Interval arithmetic (also known as interval mathematics, interval analysis or interval computation) is a mathematical technique used to mitigate rounding and measurement errors in mathematical computation by computing function bounds. Numerical methods involving interval arithmetic can guarantee relatively reliable and mathematically correct results. Instead of representing a value as a single number, interval arithmetic or interval mathematics represents each value as a range of possibilities.
Mathematically, instead of working with an uncertain real-valued variable x, interval arithmetic works with an interval [a, b] that defines the range of values that x can have. In other words, any value of the variable x lies in the closed interval between a and b. A function f, when applied to x, produces an interval [c, d] which includes all the possible values for f(x) for all x ∈ [a, b].
Interval arithmetic is suitable for a variety of purposes; the most common use is in scientific works, particularly when the calculations are handled by software, where it is used to keep track of rounding errors in calculations and of uncertainties in the knowledge of the exact values of physical and technical parameters. The latter often arise from measurement errors and tolerances for components or due to limits on computational accuracy. Interval arithmetic also helps find guaranteed solutions to equations (such as differential equations) and optimization problems.
Introduction
The main objective of interval arithmetic is to provide a simple way of calculating upper and lower bounds of a function's range in one or more variables. These endpoints are not necessarily the true supremum or infimum of a range since the precise calculation of those values can be difficult or impossible; the bounds only need to contain the function's range as a subset.
This treatment is typically limited to real intervals, so quantities in the form
where a = −∞ and b = ∞ are allowed. With one of a, b infinite, the interval would be an unbounded interval; with both infinite, the interval would be the extended real number line. Since a real number r can be interpreted as the interval [r, r], intervals and real numbers can be freely combined.
Example
Body mass index for a person 1.80m tall in relation to body weight m (in kilograms)
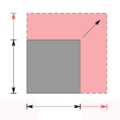
Consider the calculation of a person's body mass index (BMI). BMI is calculated as a person's body weight in kilograms divided by the square of their height in meters. Suppose a person uses a scale that has a precision of one kilogram, where intermediate values cannot be discerned, and the true weight is rounded to the nearest whole number. For example, 79.6kg and 80.3kg are indistinguishable, as the scale can only display values to the nearest kilogram. It is unlikely that when the scale reads 80kg, the person has a weight of exactly 80.0kg. Thus, the scale displaying 80kg indicates a weight between 79.5kg and 80.5kg, or the interval [79.5, 80.5).
The BMI of a man who weighs 80kg and is 1.80m tall is approximately 24.7. A weight of 79.5kg and the same height yields a BMI of 24.537, while a weight of 80.5kg yields 24.846. Since the body mass is continuous and always increasing for all values within the specified weight interval, the true BMI must lie within the interval [24.537, 24.846]. Since the entire interval is less than 25, which is the cutoff between normal and excessive weight, it can be concluded with certainty that the man is of normal weight.
The error in this example does not affect the conclusion (normal weight), but this is not generally true. If the man were slightly heavier, the BMI's range may include the cutoff value of 25. In such a case, the scale's precision would be insufficient to make a definitive conclusion.
The range of BMI examples could be reported as [24.5, 24.9] since this interval is a superset of the calculated interval. The range could not, however, be reported as [24.6, 24.8], as the interval does not contain possible BMI values.
Multiple intervals
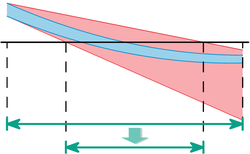
Body mass index for different weights in relation to height L (in meters)
Height and body weight both affect the value of the BMI. Though the example above only considered variation in weight, height is also subject to uncertainty. Height measurements in meters are usually rounded to the nearest centimeter: a recorded measurement of 1.79 meters represents a height in the interval [1.785, 1.795). Since the BMI uniformly increases with respect to weight and decreases with respect to height, the error interval can be calculated by substituting the lowest and highest values of each interval, and then selecting the lowest and highest results as boundaries. The BMI must therefore exist in the interval
In this case, the man may have normal weight or be overweight; the weight and height measurements were insufficiently precise to make a definitive conclusion.
