The byte is a unit of digital information that most commonly consists of eight bits. Historically, the byte was the number of bits used to encode a single character of text in a computer[1][2] and for this reason it is the smallest addressable unit of memory in many computer architectures. To disambiguate arbitrarily sized bytes from the common 8-bit definition, network protocol documents such as the Internet Protocol ( RFC791) refer to an 8-bit byte as an octet.[3] Those bits in an octet are usually counted with numbering from 0 to 7 or 7 to 0 depending on the bit endianness.
The size of the byte has historically been hardware-dependent and no definitive standards existed that mandated the size. Sizes from 1 to 48 bits have been used.[4][5][6][7] The six-bit character code was an often-used implementation in early encoding systems, and computers using six-bit and nine-bit bytes were common in the 1960s. These systems often had memory words of 12, 18, 24, 30, 36, 48, or 60 bits, corresponding to 2, 3, 4, 5, 6, 8, or 10 six-bit bytes, and persisted, in legacy systems, into the twenty-first century. In this era, bit groupings in the instruction stream were often referred to as syllables[a] or slab, before the term byte became common.
The modern de facto standard of eight bits, as documented in ISO/IEC 2382-1:1993, is a convenient power of two permitting the binary-encoded values 0 through 255 for one byte, as 2 to the power of 8 is 256.[8] The international standard IEC 80000-13 codified this common meaning. Many types of applications use information representable in eight or fewer bits and processor designers commonly optimize for this usage. The popularity of major commercial computing architectures has aided in the ubiquitous acceptance of the 8-bit byte.[9] Modern architectures typically use 32- or 64-bit words, built of four or eight bytes, respectively.
The unit symbol for the byte was designated as the upper-case letter B by the International Electrotechnical Commission (IEC) and Institute of Electrical and Electronics Engineers (IEEE).[10] Internationally, the unit octet explicitly defines a sequence of eight bits, eliminating the potential ambiguity of the term "byte".[11][12] The symbol for octet, 'o', also conveniently eliminates the ambiguity in the symbol 'B' between byte and bel.
Etymology and history
The term byte was coined by Werner Buchholz in June 1956,[4][13][14][b] during the early design phase for the IBM Stretch[15][16][1][13][14][17][18] computer, which had addressing to the bit and variable field length (VFL) instructions with a byte size encoded in the instruction.[13] It is a deliberate respelling of bite to avoid accidental mutation to bit.[1][13][19][c]
Another origin of byte for bit groups smaller than a computer's word size, and in particular groups of four bits, is on record by Louis G. Dooley, who claimed he coined the term while working with Jules Schwartz and Dick Beeler on an air defense system called SAGE at MIT Lincoln Laboratory in 1956 or 1957, which was jointly developed by Rand, MIT, and IBM.[20][21] Later on, Schwartz's language JOVIAL actually used the term, but the author recalled vaguely that it was derived from AN/FSQ-31.[22][21]
Early computers used a variety of four-bit binary-coded decimal (BCD) representations and the six-bit codes for printable graphic patterns common in the U.S. Army (FIELDATA) and Navy. These representations included alphanumeric characters and special graphical symbols. These sets were expanded in 1963 to seven bits of coding, called the American Standard Code for Information Interchange (ASCII) as the Federal Information Processing Standard, which replaced the incompatible teleprinter codes in use by different branches of the U.S. government and universities during the 1960s. ASCII included the distinction of upper- and lowercase alphabets and a set of control characters to facilitate the transmission of written language as well as printing device functions, such as page advance and line feed, and the physical or logical control of data flow over the transmission media.[18] During the early 1960s, while also active in ASCII standardization, IBM simultaneously introduced in its product line of System/360 the eight-bit Extended Binary Coded Decimal Interchange Code (EBCDIC), an expansion of their six-bit binary-coded decimal (BCDIC) representations[d] used in earlier card punches.[23] The prominence of the System/360 led to the ubiquitous adoption of the eight-bit storage size,[18][16][13] while in detail the EBCDIC and ASCII encoding schemes are different.
In the early 1960s, AT&T introduced digital telephony on long-distance trunk lines. These used the eight-bit μ-law encoding. This large investment promised to reduce transmission costs for eight-bit data.
