In computer science, a consistency model specifies a contract between the programmer and a system, wherein the system guarantees that if the programmer follows the rules for operations on memory, memory will be consistent and the results of reading, writing, or updating memory will be predictable. Consistency models are used in distributed systems like distributed shared memory systems or distributed data stores. Consistency is different from coherence, which occurs in systems that are cached or cache-less, and is consistency of data with respect to all processors. Coherence deals with maintaining a global order in which writes to a single location or single variable are seen by all processors. Consistency deals with the ordering of operations to multiple locations with respect to all processors.
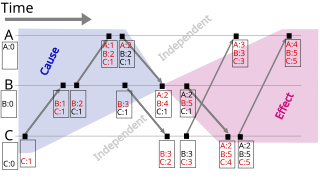
A vector clock is a data structure used for determining the partial ordering of events in a distributed system and detecting causality violations. Just as in Lamport timestamps, inter-process messages contain the state of the sending process's logical clock. A vector clock of a system of N processes is an array/vector of N logical clocks, one clock per process; a local "largest possible values" copy of the global clock-array is kept in each process.
Google File System is a proprietary distributed file system developed by Google to provide efficient, reliable access to data using large clusters of commodity hardware. Google file system was replaced by Colossus in 2010.
File synchronization in computing is the process of ensuring that computer files in two or more locations are updated via certain rules.
Eventual consistency is a consistency model used in distributed computing to achieve high availability that informally guarantees that, if no new updates are made to a given data item, eventually all accesses to that item will return the last updated value. Eventual consistency, also called optimistic replication, is widely deployed in distributed systems and has origins in early mobile computing projects. A system that has achieved eventual consistency is often said to have converged, or achieved replica convergence. Eventual consistency is a weak guarantee – most stronger models, like linearizability, are trivially eventually consistent.
The Lamport timestamp algorithm is a simple logical clock algorithm used to determine the order of events in a distributed computer system. As different nodes or processes will typically not be perfectly synchronized, this algorithm is used to provide a partial ordering of events with minimal overhead, and conceptually provide a starting point for the more advanced vector clock method. The algorithm is named after its creator, Leslie Lamport.
Replication in computing involves sharing information so as to ensure consistency between redundant resources, such as software or hardware components, to improve reliability, fault-tolerance, or accessibility.
GPFS is high-performance clustered file system software developed by IBM. It can be deployed in shared-disk or shared-nothing distributed parallel modes, or a combination of these. It is used by many of the world's largest commercial companies, as well as some of the supercomputers on the Top 500 List. For example, it is the filesystem of the Summit at Oak Ridge National Laboratory which was the #1 fastest supercomputer in the world in the November 2019 TOP500 list of supercomputers. Summit is a 200 Petaflops system composed of more than 9,000 POWER9 processors and 27,000 NVIDIA Volta GPUs. The storage filesystem called Alpine has 250 PB of storage using Spectrum Scale on IBM ESS storage hardware, capable of approximately 2.5TB/s of sequential I/O and 2.2TB/s of random I/O.

DRBD is a distributed replicated storage system for the Linux platform. It is implemented as a kernel driver, several userspace management applications, and some shell scripts. DRBD is traditionally used in high availability (HA) computer clusters, but beginning with DRBD version 9, it can also be used to create larger software defined storage pools with a focus on cloud integration.
Gluster Inc. was a software company that provided an open source platform for scale-out public and private cloud storage. The company was privately funded and headquartered in Sunnyvale, California, with an engineering center in Bangalore, India. Gluster was funded by Nexus Venture Partners and Index Ventures. Gluster was acquired by Red Hat on October 7, 2011.
A grid file system is a computer file system whose goal is improved reliability and availability by taking advantage of many smaller file storage areas.
A clustered file system (CFS) is a file system which is shared by being simultaneously mounted on multiple servers. There are several approaches to clustering, most of which do not employ a clustered file system. Clustered file systems can provide features like location-independent addressing and redundancy which improve reliability or reduce the complexity of the other parts of the cluster. Parallel file systems are a type of clustered file system that spread data across multiple storage nodes, usually for redundancy or performance.
Microsoft Sync Framework is a data synchronization platform from Microsoft that can be used to synchronize data across multiple data stores. Sync Framework includes a transport-agnostic architecture, into which data store-specific synchronization providers, modelled on the ADO.NET data provider API, can be plugged in. Sync Framework can be used for offline access to data, by working against a cached set of data and submitting the changes to a master database in a batch, as well as to synchronize changes to a data source across all consumers and peer-to-peer synchronization of multiple data sources. Sync Framework features built-in capabilities for conflict detection – whether data to be changed has already been updated – and can flag them for manual inspection or use defined policies to try to resolve the conflict. Sync Services includes an embedded SQL Server Compact database to store metadata about the synchronization relationships as well as about each sync attempt. The Sync Framework API is surfaced both in managed code, for use with .NET Framework applications, as well as unmanaged code, for use with COM applications. It was scheduled to ship with Visual Studio 2008 in late November 2007.
Optimistic replication, also known as lazy replication, is a strategy for replication, in which replicas are allowed to diverge.
LOCUS is a discontinued distributed operating system developed at UCLA during the 1980s. It was notable for providing an early implementation of the single-system image idea, where a cluster of machines appeared to be one larger machine.

Reo is a domain-specific language for programming and analyzing coordination protocols that compose individual processes into full systems, broadly construed. Examples of classes of systems that can be composed with Reo include component-based systems, service-oriented systems, multithreading systems, biological systems, and cryptographic protocols. Reo has a graphical syntax in which every Reo program, called a connector or circuit, is a labeled directed hypergraph. Such a graph represents the data-flow among the processes in the system. Reo has formal semantics, which stand at the basis of its various formal verification techniques and compilation tools.
A version vector is a mechanism for tracking changes to data in a distributed system, where multiple agents might update the data at different times. The version vector allows the participants to determine if one update preceded another (happened-before), followed it, or if the two updates happened concurrently. In this way, version vectors enable causality tracking among data replicas and are a basic mechanism for optimistic replication. In mathematical terms, the version vector generates a preorder that tracks the events that precede, and may therefore influence, later updates.
Industrial process data validation and reconciliation, or more briefly, process data reconciliation (PDR), is a technology that uses process information and mathematical methods in order to automatically ensure data validation and reconciliation by correcting measurements in industrial processes. The use of PDR allows for extracting accurate and reliable information about the state of industry processes from raw measurement data and produces a single consistent set of data representing the most likely process operation.
A distributed file system for cloud is a file system that allows many clients to have access to data and supports operations on that data. Each data file may be partitioned into several parts called chunks. Each chunk may be stored on different remote machines, facilitating the parallel execution of applications. Typically, data is stored in files in a hierarchical tree, where the nodes represent directories. There are several ways to share files in a distributed architecture: each solution must be suitable for a certain type of application, depending on how complex the application is. Meanwhile, the security of the system must be ensured. Confidentiality, availability and integrity are the main keys for a secure system.