Interval operators
A binary operation ∗ on two intervals, such as addition or multiplication is defined by
In other words, it is the set of all possible values of x ∗ y, where x and y are in their corresponding intervals. If ∗ is monotone for each operand on the intervals, which is the case for the four basic arithmetic operations (except division when the denominator contains zero), the extreme values occur at the endpoints of the operand intervals. Writing out all combinations, one way of stating this is
provided that x ∗ y is defined for all x ∈ [x1, x2] and y ∈ [y1, y2].
For practical applications, this can be simplified further:
The last case loses useful information about the exclusion of (1/y1, 1/y2). Thus, it is common to work with [-∞, 1/y1] and [1/y2, ∞] as separate intervals. More generally, when working with discontinuous functions, it is sometimes useful to do the calculation with so-called multi-intervals of the form ⋃i[ai, bi]. The corresponding multi-interval arithmetic maintains a set of (usually disjoint) intervals and also provides for overlapping intervals to unite.[1]
Multiplication of positive intervals
Interval multiplication often only requires two multiplications. If x1, y1 are nonnegative,
The multiplication can be interpreted as the area of a rectangle with varying edges. The result interval covers all possible areas, from the smallest to the largest.
With the help of these definitions, it is already possible to calculate the range of simple functions, such as f(a,b,x) = ax + b. For example, if a = [1, 2], b = [5, 7] and x = [2, 3]:
Notation
To shorten the notation of intervals, brackets can be used.
[x] ≡ [x1, x2] can be used to represent an interval. Note that in such a compact notation, [x] should not be confused between a single-point interval [x1, x1] and a general interval. For the set of all intervals, we can use
as an abbreviation. For a vector of intervals we can use a bold font:
Elementary functions
Values of a monotonic function
Interval functions beyond the four basic operators may also be defined.
For monotonic functions in one variable, the range of values is simple to compute. If f: ℝ → ℝ is monotonically increasing in the interval [x1, x2], then for all y1, y2 ∈ [x1, x2] such that y1 < y2, then f(y1) ≤ f(y2) (and if f is decreasing, f(y1) ≥ f(y2)).
The range corresponding to the interval [y1, y2] ⊆ [x1, x2] can be therefore calculated by applying the function to its endpoints:
From this, the following basic features for interval functions can easily be defined:
For even powers, the range of values being considered is important and needs to be dealt with before doing any multiplication. For example, xn for x ∈ [−1, 1] should produce the interval [0, 1] for even n ∈ ℕ. But if [−1, 1]n is taken by repeating interval multiplication of form [−1, 1] · [−1, 1] · ⋯ · [−1, 1] then the result is [−1, 1], wider than necessary.
More generally one can say that, for piecewise monotonic functions, it is sufficient to consider the endpoints x1, x2 of an interval, together with the so-called critical points within the interval, being those points where the monotonicity of the function changes direction. For the sine and cosine functions, the critical points are respectively at (n + 1/2)π and nπ, for n ∈ ℤ. Thus, only up to five points within an interval need to be considered, as the resulting interval is [−1, 1] if the interval includes at least two extrema. For sine and cosine, only the endpoints need full evaluation, as the critical points lead to easily pre-calculated values—namely −1, 0, and 1.
Interval extensions of general functions
In general, it may not be easy to find such a simple description of the output interval for many functions. But it may still be possible to extend functions to interval arithmetic. If f: ℝn → ℝ is a function from a real vector to a real number, then [f]: [ℝ]n → [ℝ] is called an interval extension of f if
This definition of the interval extension does not give a precise result. For example, both [f]([x1, x2]) = [ex1, ex2] and [g]([x1, x2]) = [−∞, ∞] are allowable extensions of the exponential function. Tighter extensions are desirable, though the relative costs of calculation and imprecision should be considered; in this case, [f] should be chosen as it gives the tightest possible result.
