Algorithms
There are a number of implementations of this method, the most notable are FGK (Faller-Gallager-Knuth) and Vitter algorithm.
FGK Algorithm
It is an online coding technique based on Huffman coding. Having no initial knowledge of occurrence frequencies, it permits dynamically adjusting the Huffman's tree as data are being transmitted. In a FGK Huffman tree, a special external node, called 0-node, is used to identify a newly coming character. That is, whenever new data is encountered, output the path to the 0-node followed by the data. For a past-coming character, just output the path of the data in the current Huffman's tree. Most importantly, we have to adjust the FGK Huffman tree if necessary, and finally update the frequency of related nodes. As the frequency of a datum is increased, the sibling property of the Huffman's tree may be broken. The adjustment is triggered for this reason. It is accomplished by consecutive swappings of nodes, subtrees, or both. The data node is swapped with the highest-ordered node of the same frequency in the Huffman's tree, (or the subtree rooted at the highest-ordered node). All ancestor nodes of the node should also be processed in the same manner.
Since the FGK Algorithm has some drawbacks about the node-or-subtree swapping, Vitter proposed another algorithm to improve it.
Vitter algorithm
Some important terminologies & constraints :-
- Implicit Numbering : It simply means that nodes are numbered in increasing order by level and from left to right. i.e. nodes at bottom level will have low implicit number as compared to upper level nodes and nodes on same level are numbered in increasing order from left to right. In other terms, when we have built the Huffman tree, when merging two nodes into a parent node, we have set the one with the lower value as the left child, and the one with the higher value as the right child.
- Invariant : For each weight w, all leaves of weight w precede all internal nodes having weight w. In other terms, when we have built the Huffman tree, if several nodes had the same value, we prioritized merging the leaves over the internal nodes.
- Blocks : Nodes of same weight and same type (i.e. either leaf node or internal node) form a Block.
- Leader : Highest numbered node in a block.
Blocks are interlinked by increasing order of their weights.
A leaf block always precedes internal block of same weight, thus maintaining the invariant.
NYT (Not Yet Transferred) is a special node used to represent symbols which are 'not yet transferred'.








algorithm for adding a symbol is leaf_to_increment := NULL p := pointer to the leaf node containing the next symbol if (p is NYT) then Extend p by adding two children Left child becomes new NYT and right child is the new symbol leaf node p := parent of new symbol leaf node leaf_to_increment := Right Child of p else Swap p with leader of its block if (new p is sibling to NYT) then leaf_to_increment := p p := parent of p while (p ≠ NULL) do Slide_And_Increment(p) if (leaf_to_increment != NULL) then Slide_And_Increment(leaf_to_increment)
function Slide_And_Increment(p) is previous_p := parent of pif (p is an internal node) then Slide p in the tree higher than the leaf nodes of weight wt + 1 increase weight of p by 1 p := previous_p else Slide p in the tree higher than the internal nodes of weight wt increase weight of p by 1 p := new parent of p.
Encoder and decoder start with only the root node, which has the maximum number. In the beginning it is our initial NYT node.
When we transmit an NYT symbol, we have to transmit code for the NYT node, then for its generic code.
For every symbol that is already in the tree, we only have to transmit code for its leaf node.
Example
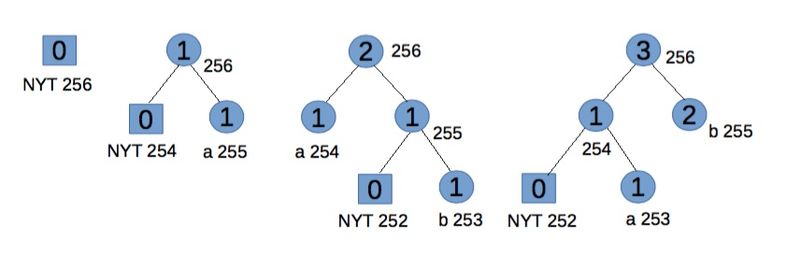
Encoding "abb" gives 01100001 001100010 11.
Step 1:
Start with an empty tree.
For "a" transmit its binary code.
Step 2:
NYT spawns two child nodes: 254 and 255, both with weight 0. Increase weight for root and 255. Code for "a", associated with node 255, is 1.
For "b" transmit 0 (for NYT node) then its binary code.
Step 3:
NYT spawns two child nodes: 252 for NYT and 253 for leaf node, both with weight 0. Increase weights for 253, 254, and root. To maintain Vitter's invariant that all leaves of weight w precede (in the implicit numbering) all internal nodes of weight w, the branch starting with node 254 should be swapped (in terms of symbols and weights, but not number ordering) with node 255. Code for "b" is 11.
For the second "b" transmit 11.
For the convenience of explanation this step doesn't exactly follow Vitter's algorithm, [2] but the effects are equivalent.
Step 4:
Go to leaf node 253. Notice we have two blocks with weight 1. Node 253 and 254 is one block (consisting of leaves), node 255 is another block (consisting of internal nodes). For node 253, the biggest number in its block is 254, so swap the weights and symbols of nodes 253 and 254. Now node 254 and the branch starting from node 255 satisfy the SlideAndIncrement condition [2] and hence must be swapped. At last increase node 255 and 256's weight.
Future code for "b" is 1, and for "a" is now 01, which reflects their frequency.






