In graph theory, an expander graph is a sparse graph that has strong connectivity properties, quantified using vertex, edge or spectral expansion. Expander constructions have spawned research in pure and applied mathematics, with several applications to complexity theory, design of robust computer networks, and the theory of error-correcting codes.

A Markov chain or Markov process is a stochastic model describing a sequence of possible events in which the probability of each event depends only on the state attained in the previous event. Informally, this may be thought of as, "What happens next depends only on the state of affairs now." A countably infinite sequence, in which the chain moves state at discrete time steps, gives a discrete-time Markov chain (DTMC). A continuous-time process is called a continuous-time Markov chain (CTMC). It is named after the Russian mathematician Andrey Markov.
In mathematics, spectral graph theory is the study of the properties of a graph in relationship to the characteristic polynomial, eigenvalues, and eigenvectors of matrices associated with the graph, such as its adjacency matrix or Laplacian matrix.
A continuous-time Markov chain (CTMC) is a continuous stochastic process in which, for each state, the process will change state according to an exponential random variable and then move to a different state as specified by the probabilities of a stochastic matrix. An equivalent formulation describes the process as changing state according to the least value of a set of exponential random variables, one for each possible state it can move to, with the parameters determined by the current state.
In mathematics, the Gauss–Kuzmin–Wirsing operator is the transfer operator of the Gauss map that takes a positive number to the fractional part of its reciprocal. It is named after Carl Gauss, Rodion Kuzmin, and Eduard Wirsing. It occurs in the study of continued fractions; it is also related to the Riemann zeta function.
In functional analysis, a branch of mathematics, it is sometimes possible to generalize the notion of the determinant of a square matrix of finite order (representing a linear transformation from a finite-dimensional vector space to itself) to the infinite-dimensional case of a linear operator S mapping a function space V to itself. The corresponding quantity det(S) is called the functional determinant of S.

In the mathematical study of heat conduction and diffusion, a heat kernel is the fundamental solution to the heat equation on a specified domain with appropriate boundary conditions. It is also one of the main tools in the study of the spectrum of the Laplace operator, and is thus of some auxiliary importance throughout mathematical physics. The heat kernel represents the evolution of temperature in a region whose boundary is held fixed at a particular temperature, such that an initial unit of heat energy is placed at a point at time t = 0.
In graph theory, a graph is said to be a pseudorandom graph if it obeys certain properties that random graphs obey with high probability. There is no concrete definition of graph pseudorandomness, but there are many reasonable characterizations of pseudorandomness one can consider.
The expander mixing lemma intuitively states that the edges of certain -regular graphs are evenly distributed throughout the graph. In particular, the number of edges between two vertex subsets and is always close to the expected number of edges between them in a random -regular graph, namely .
In the mathematical discipline of graph theory, the expander walk sampling theorem intuitively states that sampling vertices in an expander graph by doing relatively short random walk can simulate sampling the vertices independently from a uniform distribution. The earliest version of this theorem is due to Ajtai, Komlós & Szemerédi (1987), and the more general version is typically attributed to Gillman (1998).
In mathematics, Reidemeister torsion is a topological invariant of manifolds introduced by Kurt Reidemeister for 3-manifolds and generalized to higher dimensions by Wolfgang Franz and Georges de Rham . Analytic torsion is an invariant of Riemannian manifolds defined by Daniel B. Ray and Isadore M. Singer as an analytic analogue of Reidemeister torsion. Jeff Cheeger and Werner Müller proved Ray and Singer's conjecture that Reidemeister torsion and analytic torsion are the same for compact Riemannian manifolds.