Given a real expression, its natural interval extension is achieved by using the interval extensions of each of its subexpressions, functions, and operators.
The Taylor interval extension (of degree k) is a k + 1 times differentiable function f defined by
for some y ∈ [x], where Dif(y) is the ith order differential of f at the point y and [r] is an interval extension of the Taylor remainder.
Mean value form
The vector ξ lies between x and y with x, y ∈ [x]; ξ is protected by [x]. Usually y is chosen to be the midpoint of the interval and uses the natural interval extension to assess the remainder.
The special case of the Taylor interval extension of degree k = 0 is also referred to as the mean value form.
Complex interval arithmetic
An interval can be defined as a set of points within a specified distance of the center, and this definition can be extended from real numbers to complex numbers.[2] Another extension defines intervals as rectangles in the complex plane. As is the case with computing with real numbers, computing with complex numbers involves uncertain data. So, given the fact that an interval number is a real closed interval and a complex number is an ordered pair of real numbers, there is no reason to limit the application of interval arithmetic to the measure of uncertainties in computations with real numbers.[3] Interval arithmetic can thus be extended, via complex interval numbers, to determine regions of uncertainty in computing with complex numbers. One can either define complex interval arithmetic using rectangles or using disks, both with their respective advantages and disadvantages.[3]
The basic algebraic operations for real interval numbers (real closed intervals) can be extended to complex numbers. It is therefore not surprising that complex interval arithmetic is similar to, but not the same as, ordinary complex arithmetic.[3] It can be shown that, as is the case with real interval arithmetic, there is no distributivity between the addition and multiplication of complex interval numbers except for certain special cases, and inverse elements do not always exist for complex interval numbers.[3] Two other useful properties of ordinary complex arithmetic fail to hold in complex interval arithmetic: the additive and multiplicative properties, of ordinary complex conjugates, do not hold for complex interval conjugates.[3]
Interval arithmetic can be extended, in an analogous manner, to other multidimensional number systems such as quaternions and octonions, but with the expense that we have to sacrifice other useful properties of ordinary arithmetic.[3]
The methods of classical numerical analysis cannot be transferred one-to-one into interval-valued algorithms, as dependencies between numerical values are usually not taken into account.
Rounded interval arithmetic
Outer bounds at different level of rounding
To work effectively in a real-life implementation, intervals must be compatible with floating point computing. The earlier operations were based on exact arithmetic, but in general fast numerical solution methods may not be available for it. The range of values of the function f(x, y) = x + y for x ∈ [0.1, 0.8] and y ∈ [0.06, 0.08] are in this example [0.16, 0.88]. Where the same calculation is done with single-digit precision, the result would normally be [0.2, 0.9]. But [0.2, 0.9] ⊉ [0.16, 0.88], so this approach would contradict the basic principles of interval arithmetic, as a part of the domain of f([0.1, 0.8], [0.06, 0.08]) would be lost. Instead, the outward-rounded solution [0.1, 0.9] is used.
The standard IEEE 754 for binary floating-point arithmetic also sets out procedures for the implementation of rounding. An IEEE 754 compliant system allows programmers to round to the nearest floating-point number; alternatives are rounding towards zero (truncating), rounding toward positive infinity (rounding up), or rounding towards negative infinity (rounding down).
The required external rounding for interval arithmetic can thus be achieved by changing the rounding settings of the processor in the calculation of the upper limit (up) and lower limit (down). Alternatively, an appropriate small interval [ε1, ε2] can be added.
