess an eigenbasis, a basis consisting of eigenvectors. This phenomenon is governed by the Jordan canonical form of the map.[50] The set of all eigenvectors corresponding to a particular eigenvalue of f forms a vector space known as the eigenspace corresponding to the eigenvalue (and f) in question.
Basic constructions
In addition to the above concrete examples, there are a number of standard linear algebraic constructions that yield vector spaces related to given ones.
A line passing through the origin (blue, thick) in R is a linear subspace. It is the intersection of two planes (green and yellow).
A nonempty subset of a vector space that is closed under addition and scalar multiplication (and therefore contains the -vector of ) is called a linear subspace of , or simply a subspace of , when the ambient space is unambiguously a vector space.[51][nb 4] Subspaces of are vector spaces (over the same field) in their own right. The intersection of all subspaces containing a given set of vectors is called its span, and it is the smallest subspace of containing the set . Expressed in terms of elements, the span is the subspace consisting of all the linear combinations of elements of .[52]
Linear subspace of dimension 1 and 2 are referred to as a line (also vector line), and a plane respectively. If W is an n-dimensional vector space, any subspace of dimension 1 less, i.e., of dimension is called a hyperplane.[53]
The counterpart to subspaces are quotient vector spaces.[54] Given any subspace , the quotient space ("modulo") is defined as follows: as a set, it consists of where is an arbitrary vector in . The sum of two such elements and is , and scalar multiplication is given by . The key point in this definition is that if and only if the difference of and lies in .[nb 5] This way, the quotient space "forgets" information that is contained in the subspace .
The kernel of a linear map consists of vectors that are mapped to in .[55] The kernel and the image are subspaces of and , respectively.[56]
An important example is the kernel of a linear map for some fixed matrix . The kernel of this map is the subspace of vectors such that , which is precisely the set of solutions to the system of homogeneous linear equations belonging to . This concept also extends to linear differential equations where the coefficients are functions in too. In the corresponding map the derivatives of the function appear linearly (as opposed to , for example). Since differentiation is a linear procedure (that is, and for a constant ) this assignment is linear, called a linear differential operator. In particular, the solutions to the differential equation form a vector space (over R or C).[57]
The existence of kernels and images is part of the statement that the category of vector spaces (over a fixed field ) is an abelian category, that is, a corpus of mathematical objects and structure-preserving maps between them (a category) that behaves much like the category of abelian groups.[58] Because of this, many statements such as the first isomorphism theorem (also called rank–nullity theorem in matrix-related terms) and the second and third isomorphism theorem can be formulated and proven in a way very similar to the corresponding statements for groups.
The direct product of vector spaces and the direct sum of vector spaces are two ways of combining an indexed family of vector spaces into a new vector space.
The direct product of a family of vector spaces consists of the set of all tuples , which specify for each index in some index set an element of .[59] Addition and scalar multiplication is performed componentwise. A variant of this construction is the direct sum (also called coproduct and denoted ), where only tuples with finitely many nonzero vectors are allowed. If the index set is finite, the two constructions agree, but in general they are different.
The tensor product or simply of two vector spaces and is one of the central notions of multilinear algebra, which deals with extending notions such as linear maps to several variables. A map from the Cartesian product is called bilinear if is linear in both variables and That is to say, for fixed the map is linear in the sense above and likewise for fixed
The tensor product is a particular vector space that is a universal recipient of bilinear maps as follows. It is defined as the vector space consisting of finite (formal) sums of symbols called tensors subject to the rules[60] These rules ensure that the map from the to that maps a tuple to is bilinear. The universality states that given any vector space and any bilinear map there exists a unique map shown in the diagram with a dotted arrow, whose composition with equals : [61] This is called the universal property of the tensor product, an instance of the method—much used in advanced abstract algebra—to indirectly define objects by specifying maps from or to this object.
