In connection-oriented communication, a data stream is the transmission of a sequence of digitally encoded signals to convey information. Typically, the transmitted symbols are grouped into a series of packets.
Machine learning (ML) is a field of study in artificial intelligence concerned with the development and study of statistical algorithms that can learn from data and generalize to unseen data, and thus perform tasks without explicit instructions. Advances in the field of deep learning have allowed neural networks to surpass many previous approaches in performance.
Information privacy is the relationship between the collection and dissemination of data, technology, the public expectation of privacy, contextual information norms, and the legal and political issues surrounding them. It is also known as data privacy or data protection.
A recommender system (RecSys), or a recommendation system (sometimes replacing system with terms such as platform, engine, or algorithm), is a subclass of information filtering system that provides suggestions for items that are most pertinent to a particular user. Recommender systems are particularly useful when an individual needs to choose an item from a potentially overwhelming number of items that a service may offer.
Internet security is a branch of computer security. It encompasses the Internet, browser security, web site security, and network security as it applies to other applications or operating systems as a whole. Its objective is to establish rules and measures to use against attacks over the Internet. The Internet is an inherently insecure channel for information exchange, with high risk of intrusion or fraud, such as phishing, online viruses, trojans, ransomware and worms.
Internet privacy involves the right or mandate of personal privacy concerning the storage, re-purposing, provision to third parties, and display of information pertaining to oneself via the Internet. Internet privacy is a subset of data privacy. Privacy concerns have been articulated from the beginnings of large-scale computer sharing and especially relate to mass surveillance.
Health technology is defined by the World Health Organization as the "application of organized knowledge and skills in the form of devices, medicines, vaccines, procedures, and systems developed to solve a health problem and improve quality of lives". This includes pharmaceuticals, devices, procedures, and organizational systems used in the healthcare industry, as well as computer-supported information systems. In the United States, these technologies involve standardized physical objects, as well as traditional and designed social means and methods to treat or care for patients.
A click path or clickstream is the sequence of hyperlinks one or more website visitors follows on a given site, presented in the order viewed. A visitor's click path may start within the website or at a separate third party website, often a search engine results page, and it continues as a sequence of successive webpages visited by the user. Click paths take call data and can match it to ad sources, keywords, and/or referring domains, in order to capture data.

Digital footprint or digital shadow refers to one's unique set of traceable digital activities, actions, contributions, and communications manifested on the Internet or digital devices. Digital footprints can be classified as either passive or active. The former is composed of a user's web-browsing activity and information stored as cookies. The latter is often released deliberately by a user to share information on websites or social media. While the term usually applies to a person, a digital footprint can also refer to a business, organization or corporation.
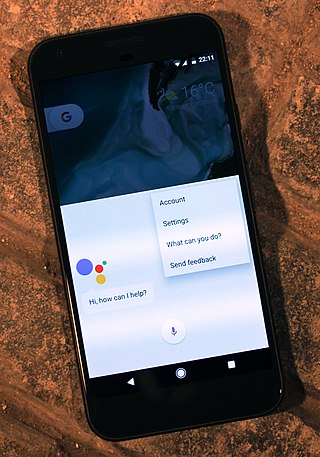
A virtual assistant (VA) is a software agent that can perform a range of tasks or services for a user based on user input such as commands or questions, including verbal ones. Such technologies often incorporate chatbot capabilities to simulate human conversation, such as via online chat, to facilitate interaction with their users. The interaction may be via text, graphical interface, or voice - as some virtual assistants are able to interpret human speech and respond via synthesized voices.
The social data revolution is the shift in human communication patterns towards increased personal information sharing and its related implications, made possible by the rise of social networks in the early 2000s. This phenomenon has resulted in the accumulation of unprecedented amounts of public data.