Interval arithmetic has also been implemented using arbitrary-precision floating-point arithmetic, where the precision is much higher (but still finite, hence still requires rounding). Larger arbitrary-precision numbers are slow to compute and take a significant amount of space to store. A variant of interval arithmetic called ball arithmetic stores a high-precision midpoint and a low-precision radius instead of two high-precision lower and upper bounds as in conventional (infimum–supremum) interval arithmetic,[4] reducing the cost of computation.[5]
Dependency problem
Approximate estimate of the value range
The so-called dependency problem is a major obstacle to the application of interval arithmetic. Although interval methods can determine the range of elementary arithmetic operations and functions very accurately, this is not always true with more complicated functions. If an interval occurs several times in a calculation using parameters, and each occurrence is taken independently, then this can lead to an unwanted expansion of the resulting intervals.
Treating each occurrence of a variable independently
As an illustration, take the function f defined by f(x) = x2 + x. The values of this function over the interval [−1, 1] are [−1/4, 2]. As the natural interval extension, it is calculated as
which is slightly larger; we have instead calculated the infimum and supremum of the function h(x, y) = x2 + y over x, y ∈ [−1, 1]. There is a better expression of f in which the variable x only appears once, namely by rewriting the quadraticf(x) = x2 + x by completing the square:
So the suitable interval calculation is
and gives the correct values.
In general, it can be shown that the exact range of values can be achieved, if each variable appears only once and if f is continuous inside the box. However, not every function can be rewritten this way.
Wrapping effect
The dependency of the problem causing over-estimation of the value range can go as far as covering a large range, preventing more meaningful conclusions.
An additional increase in the range stems from the solution of areas that do not take the form of an interval vector. The solution set of the linear system
is precisely the line between the points (−1, −1) and (1, 1). Using interval methods results in the unit square, [−1, 1] × [−1, 1]. This is known as the wrapping effect.
Linear interval systems
A linear interval system consists of a matrix interval extension [A] ∈ [ℝ]n × m and an interval vector [b] ∈ [ℝ]n. We want the smallest cuboid [x] ∈ [ℝ]m, for all vectors x ∈ ℝm which there is a pair (A, b) with A ∈ [A] and b ∈ [b] that satisfies
.
For quadratic systems (in other words, for n = m) there can be such an interval vector [x], which covers all possible solutions, found simply with the interval Gauss method. This replaces the numerical operations, in that the linear algebra method known as Gaussian elimination becomes its interval version. However, since this method uses the interval entities [A] and [b] repeatedly in the calculation, it can produce poor results for some problems. Hence using the result of the interval-valued Gauss only provides first rough estimates, since although it contains the entire solution set, it also has a large area outside it.
A rough solution [x] can often be improved by an interval version of the Gauss–Seidel method. The motivation for this is that the ith row of the interval extension of the linear equation
can be determined by the variable xi if the division 1/[aii] is allowed. It is therefore simultaneously
So we can now replace [xj] by
and so the vector [x] by each element.
Since the procedure is more efficient for a diagonally dominant matrix, instead of the system [A] · x = [b], one can often try multiplying it by an appropriate rational matrix M with the resulting matrix equation
left to solve. If one chooses, for example, M = A−1 for the central matrix A ∈ [A], then M · [A] is an outer extension of the identity matrix.
These methods only work well if the widths of the intervals occurring are sufficiently small. For wider intervals, it can be useful to use an interval-linear system on finite (albeit large) real number equivalent linear systems. If all the matrices A ∈ [A] are invertible, it is sufficient to consider all possible combinations (upper and lower) of the endpoints occurring in the intervals. The resulting problems can be resolved using conventional numerical methods. Interval arithmetic is still used to determine rounding errors.
This is only suitable for systems of smaller dimension, since with a fully occupied n × n matrix, 2n2 real matrices need to be inverted, with 2n vectors for the right-hand side. This approach was developed by Jiri Rohn and is still being developed.[6]
Interval Newton method
Reduction of the search area in the interval Newton step in "thick" functions.
An interval variant of Newton's method for finding the zeros in an interval vector [x] can be derived from the average value extension.[7] For an unknown vector z ∈ [x] applied to y ∈ [x], gives
For a zero z, that is f(z) = 0, thus must satisfy
This is equivalent to
An outer estimate of [Jf]([x])−1 · f(y) can be determined using linear methods.