In Volume 1 of The Art of Computer Programming (first published in 1968), Donald Knuth uses byte in his hypothetical MIX computer to denote a unit which "contains an unspecified amount of information ... capable of holding at least 64 distinct values ... at most 100 distinct values. On a binary computer a byte must therefore be composed of six bits".[24] He notes that "Since 1975 or so, the word byte has come to mean a sequence of precisely eight binary digits...When we speak of bytes in connection with MIX we shall confine ourselves to the former sense of the word, harking back to the days when bytes were not yet standardized."[24]
The development of eight-bitmicroprocessors in the 1970s popularized this storage size. Microprocessors such as the Intel 8080, the direct predecessor of the 8086, could also perform a small number of operations on the four-bit pairs in a byte, such as the decimal-add-adjust (DAA) instruction. A four-bit quantity is often called a nibble, also nybble, which is conveniently represented by a single hexadecimal digit.
The term octet unambiguously specifies a size of eight bits.[18][12] It is used extensively in protocol definitions.
Historically, the term octad or octade was used to denote eight bits as well at least in Western Europe;[25][26] however, this usage is no longer common. The exact origin of the term is unclear, but it can be found in British, Dutch, and German sources of the 1960s and 1970s, and throughout the documentation of Philips mainframe computers.
In the International System of Quantities (ISQ), B is also the symbol of the bel, a unit of logarithmic power ratio named after Alexander Graham Bell, creating a conflict with the IEC specification. However, little danger of confusion exists, because the bel is a rarely used unit. It is used primarily in its decadic fraction, the decibel (dB), for signal strength and sound pressure level measurements, while a unit for one-tenth of a byte, the decibyte, and other fractions, are only used in derived units, such as transmission rates.
The lowercase letter o for octet is defined as the symbol for octet in IEC80000-13 and is commonly used in languages such as French[27] and Romanian, and is also combined with metric prefixes for multiples, for example ko and Mo.
Unit multiples of the byte are defined in a metric system based on the powers of 10, following the International System of Units (SI), which defines, for example, the prefix kilo as 1000 (103), as well as a binary system based on powers of two. Historically, the binary system used the identical prefixes of the metric system, but quantified differently. The nomenclature of the latter system has led to confusion. Systems based on powers of 10 use standard SI prefixes (kilo, mega, giga, ...) and their corresponding symbols (k, M, G, ...). The modern binary system uses prefixes kibi, mebi, gibi, etc., and their corresponding symbols (Ki, Mi, Gi, ...). Historical usage for the binary system still uses the prefixes K, M, and G.
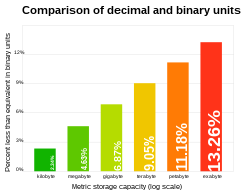
While the difference between the decimal and binary interpretations is relatively small for the kilobyte (about 2% smaller than the kibibyte), the systems deviate increasingly as units grow larger (the relative deviation grows by 2.4% for each three orders of magnitude). For example, a power-of-10-based terabyte is about 9% smaller than power-of-2-based tebibyte.
Units based on powers of 10 (SI Prefixes)
Definition of prefixes using powers of 10—in which 1 kilobyte (symbol kB) is defined to equal 1,000 bytes—is recommended by the International Electrotechnical Commission (IEC).[28] The IEC standard defines eight such multiples, up to 1 yottabyte (YB), equal to 10008 bytes.[29] The additional prefixes ronna- for 10009 and quetta- for 100010 were adopted by the International Bureau of Weights and Measures (BIPM) in 2022.[30][31]
The IBM System 360 and the related disk and tape systems set the byte at 8 bits and documented capacities in decimal units.[38] The early 8-, 5.25- and 3.5-inch floppies gave capacities in multiples of 1024, using "KB" rather than the more accurate "KiB". The later, larger, 8-, 5.25- and 3.5-inch floppies gave capacities in a hybrid notation, i.e., multiples of 1024,000, using "KB" = 1024 B and "MB" = 1024,000 B. Early 5.25-inch disks used decimal[dubious–discuss] even though they used 128-byte and 256-byte sectors.[39] Hard disks used mostly 256-byte and then 512-byte before 4096-byte blocks became standard.[40]