Vector spaces with additional structure
From the point of view of linear algebra, vector spaces are completely understood insofar as any vector space over a given field is characterized, up to isomorphism, by its dimension. However, vector spaces per se do not offer a framework to deal with the question—crucial to analysis—whether a sequence of functions converges to another function. Likewise, linear algebra is not adapted to deal with infinite series, since the addition operation allows only finitely many terms to be added. Therefore, the needs of functional analysis require considering additional structures.[62]
A vector space may be given a partial order under which some vectors can be compared.[63] For example, -dimensional real space can be ordered by comparing its vectors componentwise. Ordered vector spaces, for example Riesz spaces, are fundamental to Lebesgue integration, which relies on the ability to express a function as a difference of two positive functions where denotes the positive part of and the negative part.[64]
"Measuring" vectors is done by specifying a norm, a datum which measures lengths of vectors, or by an inner product, which measures angles between vectors. Norms and inner products are denoted and respectively. The datum of an inner product entails that lengths of vectors can be defined too, by defining the associated norm Vector spaces endowed with such data are known as normed vector spaces and inner product spaces, respectively.[65]
Coordinate space can be equipped with the standard dot product: In this reflects the common notion of the angle between two vectors and by the law of cosines: Because of this, two vectors satisfying are called orthogonal. An important variant of the standard dot product is used in Minkowski space: endowed with the Lorentz product[66] In contrast to the standard dot product, it is not positive definite: also takes negative values, for example, for Singling out the fourth coordinate—corresponding to time, as opposed to three space-dimensions—makes it useful for the mathematical treatment of special relativity. Note that in other conventions time is often written as the first, or "zeroeth" component so that the Lorentz product is written
Convergence questions are treated by considering vector spaces carrying a compatible topology, a structure that allows one to talk about elements being close to each other.[67] Compatible here means that addition and scalar multiplication have to be continuous maps. Roughly, if and in , and in vary by a bounded amount, then so do and [nb 6] To make sense of specifying the amount a scalar changes, the field also has to carry a topology in this context; a common choice is the reals or the complex numbers.
In such topological vector spaces one can consider series of vectors. The infinite sum denotes the limit of the corresponding finite partial sums of the sequence of elements of For example, the could be (real or complex) functions belonging to some function space in which case the series is a function series. The mode of convergence of the series depends on the topology imposed on the function space. In such cases, pointwise convergence and uniform convergence are two prominent examples.[68]
Unit "spheres" in consist of plane vectors of norm 1. Depicted are the unit spheres in different -norms, for and The bigger diamond depicts points of 1-norm equal to 2.
A way to ensure the existence of limits of certain infinite series is to restrict attention to spaces where any Cauchy sequence has a limit; such a vector space is called complete. Roughly, a vector space is complete provided that it contains all necessary limits. For example, the vector space of polynomials on the unit interval equipped with the topology of uniform convergence is not complete because any continuous function on can be uniformly approximated by a sequence of polynomials, by the Weierstrass approximation theorem.[69] In contrast, the space of all continuous functions on with the same topology is complete.[70] A norm gives rise to a topology by defining that a sequence of vectors converges to if and only if Banach and Hilbert spaces are complete topological vector spaces whose topologies are given, respectively, by a norm and an inner product. Their study—a key piece of functional analysis—focuses on infinite-dimensional vector spaces, since all norms on finite-dimensional topological vector spaces give rise to the same notion of convergence.[71] The image at the right shows the equivalence of the -norm and -norm on as the unit "balls" enclose each other, a sequence converges to zero in one norm if and only if it so does in the other norm. In the infinite-dimensional case, however, there will generally be inequivalent topologies, which makes the study of topological vector spaces richer than that of vector spaces without additional data.
From a conceptual point of view, all notions related to topological vector spaces should match the topology. For example, instead of considering all linear maps (also called functionals) maps between topological vector spaces are required to be continuous.[72] In particular, the (topological) dual space consists of continuous functionals (or to ). The fundamental Hahn–Banach theorem is concerned with separating subspaces of appropriate topological vector spaces by continuous functionals.[73]
A first example is the vector space consisting of infinite vectors with real entries whose -norm given by
The topologies on the infinite-dimensional space are inequivalent for different For example, the sequence of vectors in which the first components are and the following ones are converges to the zero vector for but does not for but
More generally than sequences of real numbers, functions are endowed with a norm that replaces the above sum by the Lebesgue integral
These spaces are complete.[75] (If one uses the Riemann integral instead, the space is not complete, which may be seen as a justification for Lebesgue's integration theory.[nb 8]) Concretely this means that for any sequence of Lebesgue-integrable functions with satisfying the condition there exists a function belonging to the vector space such that
The succeeding snapshots show summation of 1 to 5 terms in approximating a periodic function (blue) by finite sum of sine functions (red).