In each step of the interval Newton method, an approximate starting value [x] ∈ [ℝ]n is replaced by
and so the result can be improved. In contrast to traditional methods, the interval method approaches the result by containing the zeros. This guarantees that the result produces all zeros in the initial range. Conversely, it proves that no zeros of f were in the initial range [x] if a Newton step produces the empty set.
The method converges on all zeros in the starting region. Division by zero can lead to the separation of distinct zeros, though the separation may not be complete; it can be complemented by the bisection method.
As an example, consider the function f(x) = x2 − 2, the starting range [x] = [−2, 2], and the point y = 0. We then have Jf(x) = 2x and the first Newton step gives
More Newton steps are used separately on x ∈ [−2, −1/2] and x ∈ [1/2, 2]. These converge to arbitrarily small intervals around −√2 and +√2 respectively.
The interval Newton method can also be used with thick functions such as g(x) = x2 − [2, 3], which would in any case have interval results. The result then produces intervals containing [−√3, −√2] ∪ [√2, √3].
Bisection and covers
Rough estimate (turquoise) and improved estimates through "mincing" (red)
The various interval methods deliver conservative results as dependencies between the sizes of different interval extensions are not taken into account. However, the dependency problem becomes less significant for narrower intervals.
Covering an interval vector [x] by smaller boxes [x1], …, [xk], so that
is then valid for the range of values.
So, for the interval extensions described above the following holds:
Since [f]([x]) is often a genuine superset of the right-hand side, this usually leads to an improved estimate.
Such a cover can be generated by the bisection method such as thick elements [xi1, xi2] of the interval vector
by splitting in the center into the two intervals
If the result is still not suitable then further gradual subdivision is possible. A cover of 2r intervals results from r divisions of vector elements, substantially increasing the computation costs.
With very wide intervals, it can be helpful to split all intervals into several subintervals with a constant (and smaller) width, a method known as mincing. This then avoids the calculations for intermediate bisection steps. Both methods are only suitable for problems of low dimension.
Application
Interval arithmetic can be used in various areas (such as set inversion, motion planning, set estimation, or stability analysis) to treat estimates with no exact numerical value.[8]
Rounding error analysis
Interval arithmetic is used with error analysis, to control rounding errors arising from each calculation. The advantage of interval arithmetic is that after each operation there is an interval that reliably includes the true result. The distance between the interval boundaries gives the current calculation of rounding errors directly:
Error = abs(a − b) for a given interval [a, b].
Interval analysis adds to rather than substituting for traditional methods for error reduction, such as pivoting.
Tolerance analysis
Parameters for which no exact figures can be allocated often arise during the simulation of technical and physical processes. The production process of technical components allows certain tolerances, so some parameters fluctuate within intervals. In addition, many fundamental constants are not known precisely.[1]
If the behavior of such a system affected by tolerances satisfies, for example, f(x, p) = 0, for p ∈ [p] and unknown x then the set of possible solutions.
,
can be found by interval methods. This provides an alternative to traditional propagation of error analysis. Unlike point methods, such as Monte Carlo simulation, interval arithmetic methodology ensures that no part of the solution area can be overlooked. However, the result is always a worst-case analysis for the distribution of error, as other probability-based distributions are not considered.
Interval arithmetic can also be used with affiliation functions for fuzzy quantities as they are used in fuzzy logic. Apart from the strict statements x ∈ [x] and x ∉ [x], intermediate values are also possible, to which real numbers μ ∈ [0, 1] are assigned. μ = 1 corresponds to definite membership while μ = 0 is non-membership. A distribution function assigns uncertainty, which can be understood as a further interval.
For fuzzy arithmetic[9] only a finite number of discrete affiliation stages μi ∈ [0, 1] are considered. The form of such a distribution for an indistinct value can then be represented by a sequence of intervals.