Units based on powers of 2 (IEC Prefixes)
A system of units based on powers of 2 in which 1 kibibyte (KiB) is equal to 1,024 (i.e., 210) bytes was created by the IEC to solve the confusion over incorrect usage of SI prefixes[41] and is defined by international standard IEC80000-13 and is supported by national and international standards bodies (BIPM, IEC, NIST). The IEC standard defines ten such multiples, up to 1 quebibyte (QiB), equal to 102410 bytes.[42] These unit symbols are rarely used in practice.[43] Notable exceptions are KDE and applications based on the Qt toolkit but the KDE settings app allows switching to SI.[44]
A historic convention of nomenclature for the same units, in which 1 kilobyte (KB) is equal to 1,024 bytes,[45][46][47] 1 megabyte (MB) is equal to 10242 bytes and 1 gigabyte (GB) is equal to 10243 bytes is mentioned by a 1990s JEDEC standard which is used for RAM. Only the first three multiples (up to GB) are mentioned by the JEDEC standard, which makes no mention of TB and larger. These units can only be recognized through comparison using different software. Sometimes the capitalization of the K in KB can be an indicator. While confusing and incorrect,[48] this convention is used by the Microsoft Windows operating system[49] and random-access memory capacity, such as main memory and CPU cache size, and in marketing and billing by some telecommunication companies, such as Vodafone,[50]AT&T,[51]Orange[52] and Telstra.[53] For storage capacity, the historic convention was used by macOS and iOS through Mac OS X 10.5 Leopard and iOS 10, after which they switched to units based on powers of 10.[35]
Parochial units
Various computer vendors have coined terms for data of various sizes, sometimes with different sizes for the same term even within a single vendor. These terms include double word, half word, long word, quad word, slab, superword and syllable. There are also informal terms. e.g., half byte and nybble for 4 bits, octal K for 10008.
History of the conflicting definitions
Percentage difference between decimal and binary interpretations of the unit prefixes grows with increasing storage size
When I see a disk advertised as having a capacity of one megabyte, what is this telling me? There are three plausible answers, and I wonder if anybody knows which one is correct ... Now this is not a really vital issue, as there is just under 5% difference between the smallest and largest alternatives. Nevertheless, it would [be] nice to know what the standard measure is, or if there is one.
—Allan D. Pratt of Small Computers in Libraries, 1982[54]
Contemporary[e] computer memory has a binary architecture making a definition of memory units based on powers of 2 most practical. The use of the metric prefix kilo for binary multiples arose as a convenience, because 1024 is approximately 1000.[27] This definition was popular in early decades of personal computing, with products like the Tandon 51⁄4-inch DD floppy format (holding 368640 bytes) being advertised as "360KB", following the 1024-byte convention. It was not universal, however. The Shugart SA-400 51⁄4-inch floppy disk held 109,375 bytes unformatted,[55] and was advertised as "110Kbyte", using the 1000 convention.[56] Likewise, the 8-inch DEC RX01 floppy (1975) held 256256 bytes formatted, and was advertised as "256k".[57] Some devices were advertised using a mixture of the two definitions: most notably, floppy disks advertised as "1.44MB" have an actual capacity of 1440KiB, the equivalent of 1.47MB or 1.41MiB.
In 1995, the International Union of Pure and Applied Chemistry's (IUPAC) Interdivisional Committee on Nomenclature and Symbols attempted to resolve this ambiguity by proposing a set of binary prefixes for the powers of 1024, including kibi (kilobinary), mebi (megabinary), and gibi (gigabinary).[58][59]
In December 1998, the IEC addressed such multiple usages and definitions by adopting the IUPAC's proposed prefixes (kibi, mebi, gibi, etc.) to unambiguously denote powers of 1024.[60] Thus one kibibyte (1KiB) is 10241 bytes = 1024 bytes, one mebibyte (1MiB) is 10242 bytes = 1048576 bytes, and so on.