Complete inner product spaces are known as Hilbert spaces, in honor of David Hilbert.[77] The Hilbert space with inner product given by where denotes the complex conjugate of [78][nb 9] is a key case.
By definition, in a Hilbert space, any Cauchy sequence converges to a limit. Conversely, finding a sequence of functions with desirable properties that approximate a given limit function is equally crucial. Early analysis, in the guise of the Taylor approximation, established an approximation of differentiable functions by polynomials.[79] By the Stone–Weierstrass theorem, every continuous function on can be approximated as closely as desired by a polynomial.[80] A similar approximation technique by trigonometric functions is commonly called Fourier expansion, and is much applied in engineering. More generally, and more conceptually, the theorem yields a simple description of what "basic functions", or, in abstract Hilbert spaces, what basic vectors suffice to generate a Hilbert space in the sense that the closure of their span (that is, finite linear combinations and limits of those) is the whole space. Such a set of functions is called a basis of its cardinality is known as the Hilbert space dimension.[nb 10] Not only does the theorem exhibit suitable basis functions as sufficient for approximation purposes, but also together with the Gram–Schmidt process, it enables one to construct a basis of orthogonal vectors.[81] Such orthogonal bases are the Hilbert space generalization of the coordinate axes in finite-dimensional Euclidean space.
The solutions to various differential equations can be interpreted in terms of Hilbert spaces. For example, a great many fields in physics and engineering lead to such equations, and frequently solutions with particular physical properties are used as basis functions, often orthogonal.[82] As an example from physics, the time-dependent Schrödinger equation in quantum mechanics describes the change of physical properties in time by means of a partial differential equation, whose solutions are called wavefunctions.[83] Definite values for physical properties such as energy, or momentum, correspond to eigenvalues of a certain (linear) differential operator and the associated wavefunctions are called eigenstates. The spectral theorem decomposes a linear compact operator acting on functions in terms of these eigenfunctions and their eigenvalues.[84]
A hyperbola, given by the equation The coordinate ring of functions on this hyperbola is given by an infinite-dimensional vector space over
General vector spaces do not possess a multiplication between vectors. A vector space equipped with an additional bilinear operator defining the multiplication of two vectors is an algebra over a field (or F-algebra if the field F is specified).[85]
Another crucial example are Lie algebras, which are neither commutative nor associative, but the failure to be so is limited by the constraints ( denotes the product of and ):
Examples include the vector space of -by- matrices, with the commutator of two matrices, and endowed with the cross product.
The tensor algebra is a formal way of adding products to any vector space to obtain an algebra.[88] As a vector space, it is spanned by symbols, called simple tensors where the degree varies. The multiplication is given by concatenating such symbols, imposing the distributive law under addition, and requiring that scalar multiplication commute with the tensor product ⊗, much the same way as with the tensor product of two vector spaces introduced in the above section on tensor products. In general, there are no relations between and Forcing two such elements to be equal leads to the symmetric algebra, whereas forcing yields the exterior algebra.[89]
A vector bundle is a family of vector spaces parametrized continuously by a topological spaceX.[90] More precisely, a vector bundle over X is a topological space E equipped with a continuous map such that for every x in X, the fiber π−1(x) is a vector space. The case dim V = 1 is called a line bundle. For any vector space V, the projection X × V → X makes the product X × V into a "trivial" vector bundle. Vector bundles over X are required to be locally a product of X and some (fixed) vector space V: for every x in X, there is a neighborhoodU of x such that the restriction of π to π−1(U) is isomorphic[nb 11] to the trivial bundle U × V → U. Despite their locally trivial character, vector bundles may (depending on the shape of the underlying space X) be "twisted" in the large (that is, the bundle need not be (globally isomorphic to) the trivial bundle X × V). For example, the Möbius strip can be seen as a line bundle over the circle S1 (by identifying open intervals with the real line). It is, however, different from the cylinderS1 × R, because the latter is orientable whereas the former is not.[91]
Properties of certain vector bundles provide information about the underlying topological space. For example, the tangent bundle consists of the collection of tangent spaces parametrized by the points of a differentiable manifold. The tangent bundle of the circle S1 is globally isomorphic to S1 × R, since there is a global nonzero vector field on S1.[nb 12] In contrast, by the hairy ball theorem, there is no (tangent) vector field on the 2-sphereS2 which is everywhere nonzero.[92]K-theory studies the isomorphism classes of all vector bundles over some topological space.[93] In addition to deepening topological and geometrical insight, it has purely algebraic consequences, such as the classification of finite-dimensional real division algebras: R, C, the quaternionsH and the octonionsO.