The interval [x(i)] corresponds exactly to the fluctuation range for the stage μi.
The appropriate distribution for a function f(x1, …, xn) concerning indistinct values x1, …, xn and the corresponding sequences
can be approximated by the sequence
where
and can be calculated by interval methods. The value [y(1)] corresponds to the result of an interval calculation.
The Fast Library for Number Theory website lists several uses of the FLINT/Arb ball arithmetic library in published papers and preprints.[11]
History
Interval arithmetic is not a completely new phenomenon in mathematics; it has appeared several times under different names in the course of history. For example, Archimedes calculated lower and upper bounds 223/71 < π < 22/7 in the 3rd century BC. Actual calculation with intervals has neither been as popular as other numerical techniques nor been completely forgotten.
Rules for calculating with intervals and other subsets of the real numbers were published in a 1931 work by Rosalind Cicely Young.[12] Arithmetic work on range numbers to improve the reliability of digital systems was then published in a 1951 textbook on linear algebra by Paul S. Dwyer[de];[13] intervals were used to measure rounding errors associated with floating-point numbers. A comprehensive paper on interval algebra in numerical analysis was published by Teruo Sunaga (1958).[14]
The birth of modern interval arithmetic was marked by the appearance of the book Interval Analysis by Ramon E. Moore in 1966.[15][16] He had the idea in spring 1958, and a year later he published an article about computer interval arithmetic.[17] Its merit was that starting with a simple principle, it provided a general method for automated error analysis, not just errors resulting from rounding.
Independently in 1956, Mieczyslaw Warmus suggested formulae for calculations with intervals,[18] though Moore found the first non-trivial applications.
In the following twenty years, German groups of researchers carried out pioneering work around Ulrich W. Kulisch[19][20] and Götz Alefeld[de][21] at the University of Karlsruhe and later also at the Bergische University of Wuppertal. For example, Karl Nickel[de] explored more effective implementations, while improved containment procedures for the solution set of systems of equations were due to Arnold Neumaier among others. In the 1960s, Eldon R. Hansen dealt with interval extensions for linear equations and then provided crucial contributions to global optimization, including what is now known as Hansen's method, perhaps the most widely used interval algorithm.[7] Classical methods in this often have the problem of determining the largest (or smallest) global value, but could only find a local optimum and could not find better values; Helmut Ratschek and Jon George Rokne developed branch and bound methods, which until then had only applied to integer values, by using intervals to provide applications for continuous values.
The journal Reliable Computing (originally Interval Computations) has been published since the 1990s, dedicated to the reliability of computer-aided computations. As lead editor, R. Baker Kearfott, in addition to his work on global optimization, has contributed significantly to the unification of notation and terminology used in interval arithmetic.[23]
In recent years work has concentrated in particular on the estimation of preimages of parameterized functions and to robust control theory by the COPRIN working group of INRIA in Sophia Antipolis in France.[24]
Implementations
There are many software packages that permit the development of numerical applications using interval arithmetic.[25] These are usually provided in the form of program libraries. There are also C++ and Fortran compilers that handle interval data types and suitable operations as a language extension, so interval arithmetic is supported directly.
Since 1967, Extensions for Scientific Computation (XSC) have been developed in the University of Karlsruhe for various programming languages, such as C++, Fortran, and Pascal.[26] The first platform was a ZuseZ23, for which a new interval data type with appropriate elementary operators was made available. There followed in 1976, Pascal-SC, a Pascal variant on a Zilog Z80 that it made possible to create fast, complicated routines for automated result verification. Then came the Fortran 77-based ACRITH-XSC for the System/370 architecture (FORTRAN-SC), which was later delivered by IBM. Starting from 1991 one could produce code for C compilers with Pascal-XSC; a year later the C++ class library supported C-XSC on many different computer systems. In 1997, all XSC variants were made available under the GNU General Public License. At the beginning of 2000, C-XSC 2.0 was released under the leadership of the working group for scientific computation at the Bergische University of Wuppertal to correspond to the improved C++ standard.