In 1999, Donald Knuth suggested calling the kibibyte a "large kilobyte" (KKB).[61]
Modern standard definitions
The IEC adopted the IUPAC proposal and published the standard in January 1999.[62][63] The IEC prefixes are part of the International System of Quantities. The IEC further specified that the kilobyte should only be used to refer to 1000 bytes.[64]
Lawsuits over definition
Lawsuits arising from alleged consumer confusion over the binary and decimal definitions of multiples of the byte have generally ended in favor of the manufacturers, with courts holding that the legal definition of gigabyte or GB is 1GB = 1000000000 (109) bytes (the decimal definition), rather than the binary definition (230, i.e., 1073741824). Specifically, the United States District Court for the Northern District of California held that "the U.S. Congress has deemed the decimal definition of gigabyte to be the 'preferred' one for the purposes of 'U.S. trade and commerce' [...] The California Legislature has likewise adopted the decimal system for all 'transactions in this state.'"[65]
Earlier lawsuits had ended in settlement with no court ruling on the question, such as a lawsuit against drive manufacturer Western Digital.[66][67] Western Digital settled the challenge and added explicit disclaimers to products that the usable capacity may differ from the advertised capacity.[66] Seagate was sued on similar grounds and also settled.[66][68]
Practical examples
Unit
Approximate equivalent
bit
a Boolean variable indicating true (1) or false (0)
The C and C++ programming languages define byte as an "addressable unit of data storage large enough to hold any member of the basic character set of the execution environment" (clause 3.6 of the C standard). The C standard requires that the integral data type unsigned char must hold at least 256 different values, and is represented by at least eight bits (clause 5.2.4.2.1). Various implementations of C and C++ reserve 8, 9, 16, 32, or 36 bits for the storage of a byte.[82][83][f] In addition, the C and C++ standards require that there be no gaps between two bytes. This means every bit in memory is part of a byte.[84]
However almost all modern software would not actually work if compiled with a byte size other than 8 bit. Further POSIX says “A byte is composed of a contiguous sequence of 8 bits.”[85] Today non-8bit-bytes only find niche application like in DSPs.
In data transmission systems, the byte is used as a contiguous sequence of bits in a serial data stream, representing the smallest distinguished unit of data. For asynchronous communication a full transmission unit usually additionally includes a start bit, 1 or 2 stop bits, and possibly a parity bit, and thus its size may vary from seven to twelve bits for five to eight bits of actual data.[86] For synchronous communication the error checking usually uses bytes at the end of a frame.
↑The term syllable was used for bytes containing instructions or constituents of instructions, not for data bytes.
↑Many sources erroneously indicate a birthday of the term byte in July 1956, but Werner Buchholz claimed that the term would have been coined in June 1956. In fact, the earliest document supporting this dates from 1956-06-11. Buchholz stated that the transition to 8-bit bytes was conceived in August 1956, but the earliest document found using this notion dates from September 1956.
↑Some later machines, e.g., Burroughs B1700, CDC 3600, DEC PDP-6, DEC PDP-10 had the ability to operate on arbitrary bytes no larger than the word size.
Terms used here to describe the structure imposed by the machine design, in addition to bit, are listed below. Byte denotes a group of bits used to encode a character, or the number of bits transmitted in parallel to and from input-output units. A term other than character is used here because a given character may be represented in different applications by more than one code, and different codes may use different numbers of bits (i.e., different byte sizes). In input-output transmission the grouping of bits may be completely arbitrary and have no relation to actual characters. (The term is coined from bite, but respelled to avoid accidental mutation to bit.) A word consists of the number of data bits transmitted in parallel from or to memory in one memory cycle. Word size is thus defined as a structural property of the memory. (The term catena was coined for this purpose by the designers of the BullGAMMA 60[fr] computer.) Block refers to the number of words transmitted to or from an input-output unit in response to a single input-output instruction. Block size is a structural property of an input-output unit; it may have been fixed by the design or left to be varied by the program.
[...] Most important, from the point of view of editing, will be the ability to handle any characters or digits, from 1 to 6 bits long. Figure 2 shows the Shift Matrix to be used to convert a 60-bit word, coming from Memory in parallel, into characters, or 'bytes' as we have called them, to be sent to the Adder serially. The 60 bits are dumped into magnetic cores on six different levels. Thus, if a 1 comes out of position 9, it appears in all six cores underneath. Pulsing any diagonal line will send the six bits stored along that line to the Adder. The Adder may accept all or only some of the bits. Assume that it is desired to operate on 4 bit decimal digits, starting at the right. The 0-diagonal is pulsed first, sending out the six bits 0 to 5, of which the Adder accepts only the first four (0-3). Bits 4 and 5 are ignored. Next, the 4 diagonal is pulsed. This sends out bits 4 to 9, of which the last two are again ignored, and so on. It is just as easy to use all six bits in alphanumeric work, or to handle bytes of only one bit for logical analysis, or to offset the bytes by any number of bits. All this can be done by pulling the appropriate shift diagonals. An analogous matrix arrangement is used to change from serial to parallel operation at the output of the adder. [...]
