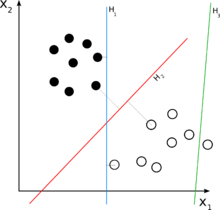
In machine learning, a linear classifier makes a classification decision for each object based on a linear combination of its features. Such classifiers work well for practical problems such as document classification, and more generally for problems with many variables (features), reaching accuracy levels comparable to non-linear classifiers while taking less time to train and use.[1]
In this case, the solid and empty dots can be correctly classified by any number of linear classifiers. H1 (blue) classifies them correctly, as does H2 (red). H2 could be considered "better" in the sense that it is also furthest from both groups. H3 (green) fails to correctly classify the dots.
If the input feature vector to the classifier is a real vector , then the output score is
where is a real vector of weights and f is a function that converts the dot product of the two vectors into the desired output. (In other words, is a one-form or linear functional mapping onto R.) The weight vector is learned from a set of labeled training samples. Often f is a threshold function, which maps all values of above a certain threshold to the first class and all other values to the second class; e.g.,
The superscript T indicates the transpose and is a scalar threshold. A more complex f might give the probability that an item belongs to a certain class.
For a two-class classification problem, one can visualize the operation of a linear classifier as splitting a high-dimensional input space with a hyperplane: all points on one side of the hyperplane are classified as "yes", while the others are classified as "no".
A linear classifier is often used in situations where the speed of classification is an issue, since it is often the fastest classifier, especially when is sparse. Also, linear classifiers often work very well when the number of dimensions in is large, as in document classification, where each element in is typically the number of occurrences of a word in a document (see document-term matrix). In such cases, the classifier should be well-regularized.
The second set of methods includes discriminative models, which attempt to maximize the quality of the output on a training set. Additional terms in the training cost function can easily perform regularization of the final model. Examples of discriminative training of linear classifiers include:
Logistic regression—maximum likelihood estimation of assuming that the observed training set was generated by a binomial model that depends on the output of the classifier.
Perceptron—an algorithm that attempts to fix all errors encountered in the training set
Fisher's Linear Discriminant Analysis—an algorithm (different than "LDA") that maximizes the ratio of between-class scatter to within-class scatter, without any other assumptions. It is in essence a method of dimensionality reduction for binary classification.[4]
Support vector machine—an algorithm that maximizes the margin between the decision hyperplane and the examples in the training set.
Note: Despite its name, LDA does not belong to the class of discriminative models in this taxonomy. However, its name makes sense when we compare LDA to the other main linear dimensionality reduction algorithm: principal components analysis (PCA). LDA is a supervised learning algorithm that utilizes the labels of the data, while PCA is an unsupervised learning algorithm that ignores the labels. To summarize, the name is a historical artifact.[5]
Discriminative training often yields higher accuracy than modeling the conditional density functions[citation needed]. However, handling missing data is often easier with conditional density models[citation needed].
All of the linear classifier algorithms listed above can be converted into non-linear algorithms operating on a different input space , using the kernel trick.
Discriminative training
Discriminative training of linear classifiers usually proceeds in a supervised way, by means of an optimization algorithm that is given a training set with desired outputs and a loss function that measures the discrepancy between the classifier's outputs and the desired outputs. Thus, the learning algorithm solves an optimization problem of the form[1]
where
w is a vector of classifier parameters,
L(yi, wTxi) is a loss function that measures the discrepancy between the classifier's prediction and the true output yi for the i'th training example,
R(w) is a regularization function that prevents the parameters from getting too large (causing overfitting), and
C is a scalar constant (set by the user of the learning algorithm) that controls the balance between the regularization and the loss function.
↑ Duda, Richard O.; Hart, Peter E.; Stork, David G. (2001). Pattern classification. A Wiley-Interscience publication (Seconded.). New York Chichester Weinheim Brisbane Singapore Toronto: John Wiley & Sons, Inc. p.117. ISBN978-0-471-05669-0.
Further reading
Y. Yang, X. Liu, "A re-examination of text categorization", Proc. ACM SIGIR Conference, pp.42–49, (1999). paper @ citeseer
R. Herbrich, "Learning Kernel Classifiers: Theory and Algorithms," MIT Press, (2001). ISBN0-262-08306-X
Related Research Articles
Supervised learning (SL) is a paradigm in machine learning where input objects and a desired output value train a model. The training data is processed, building a function that maps new data to expected output values. An optimal scenario will allow for the algorithm to correctly determine output values for unseen instances. This requires the learning algorithm to generalize from the training data to unseen situations in a "reasonable" way. This statistical quality of an algorithm is measured through the so-called generalization error.
In machine learning, support vector machines are supervised max-margin models with associated learning algorithms that analyze data for classification and regression analysis. Developed at AT&T Bell Laboratories by Vladimir Vapnik with colleagues, SVMs are one of the most studied models, being based on statistical learning frameworks of VC theory proposed by Vapnik and Chervonenkis (1974).
In statistics, naive Bayes classifiers are a family of linear "probabilistic classifiers" which assumes that the features are conditionally independent, given the target class. The strength (naivety) of this assumption is what gives the classifier its name. These classifiers are among the simplest Bayesian network models.
Pattern recognition is the task of assigning a class to an observation based on patterns extracted from data. While similar, pattern recognition (PR) is not to be confused with pattern machines (PM) which may possess (PR) capabilities but their primary function is to distinguish and create emergent patterns. PR has applications in statistical data analysis, signal processing, image analysis, information retrieval, bioinformatics, data compression, computer graphics and machine learning. Pattern recognition has its origins in statistics and engineering; some modern approaches to pattern recognition include the use of machine learning, due to the increased availability of big data and a new abundance of processing power.
