In computational complexity theory, a branch of computer science, bounded-error probabilistic polynomial time (BPP) is the class of decision problems solvable by a probabilistic Turing machine in polynomial time with an error probability bounded by 1/3 for all instances. BPP is one of the largest practical classes of problems, meaning most problems of interest in BPP have efficient probabilistic algorithms that can be run quickly on real modern machines. BPP also contains P, the class of problems solvable in polynomial time with a deterministic machine, since a deterministic machine is a special case of a probabilistic machine.
In theoretical computer science and mathematics, computational complexity theory focuses on classifying computational problems according to their resource usage, and relating these classes to each other. A computational problem is a task solved by a computer. A computation problem is solvable by mechanical application of mathematical steps, such as an algorithm.

In computational complexity theory, NP is a complexity class used to classify decision problems. NP is the set of decision problems for which the problem instances, where the answer is "yes", have proofs verifiable in polynomial time by a deterministic Turing machine, or alternatively the set of problems that can be solved in polynomial time by a nondeterministic Turing machine.

In theoretical computer science and mathematics, the theory of computation is the branch that deals with what problems can be solved on a model of computation, using an algorithm, how efficiently they can be solved or to what degree. The field is divided into three major branches: automata theory and formal languages, computability theory, and computational complexity theory, which are linked by the question: "What are the fundamental capabilities and limitations of computers?".

In computational complexity theory, a complexity class is a set of computational problems "of related resource-based complexity". The two most commonly analyzed resources are time and memory.
In computer science, parameterized complexity is a branch of computational complexity theory that focuses on classifying computational problems according to their inherent difficulty with respect to multiple parameters of the input or output. The complexity of a problem is then measured as a function of those parameters. This allows the classification of NP-hard problems on a finer scale than in the classical setting, where the complexity of a problem is only measured as a function of the number of bits in the input. This appears to have been first demonstrated in Gurevich, Stockmeyer & Vishkin (1984). The first systematic work on parameterized complexity was done by Downey & Fellows (1999).
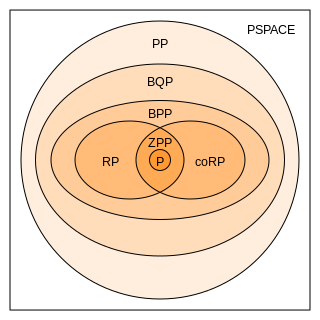
In complexity theory, PP is the class of decision problems solvable by a probabilistic Turing machine in polynomial time, with an error probability of less than 1/2 for all instances. The abbreviation PP refers to probabilistic polynomial time. The complexity class was defined by Gill in 1977.
In the mathematics of computational complexity theory, computability theory, and decision theory, a search problem is a type of computational problem represented by a binary relation. Intuitively, the problem consists in finding structure "y" in object "x". An algorithm is said to solve the problem if at least one corresponding structure exists, and then one occurrence of this structure is made output; otherwise, the algorithm stops with an appropriate output.
In computational complexity theory, the Immerman–Szelepcsényi theorem states that nondeterministic space complexity classes are closed under complementation. It was proven independently by Neil Immerman and Róbert Szelepcsényi in 1987, for which they shared the 1995 Gödel Prize. In its general form the theorem states that NSPACE(s(n)) = co-NSPACE(s(n)) for any function s(n) ≥ log n. The result is equivalently stated as NL = co-NL; although this is the special case when s(n) = log n, it implies the general theorem by a standard padding argument. The result solved the second LBA problem.
In theoretical computer science, a computational problem is a problem that may be solved by an algorithm. For example, the problem of factoring
In computational complexity theory, a computational resource is a resource used by some computational models in the solution of computational problems.
In theoretical computer science, a pointer machine is an atomistic abstract computational machine whose storage structure is a graph. A pointer algorithm could also be an algorithm restricted to the pointer machine model.
In computer science, graph traversal refers to the process of visiting each vertex in a graph. Such traversals are classified by the order in which the vertices are visited. Tree traversal is a special case of graph traversal.
A Turing machine is a hypothetical computing device, first conceived by Alan Turing in 1936. Turing machines manipulate symbols on a potentially infinite strip of tape according to a finite table of rules, and they provide the theoretical underpinnings for the notion of a computer algorithm.

In computational complexity theory and circuit complexity, a Boolean circuit is a mathematical model for combinational digital logic circuits. A formal language can be decided by a family of Boolean circuits, one circuit for each possible input length.
In theoretical computer science, circuit complexity is a branch of computational complexity theory in which Boolean functions are classified according to the size or depth of the Boolean circuits that compute them. A related notion is the circuit complexity of a recursive language that is decided by a uniform family of circuits .
In computational complexity theory, a certificate is a string that certifies the answer to a computation, or certifies the membership of some string in a language. A certificate is often thought of as a solution path within a verification process, which is used to check whether a problem gives the answer "Yes" or "No".
In computational complexity theory, arithmetic circuits are the standard model for computing polynomials. Informally, an arithmetic circuit takes as inputs either variables or numbers, and is allowed to either add or multiply two expressions it has already computed. Arithmetic circuits provide a formal way to understand the complexity of computing polynomials. The basic type of question in this line of research is "what is the most efficient way to compute a given polynomial ?"
In computational complexity the decision tree model is the model of computation in which an algorithm is considered to be basically a decision tree, i.e., a sequence of queries or tests that are done adaptively, so the outcome of previous tests can influence the tests performed next.
Quantum complexity theory is the subfield of computational complexity theory that deals with complexity classes defined using quantum computers, a computational model based on quantum mechanics. It studies the hardness of computational problems in relation to these complexity classes, as well as the relationship between quantum complexity classes and classical complexity classes.
