
Linear programming (LP), also called linear optimization, is a method to achieve the best outcome in a mathematical model whose requirements are represented by linear relationships. Linear programming is a special case of mathematical programming.
Mathematical optimization or mathematical programming is the selection of a best element, with regard to some criterion, from some set of available alternatives. It is generally divided into two subfields: discrete optimization and continuous optimization. Optimization problems arise in all quantitative disciplines from computer science and engineering to operations research and economics, and the development of solution methods has been of interest in mathematics for centuries.
In the field of machine learning, the goal of statistical classification is to use an object's characteristics to identify which class it belongs to. A linear classifier achieves this by making a classification decision based on the value of a linear combination of the characteristics. An object's characteristics are also known as feature values and are typically presented to the machine in a vector called a feature vector. Such classifiers work well for practical problems such as document classification, and more generally for problems with many variables (features), reaching accuracy levels comparable to non-linear classifiers while taking less time to train and use. 5-12-23
A Bayesian network is a probabilistic graphical model that represents a set of variables and their conditional dependencies via a directed acyclic graph (DAG). While it is one of several forms of causal notation, causal networks are special cases of Bayesian networks. Bayesian networks are ideal for taking an event that occurred and predicting the likelihood that any one of several possible known causes was the contributing factor. For example, a Bayesian network could represent the probabilistic relationships between diseases and symptoms. Given symptoms, the network can be used to compute the probabilities of the presence of various diseases.
An integer programming problem is a mathematical optimization or feasibility program in which some or all of the variables are restricted to be integers. In many settings the term refers to integer linear programming (ILP), in which the objective function and the constraints are linear.
In the domain of physics and probability, a Markov random field (MRF), Markov network or undirected graphical model is a set of random variables having a Markov property described by an undirected graph. In other words, a random field is said to be a Markov random field if it satisfies Markov properties. The concept originates from the Sherrington–Kirkpatrick model.

Conditional random fields (CRFs) are a class of statistical modeling methods often applied in pattern recognition and machine learning and used for structured prediction. Whereas a classifier predicts a label for a single sample without considering "neighbouring" samples, a CRF can take context into account. To do so, the predictions are modelled as a graphical model, which represents the presence of dependencies between the predictions. What kind of graph is used depends on the application. For example, in natural language processing, "linear chain" CRFs are popular, for which each prediction is dependent only on its immediate neighbours. In image processing, the graph typically connects locations to nearby and/or similar locations to enforce that they receive similar predictions.
In mathematical optimization, constrained optimization is the process of optimizing an objective function with respect to some variables in the presence of constraints on those variables. The objective function is either a cost function or energy function, which is to be minimized, or a reward function or utility function, which is to be maximized. Constraints can be either hard constraints, which set conditions for the variables that are required to be satisfied, or soft constraints, which have some variable values that are penalized in the objective function if, and based on the extent that, the conditions on the variables are not satisfied.
In computer science and mathematical logic, satisfiability modulo theories (SMT) is the problem of determining whether a mathematical formula is satisfiable. It generalizes the Boolean satisfiability problem (SAT) to more complex formulas involving real numbers, integers, and/or various data structures such as lists, arrays, bit vectors, and strings. The name is derived from the fact that these expressions are interpreted within ("modulo") a certain formal theory in first-order logic with equality. SMT solvers are tools that aim to solve the SMT problem for a practical subset of inputs. SMT solvers such as Z3 and cvc5 have been used as a building block for a wide range of applications across computer science, including in automated theorem proving, program analysis, program verification, and software testing.
Limited-memory BFGS is an optimization algorithm in the family of quasi-Newton methods that approximates the Broyden–Fletcher–Goldfarb–Shanno algorithm (BFGS) using a limited amount of computer memory. It is a popular algorithm for parameter estimation in machine learning. The algorithm's target problem is to minimize over unconstrained values of the real-vector where is a differentiable scalar function.
In mathematics, a constraint is a condition of an optimization problem that the solution must satisfy. There are several types of constraints—primarily equality constraints, inequality constraints, and integer constraints. The set of candidate solutions that satisfy all constraints is called the feasible set.

Computational Infrastructure for Operations Research (COIN-OR), is a project that aims to "create for mathematical software what the open literature is for mathematical theory." The open literature provides the operations research (OR) community with a peer-review process and an archive. Papers in operations research journals on mathematical theory often contain supporting numerical results from computational studies. The software implementations, models, and data used to produce the numerical results are typically not published. The status quo impeded researchers needing to reproduce computational results, make fair comparisons, and extend the state of the art.
Discriminative models, also referred to as conditional models, are a class of logistical models used for classification or regression. They distinguish decision boundaries through observed data, such as pass/fail, win/lose, alive/dead or healthy/sick.
The structured support-vector machine is a machine learning algorithm that generalizes the Support-Vector Machine (SVM) classifier. Whereas the SVM classifier supports binary classification, multiclass classification and regression, the structured SVM allows training of a classifier for general structured output labels.
Structured prediction or structured (output) learning is an umbrella term for supervised machine learning techniques that involves predicting structured objects, rather than scalar discrete or real values.
Augmented Lagrangian methods are a certain class of algorithms for solving constrained optimization problems. They have similarities to penalty methods in that they replace a constrained optimization problem by a series of unconstrained problems and add a penalty term to the objective, but the augmented Lagrangian method adds yet another term designed to mimic a Lagrange multiplier. The augmented Lagrangian is related to, but not identical with, the method of Lagrange multipliers.
In constrained least squares one solves a linear least squares problem with an additional constraint on the solution. This means, the unconstrained equation must be fit as closely as possible while ensuring that some other property of is maintained.

Dan Roth is the Eduardo D. Glandt Distinguished Professor of Computer and Information Science at the University of Pennsylvania.
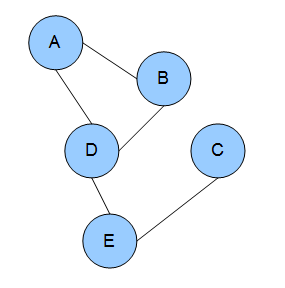
Dependency networks (DNs) are graphical models, similar to Markov networks, wherein each vertex (node) corresponds to a random variable and each edge captures dependencies among variables. Unlike Bayesian networks, DNs may contain cycles. Each node is associated to a conditional probability table, which determines the realization of the random variable given its parents.