In theoretical computer science, graph theory, and mathematics, the conductance is a parameter of a Markov chain that is closely tied to its mixing time, that is, how rapidly the chain converges to its stationary distribution, should it exist. Equivalently, the conductance can be viewed as a parameter of a directed graph, in which case it can be used to analyze how quickly random walks in the graph converge.
In Riemannian geometry, the Cheeger isoperimetric constant of a compact Riemannian manifold M is a positive real number h(M) defined in terms of the minimal area of a hypersurface that divides M into two disjoint pieces. In 1971, Jeff Cheeger proved an inequality that related the first nontrivial eigenvalue of the Laplace–Beltrami operator on M to h(M). In 1982, Peter Buser proved a reverse version of this inequality, and the two inequalities put together are sometimes called the Cheeger-Buser inequality. These inequalities were highly influential not only in Riemannian geometry and global analysis, but also in the theory of Markov chains and in graph theory, where they have inspired the analogous Cheeger constant of a graph and the notion of conductance.
In mathematics, the spectral theory of ordinary differential equations is the part of spectral theory concerned with the determination of the spectrum and eigenfunction expansion associated with a linear ordinary differential equation. In his dissertation, Hermann Weyl generalized the classical Sturm–Liouville theory on a finite closed interval to second order differential operators with singularities at the endpoints of the interval, possibly semi-infinite or infinite. Unlike the classical case, the spectrum may no longer consist of just a countable set of eigenvalues, but may also contain a continuous part. In this case the eigenfunction expansion involves an integral over the continuous part with respect to a spectral measure, given by the Titchmarsh–Kodaira formula. The theory was put in its final simplified form for singular differential equations of even degree by Kodaira and others, using von Neumann's spectral theorem. It has had important applications in quantum mechanics, operator theory and harmonic analysis on semisimple Lie groups.
In mathematics, particularly linear algebra, the Schur–Horn theorem, named after Issai Schur and Alfred Horn, characterizes the diagonal of a Hermitian matrix with given eigenvalues. It has inspired investigations and substantial generalizations in the setting of symplectic geometry. A few important generalizations are Kostant's convexity theorem, Atiyah–Guillemin–Sternberg convexity theorem, Kirwan convexity theorem.
In quantum mechanics, and especially quantum information and the study of open quantum systems, the trace distanceT is a metric on the space of density matrices and gives a measure of the distinguishability between two states. It is the quantum generalization of the Kolmogorov distance for classical probability distributions.
In probability theory, concentration inequalities provide mathematical bounds on the probability of a random variable deviating from some value.
In mathematics, singular integral operators of convolution type are the singular integral operators that arise on Rn and Tn through convolution by distributions; equivalently they are the singular integral operators that commute with translations. The classical examples in harmonic analysis are the harmonic conjugation operator on the circle, the Hilbert transform on the circle and the real line, the Beurling transform in the complex plane and the Riesz transforms in Euclidean space. The continuity of these operators on L2 is evident because the Fourier transform converts them into multiplication operators. Continuity on Lp spaces was first established by Marcel Riesz. The classical techniques include the use of Poisson integrals, interpolation theory and the Hardy–Littlewood maximal function. For more general operators, fundamental new techniques, introduced by Alberto Calderón and Antoni Zygmund in 1952, were developed by a number of authors to give general criteria for continuity on Lp spaces. This article explains the theory for the classical operators and sketches the subsequent general theory.
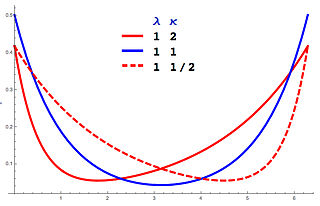
In probability theory and directional statistics, a wrapped asymmetric Laplace distribution is a wrapped probability distribution that results from the "wrapping" of the asymmetric Laplace distribution around the unit circle. For the symmetric case (asymmetry parameter κ = 1), the distribution becomes a wrapped Laplace distribution. The distribution of the ratio of two circular variates (Z) from two different wrapped exponential distributions will have a wrapped asymmetric Laplace distribution. These distributions find application in stochastic modelling of financial data.
Batch normalization is a method used to make training of artificial neural networks faster and more stable through normalization of the layers' inputs by re-centering and re-scaling. It was proposed by Sergey Ioffe and Christian Szegedy in 2015.