Modules are to rings what vector spaces are to fields: the same axioms, applied to a ring R instead of a field F, yield modules.[94] The theory of modules, compared to that of vector spaces, is complicated by the presence of ring elements that do not have multiplicative inverses. For example, modules need not have bases, as the Z-module (that is, abelian group) Z/2Z shows; those modules that do (including all vector spaces) are known as free modules. Nevertheless, a vector space can be compactly defined as a module over a ring which is a field, with the elements being called vectors. Some authors use the term vector space to mean modules over a division ring.[95] The algebro-geometric interpretation of commutative rings via their spectrum allows the development of concepts such as locally free modules, the algebraic counterpart to vector bundles.
An affine plane (light blue) in R . It is a two-dimensional subspace shifted by a vector x (red).
Roughly, affine spaces are vector spaces whose origins are not specified.[96] More precisely, an affine space is a set with a free transitive vector space action. In particular, a vector space is an affine space over itself, by the map If W is a vector space, then an affine subspace is a subset of W obtained by translating a linear subspace V by a fixed vector x ∈ W; this space is denoted by x + V (it is a coset of V in W) and consists of all vectors of the form x + v for v ∈ V. An important example is the space of solutions of a system of inhomogeneous linear equations generalizing the homogeneous case discussed in the above section on linear equations, which can be found by setting in this equation.[97] The space of solutions is the affine subspace x + V where x is a particular solution of the equation, and V is the space of solutions of the homogeneous equation (the nullspace of A).
The set of one-dimensional subspaces of a fixed finite-dimensional vector space V is known as projective space; it may be used to formalize the idea of parallel lines intersecting at infinity.[98]Grassmannians and flag manifolds generalize this by parametrizing linear subspaces of fixed dimension k and flags of subspaces, respectively.
Notes
↑It is also common, especially in physics, to denote vectors with an arrow on top: It is also common, especially in higher mathematics, to not use any typographical method for distinguishing vectors from other mathematical objects.
↑Scalar multiplication is not to be confused with the scalar product, which is an additional operation on some specific vector spaces, called inner product spaces. Scalar multiplication is the multiplication of a vector by a scalar that produces a vector, while the scalar product is a multiplication of two vectors that produces a scalar.
↑This axiom is not an associative property, since it refers to two different operations, scalar multiplication and field multiplication. So, it is independent from the associativity of field multiplication, which is assumed by field axioms.
↑This is typically the case when a vector space is also considered as an affine space. In this case, a linear subspace contains the zero vector, while an affine subspace does not necessarily contain it.
↑ "Many functions in of Lebesgue measure, being unbounded, cannot be integrated with the classical Riemann integral. So spaces of Riemann integrable functions would not be complete in the norm, and the orthogonal decomposition would not apply to them. This shows one of the advantages of Lebesgue integration.", Dudley (1989), §5.3, p. 125.
↑A basis of a Hilbert space is not the same thing as a basis of a linear algebra. For distinction, a linear algebra basis for a Hilbert space is called a Hamel basis.
↑That is, there is a homeomorphism from π−1(U) to V × U which restricts to linear isomorphisms between fibers.
↑A line bundle, such as the tangent bundle of S1 is trivial if and only if there is a section that vanishes nowhere, see Husemoller (1994), Corollary 8.3. The sections of the tangent bundle are just vector fields.