↑Tafel, Hans Jörg (1971). Einführung in die digitale Datenverarbeitung[Introduction to digital information processing] (in German). Munich: Carl Hanser Verlag. p.300. ISBN3-446-10569-7. Byte = zusammengehörige Folge von i.a. neun Bits; davon sind acht Datenbits, das neunte ein Prüfbit NB. Defines a byte as a group of typically 9 bits; 8 data bits plus 1 parity bit.
↑ISO/IEC 2382-1: 1993, Information technology - Vocabulary - Part 1: Fundamental terms. 1993.
byte: A string that consists of a number of bits, treated as a unit, and usually representing a character or a part of a character. NOTES: 1 The number of bits in a byte is fixed for a given data processing system. 2 The number of bits in a byte is usually 8.
We received the following from W Buchholz, one of the individuals who was working on IBM's Project Stretch in the mid 1950s. His letter tells the story.
Not being a regular reader of your magazine, I heard about the question in the November 1976 issue regarding the origin of the term "byte" from a colleague who knew that I had perpetrated this piece of jargon [see page 77 of November 1976 BYTE, "Olde Englishe"]. I searched my files and could not locate a birth certificate. But I am sure that "byte" is coming of age in 1977 with its 21st birthday. Many have assumed that byte, meaning 8 bits, originated with the IBM System/360, which spread such bytes far and wide in the mid-1960s. The editor is correct in pointing out that the term goes back to the earlier Stretch computer (but incorrect in that Stretch was the first, not the last, of IBM's second-generation transistorized computers to be developed). The first reference found in the files was contained in an internal memo written in June 1956 during the early days of developing Stretch. A byte was described as consisting of any number of parallel bits from one to six. Thus a byte was assumed to have a length appropriate for the occasion. Its first use was in the context of the input-output equipment of the 1950s, which handled six bits at a time. The possibility of going to 8-bit bytes was considered in August 1956 and incorporated in the design of Stretch shortly thereafter. The first published reference to the term occurred in 1959 in a paper 'Processing Data in Bits and Pieces' by G A Blaauw, F P Brooks Jr and W Buchholz in the IRE Transactions on Electronic Computers, June 1959, page 121. The notions of that paper were elaborated in Chapter 4 of Planning a Computer System (Project Stretch), edited by W Buchholz, McGraw-Hill Book Company (1962). The rationale for coining the term was explained there on page 40 as follows: Byte denotes a group of bits used to encode a character, or the number of bits transmitted in parallel to and from input-output units. A term other than character is used here because a given character may be represented in different applications by more than one code, and different codes may use different numbers of bits (ie, different byte sizes). In input-output transmission the grouping of bits may be completely arbitrary and have no relation to actual characters. (The term is coined frombite, but respelled to avoid accidental mutation to bit.) System/360 took over many of the Stretch concepts, including the basic byte and word sizes, which are powers of 2. For economy, however, the byte size was fixed at the 8 bit maximum, and addressing at the bit level was replaced by byte addressing. Since then the term byte has generally meant 8 bits, and it has thus passed into the general vocabulary. Are there any other terms coined especially for the computer field which have found their way into general dictionaries of English language?
1956 Summer: Gerrit Blaauw, Fred Brooks, Werner Buchholz, John Cocke and Jim Pomerene join the Stretch team. Lloyd Hunter provides transistor leadership. 1956 July[sic]: In a report Werner Buchholz lists the advantages of a 64-bit word length for Stretch. It also supports NSA's requirement for 8-bit bytes. Werner's term "Byte" first popularized in this memo.
NB. This timeline erroneously specifies the birth date of the term "byte" as July 1956, while Buchholz actually used the term as early as June 1956.
[...] 60 is a multiple of 1, 2, 3, 4, 5, and 6. Hence bytes of length from 1 to 6 bits can be packed efficiently into a 60-bit word without having to split a byte between one word and the next. If longer bytes were needed, 60 bits would, of course, no longer be ideal. With present applications, 1, 4, and 6 bits are the really important cases. With 64-bit words, it would often be necessary to make some compromises, such as leaving 4 bits unused in a word when dealing with 6-bit bytes at the input and output. However, the LINK Computer can be equipped to edit out these gaps and to permit handling of bytes which are split between words. [...]