In machine learning, the perceptron is an algorithm for supervised learning of binary classifiers. A binary classifier is a function which can decide whether or not an input, represented by a vector of numbers, belongs to some specific class. It is a type of linear classifier, i.e. a classification algorithm that makes its predictions based on a linear predictor function combining a set of weights with the feature vector.
Statistical learning theory is a framework for machine learning drawing from the fields of statistics and functional analysis. Statistical learning theory deals with the statistical inference problem of finding a predictive function based on data. Statistical learning theory has led to successful applications in fields such as computer vision, speech recognition, and bioinformatics.
In statistical classification, two main approaches are called the generative approach and the discriminative approach. These compute classifiers by different approaches, differing in the degree of statistical modelling. Terminology is inconsistent, but three major types can be distinguished, following Jebara (2004):
A generative model is a statistical model of the joint probability distribution on a given observable variable X and target variable Y; A generative model can be used to "generate" random instances (outcomes) of an observation x.
A discriminative model is a model of the conditional probability of the target Y, given an observation x. It can be used to "discriminate" the value of the target variable Y, given an observation x.
Classifiers computed without using a probability model are also referred to loosely as "discriminative".
Linear discriminant analysis (LDA), normal discriminant analysis (NDA), or discriminant function analysis is a generalization of Fisher's linear discriminant, a method used in statistics and other fields, to find a linear combination of features that characterizes or separates two or more classes of objects or events. The resulting combination may be used as a linear classifier, or, more commonly, for dimensionality reduction before later classification.
When classification is performed by a computer, statistical methods are normally used to develop the algorithm.
In machine learning, kernel machines are a class of algorithms for pattern analysis, whose best known member is the support-vector machine (SVM). These methods involve using linear classifiers to solve nonlinear problems. The general task of pattern analysis is to find and study general types of relations in datasets. For many algorithms that solve these tasks, the data in raw representation have to be explicitly transformed into feature vector representations via a user-specified feature map: in contrast, kernel methods require only a user-specified kernel, i.e., a similarity function over all pairs of data points computed using inner products. The feature map in kernel machines is infinite dimensional but only requires a finite dimensional matrix from user-input according to the Representer theorem. Kernel machines are slow to compute for datasets larger than a couple of thousand examples without parallel processing.
Conditional random fields (CRFs) are a class of statistical modeling methods often applied in pattern recognition and machine learning and used for structured prediction. Whereas a classifier predicts a label for a single sample without considering "neighbouring" samples, a CRF can take context into account. To do so, the predictions are modelled as a graphical model, which represents the presence of dependencies between the predictions. What kind of graph is used depends on the application. For example, in natural language processing, "linear chain" CRFs are popular, for which each prediction is dependent only on its immediate neighbours. In image processing, the graph typically connects locations to nearby and/or similar locations to enforce that they receive similar predictions.
In statistics, multinomial logistic regression is a classification method that generalizes logistic regression to multiclass problems, i.e. with more than two possible discrete outcomes. That is, it is a model that is used to predict the probabilities of the different possible outcomes of a categorically distributed dependent variable, given a set of independent variables.
Discriminative models, also referred to as conditional models, are a class of models frequently used for classification. They are typically used to solve binary classification problems, i.e. assign labels, such as pass/fail, win/lose, alive/dead or healthy/sick, to existing datapoints.
Structured prediction or structured (output) learning is an umbrella term for supervised machine learning techniques that involves predicting structured objects, rather than scalar discrete or real values.
In machine learning, the hinge loss is a loss function used for training classifiers. The hinge loss is used for "maximum-margin" classification, most notably for support vector machines (SVMs).
In statistics, ordinal regression, also called ordinal classification, is a type of regression analysis used for predicting an ordinal variable, i.e. a variable whose value exists on an arbitrary scale where only the relative ordering between different values is significant. It can be considered an intermediate problem between regression and classification. Examples of ordinal regression are ordered logit and ordered probit. Ordinal regression turns up often in the social sciences, for example in the modeling of human levels of preference, as well as in information retrieval. In machine learning, ordinal regression may also be called ranking learning.
In machine learning, the kernel perceptron is a variant of the popular perceptron learning algorithm that can learn kernel machines, i.e. non-linear classifiers that employ a kernel function to compute the similarity of unseen samples to training samples. The algorithm was invented in 1964, making it the first kernel classification learner.
In machine learning, Platt scaling or Platt calibration is a way of transforming the outputs of a classification model into a probability distribution over classes. The method was invented by John Platt in the context of support vector machines, replacing an earlier method by Vapnik, but can be applied to other classification models. Platt scaling works by fitting a logistic regression model to a classifier's scores.
In machine learning, a probabilistic classifier is a classifier that is able to predict, given an observation of an input, a probability distribution over a set of classes, rather than only outputting the most likely class that the observation should belong to. Probabilistic classifiers provide classification that can be useful in its own right or when combining classifiers into ensembles.
In statistics, linear regression is a statistical model that estimates the linear relationship between a scalar response and one or more explanatory variables. The case of one explanatory variable is called simple linear regression; for more than one, the process is called multiple linear regression. This term is distinct from multivariate linear regression, where multiple correlated dependent variables are predicted, rather than a single scalar variable. If the explanatory variables are measured with error then errors-in-variables models are required, also known as measurement error models.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.