Braun, Martin (1993), Differential equations and their applications: an introduction to applied mathematics, Berlin, New York: Springer-Verlag, ISBN978-0-387-97894-9
Dennery, Philippe; Krzywicki, Andre (1996), Mathematics for Physicists, Courier Dover Publications, ISBN978-0-486-69193-0
Dudley, Richard M. (1989), Real analysis and probability, The Wadsworth & Brooks/Cole Mathematics Series, Pacific Grove, CA: Wadsworth & Brooks/Cole Advanced Books & Software, ISBN978-0-534-10050-6
Folland, Gerald B. (1992), Fourier Analysis and Its Applications, Brooks-Cole, ISBN978-0-534-17094-3
Gasquet, Claude; Witomski, Patrick (1999), Fourier Analysis and Applications: Filtering, Numerical Computation, Wavelets, Texts in Applied Mathematics, New York: Springer-Verlag, ISBN978-0-387-98485-8
Ifeachor, Emmanuel C.; Jervis, Barrie W. (2001), Digital Signal Processing: A Practical Approach (2nded.), Harlow, Essex, England: Prentice-Hall (published 2002), ISBN978-0-201-59619-9
Krantz, Steven G. (1999), A Panorama of Harmonic Analysis, Carus Mathematical Monographs, Washington, DC: Mathematical Association of America, ISBN978-0-88385-031-2
Bellavitis, Giuso (1833), "Sopra alcune applicazioni di un nuovo metodo di geometria analitica", Il poligrafo giornale di scienze, lettre ed arti, 13, Verona: 53–61.
Bourbaki, Nicolas (1969), Éléments d'histoire des mathématiques (Elements of history of mathematics) (in French), Paris: Hermann
Peano, Giuseppe (1888), Calcolo Geometrico secondo l'Ausdehnungslehre di H. Grassmann preceduto dalle Operazioni della Logica Deduttiva (in Italian), Turin{{citation}}: CS1 maint: location missing publisher (link)
Hughes-Hallett, Deborah; McCallum, William G.; Gleason, Andrew M. (2013), Calculus: Single and Multivariable (6ed.), John Wiley & Sons, ISBN978-0470-88861-2
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.


























![Addition of functions: the sum of the sine and the exponential function is
sin
+
exp
:
R
-
R
{\displaystyle \sin +\exp
:\mathbb {R} \to \mathbb {R} }
with
(
sin
+
exp
)
(
x
)
=
sin
[?]
(
x
)
+
exp
[?]
(
x
)
{\displaystyle (\sin +\exp )(x)=\sin(x)+\exp(x)}
. Example for addition of functions.svg](http://upload.wikimedia.org/wikipedia/commons/thumb/d/d7/Example_for_addition_of_functions.svg/250px-Example_for_addition_of_functions.svg.png)





















































































































![Unit "spheres" in
R
2
{\displaystyle \mathbf {R} ^{2}}
consist of plane vectors of norm 1. Depicted are the unit spheres in different
p
{\displaystyle p}
-norms, for
p
=
1
,
2
,
{\displaystyle p=1,2,}
and
[?]
.
{\displaystyle \infty .}
The bigger diamond depicts points of 1-norm equal to 2. Vector norms2.svg](http://upload.wikimedia.org/wikipedia/commons/thumb/0/02/Vector_norms2.svg/250px-Vector_norms2.svg.png)
















































![A hyperbola, given by the equation
x
[?]
y
=
1.
{\displaystyle x\cdot y=1.}
The coordinate ring of functions on this hyperbola is given by
R
[
x
,
y
]
/
(
x
[?]
y
-
1
)
,
{\displaystyle \mathbf {R} [x,y]/(x\cdot y-1),}
an infinite-dimensional vector space over
R
.
{\displaystyle \mathbf {R} .} Rectangular hyperbola.svg](http://upload.wikimedia.org/wikipedia/commons/thumb/2/29/Rectangular_hyperbola.svg/250px-Rectangular_hyperbola.svg.png)



