[...] The maximum input-output byte size for serial operation will now be 8 bits, not counting any error detection and correction bits. Thus, the Exchange will operate on an 8-bit byte basis, and any input-output units with less than 8 bits per byte will leave the remaining bits blank. The resultant gaps can be edited out later by programming [...]
I came to work for IBM, and saw all the confusion caused by the 64-character limitation. Especially when we started to think about word processing, which would require both upper and lower case. Add 26 lower case letters to 47 existing, and one got 73 -- 9 more than 6 bits could represent. I even made a proposal (in view of STRETCH, the very first computer I know of with an 8-bit byte) that would extend the number of punch card character codes to 256 [1]. Some folks took it seriously. I thought of it as a spoof. So some folks started thinking about 7-bit characters, but this was ridiculous. With IBM's STRETCH computer as background, handling 64-character words divisible into groups of 8 (I designed the character set for it, under the guidance of Dr. Werner Buchholz, the man who DID coin the term "byte" for an 8-bit grouping). [2] It seemed reasonable to make a universal 8-bit character set, handling up to 256. In those days my mantra was "powers of 2 are magic". And so the group I headed developed and justified such a proposal [3]. That was a little too much progress when presented to the standards group that was to formalize ASCII, so they stopped short for the moment with a 7-bit set, or else an 8-bit set with the upper half left for future work. The IBM 360 used 8-bit characters, although not ASCII directly. Thus Buchholz's "byte" caught on everywhere. I myself did not like the name for many reasons. The design had 8 bits moving around in parallel. But then came a new IBM part, with 9 bits for self-checking, both inside the CPU and in the tape drives. I exposed this 9-bit byte to the press in 1973. But long before that, when I headed software operations for Cie. Bull in France in 1965-66, I insisted that 'byte' be deprecated in favor of "octet". You can notice that my preference then is now the preferred term. It is justified by new communications methods that can carry 16, 32, 64, and even 128 bits in parallel. But some foolish people now refer to a "16-bit byte" because of this parallel transfer, which is visible in the UNICODE set. I'm not sure, but maybe this should be called a "hextet". But you will notice that I am still correct. Powers of 2 are still magic!
The word byte was coined around 1956 to 1957 at MIT Lincoln Laboratories within a project called SAGE (the North American Air Defense System), which was jointly developed by Rand, Lincoln Labs, and IBM. In that era, computer memory structure was already defined in terms of word size. A word consisted of x number of bits; a bit represented a binary notational position in a word. Operations typically operated on all the bits in the full word. We coined the word byte to refer to a logical set of bits less than a full word size. At that time, it was not defined specifically as x bits but typically referred to as a set of 4 bits, as that was the size of most of our coded data items. Shortly afterward, I went on to other responsibilities that removed me from SAGE. After having spent many years in Asia, I returned to the U.S. and was bemused to find out that the word byte was being used in the new microcomputer technology to refer to the basic addressable memory unit.
A question-and-answer session at an ACM conference on the history of programming languages included this exchange:
[ John Goodenough: You mentioned that the term "byte" is used in JOVIAL. Where did the term come from? ] [ Jules Schwartz (inventor of JOVIAL): As I recall, the AN/FSQ-31, a totally different computer than the 709, was byte oriented. I don't recall for sure, but I'm reasonably certain the description of that computer included the word "byte," and we used it. ] [ Fred Brooks: May I speak to that? Werner Buchholz coined the word as part of the definition of STRETCH, and the AN/FSQ-31 picked it up from STRETCH, but Werner is very definitely the author of that word. ] [ Schwartz: That's right. Thank you. ]
12Knuth, Donald (1997) [1968]. The Art of Computer Programming: Volume 1: Fundamental Algorithms (3rded.). Boston: Addison-Wesley. p.125. ISBN9780201896831.
↑Bennett, Hugh (1999). "Pioneer DVD-S201 4.7GB DVD-Recorder". EMedia. Vol.12, no.12. ISSN1529-7306. DVD nomenclature defines one gigabyte as one billion bytes...
↑Amendment 2 to IEC International Standard IEC60027-2: Letter symbols to be used in electrical technology – Part 2: Telecommunications and electronics.
↑Barrow, Bruce (January 1997). "A Lesson in Megabytes"(PDF). IEEE. p.5. Archived from the original(PDF) on 17 December 2005. Retrieved 14 December 2024.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.