Another C++-class library was created in 1993 at the Hamburg University of Technology called Profil/BIAS (Programmer's Runtime Optimized Fast Interval Library, Basic Interval Arithmetic), which made the usual interval operations more user-friendly. It emphasized the efficient use of hardware, portability, and independence of a particular presentation of intervals.
The Boost collection of C++ libraries contains a template class for intervals. Its authors are aiming to have interval arithmetic in the standard C++ language.[27]
The Frink programming language has an implementation of interval arithmetic that handles arbitrary-precision numbers. Programs written in Frink can use intervals without rewriting or recompilation.
GAOL[28] is another C++ interval arithmetic library that is unique in that it offers the relational interval operators used in interval constraint programming.
The Moore library[29] is an efficient implementation of interval arithmetic in C++. It provides intervals with endpoints of arbitrary precision and is based on the concepts feature of C++.
The Julia programming language[30] has an implementation of interval arithmetics along with high-level features, such as root-finding (for both real and complex-valued functions) and interval constraint programming, via the ValidatedNumerics.jl package.[31]
A library for the functional language OCaml was written in assembly language and C.[35]
MPFI is a library for arbitrary precision interval arithmetic; it is written in C and is based on MPFR.[36]
IEEE 1788 standard
A standard for interval arithmetic, IEEE Std 1788-2015, has been approved in June 2015.[37] Two reference implementations are freely available.[38] These have been developed by members of the standard's working group: The libieeep1788[39] library for C++, and the interval package[40] for GNU Octave.
A minimal subset of the standard, IEEE Std 1788.1-2017, has been approved in December 2017 and published in February 2018. It should be easier to implement and may speed production of implementations.[41]
Conferences and workshops
Several international conferences or workshops take place every year in the world. The main conference is probably SCAN (International Symposium on Scientific Computing, Computer Arithmetic, and Verified Numerical Computation), but there is also SWIM (Small Workshop on Interval Methods), PPAM (International Conference on Parallel Processing and Applied Mathematics), REC (International Workshop on Reliable Engineering Computing).
123456Hend Dawood (2011). Theories of Interval Arithmetic: Mathematical Foundations and Applications. Saarbrücken: LAP LAMBERT Academic Publishing. ISBN978-3-8465-0154-2.
↑van der Hoeven, Joris. "Ball arithmetic". www.texmacs.org. We mainly concentrate on the automatic and efficient computation of high quality error bounds, based on a variant of interval arithmetic which we like to call "ball arithmetic".
↑"Feature overview — FLINT 3.5.0-dev documentation". flintlib.org. In traditional (inf–sup) interval arithmetic, both endpoints of an interval [a, b] are full-precision numbers, which makes interval arithmetic twice as expensive as floating-point arithmetic. In ball arithmetic, only the midpoint m of an interval [m ± r] is a full-precision number, and a few bits suffice for the radius r. At high precision, ball arithmetic is therefore not more expensive than plain floating-point arithmetic.
↑Young, Rosalind Cicely (1931). The algebra of many-valued quantities. Mathematische Annalen, 104(1), 260-290. (NB. A doctoral candidate at the University of Cambridge.)
↑Nathalie Revol (2015). The (near-)future IEEE 1788 standard for interval arithmetic, slides // SWIM 2015: 8th Small Workshop in Interval Methods. Prague, 9–11 June 2015
Wippermann, Hans-Wilm (1968) [1967-06-15, 1966]. "Definition von Schrankenzahlen in Triplex-ALGOL". Computing (in German). 3 (2). Karlsruhe, Germany: Springer: 99–109. doi:10.1007/BF02277452. ISSN0010-485X. S2CID36685400. (11 pages) (NB. About Triplex-ALGOL Karlsruhe, an ALGOL 60 (1963) implementation with support for triplex numbers.)
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.