Dataveillance is the practice of monitoring and collecting online data as well as metadata. The word is a portmanteau of data and surveillance. Dataveillance is concerned with the continuous monitoring of users' communications and actions across various platforms. For instance, dataveillance refers to the monitoring of data resulting from credit card transactions, GPS coordinates, emails, social networks, etc. Using digital media often leaves traces of data and creates a digital footprint of our activity. Unlike sousveillance, this type of surveillance is not often known and happens discreetly. Dataveillance may involve the surveillance of groups of individuals. There exist three types of dataveillance: personal dataveillance, mass dataveillance, and facilitative mechanisms.
Crowdsensing, sometimes referred to as mobile crowdsensing, is a technique where a large group of individuals having mobile devices capable of sensing and computing collectively share data and extract information to measure, map, analyze, estimate or infer (predict) any processes of common interest. In short, this means crowdsourcing of sensor data from mobile devices.

Artificial intelligence in healthcare is the application of artificial intelligence (AI) to analyze and understand complex medical and healthcare data. In some cases, it can exceed or augment human capabilities by providing better or faster ways to diagnose, treat, or prevent disease.
The industrial internet of things (IIoT) refers to interconnected sensors, instruments, and other devices networked together with computers' industrial applications, including manufacturing and energy management. This connectivity allows for data collection, exchange, and analysis, potentially facilitating improvements in productivity and efficiency as well as other economic benefits. The IIoT is an evolution of a distributed control system (DCS) that allows for a higher degree of automation by using cloud computing to refine and optimize the process controls.
Big data ethics, also known simply as data ethics, refers to systemizing, defending, and recommending concepts of right and wrong conduct in relation to data, in particular personal data. Since the dawn of the Internet the sheer quantity and quality of data has dramatically increased and is continuing to do so exponentially. Big data describes this large amount of data that is so voluminous and complex that traditional data processing application software is inadequate to deal with them. Recent innovations in medical research and healthcare, such as high-throughput genome sequencing, high-resolution imaging, electronic medical patient records and a plethora of internet-connected health devices have triggered a data deluge that will reach the exabyte range in the near future. Data ethics is of increasing relevance as the quantity of data increases because of the scale of the impact.
Click tracking is when user click behavior or user navigational behavior is collected in order to derive insights and fingerprint users. Click behavior is commonly tracked using server logs which encompass click paths and clicked URLs. This log is often presented in a standard format including information like the hostname, date, and username. However, as technology develops, new software allows for in depth analysis of user click behavior using hypervideo tools. Given that the internet can be considered a risky environment, research strives to understand why users click certain links and not others. Research has also been conducted to explore the user experience of privacy with making user personal identification information individually anonymized and improving how data collection consent forms are written and structured.

The impact of artificial intelligence on workers includes both applications to improve worker safety and health, and potential hazards that must be controlled.
Soft privacy technologies fall under the category of PETs, Privacy-enhancing technologies, as methods of protecting data. Soft privacy is a counterpart to another subcategory of PETs, called hard privacy. Soft privacy technology has the goal of keeping information safe, allowing services to process data while having full control of how data is being used. To accomplish this, soft privacy emphasizes the use of third-party programs to protect privacy, emphasizing auditing, certification, consent, access control, encryption, and differential privacy. Since evolving technologies like the internet, machine learning, and big data are being applied to many long-standing fields, we now need to process billions of datapoints every day in areas such as health care, autonomous cars, smart cards, social media, and more. Many of these fields rely on soft privacy technologies when they handle data.
Automated decision-making (ADM) involves the use of data, machines and algorithms to make decisions in a range of contexts, including public administration, business, health, education, law, employment, transport, media and entertainment, with varying degrees of human oversight or intervention. ADM involves large-scale data from a range of sources, such as databases, text, social media, sensors, images or speech, that is processed using various technologies including computer software, algorithms, machine learning, natural language processing, artificial intelligence, augmented intelligence and robotics. The increasing use of automated decision-making systems (ADMS) across a range of contexts presents many benefits and challenges to human society requiring consideration of the technical, legal, ethical, societal, educational, economic and health consequences.