Related Research Articles

In machine learning, a neural network is a model inspired by the structure and function of biological neural networks in animal brains.
Pattern recognition is the task of assigning a class to an observation based on patterns extracted from data. While similar, pattern recognition (PR) is not to be confused with pattern machines (PM) which may possess (PR) capabilities but their primary function is to distinguish and create emergent patterns. PR has applications in statistical data analysis, signal processing, image analysis, information retrieval, bioinformatics, data compression, computer graphics and machine learning. Pattern recognition has its origins in statistics and engineering; some modern approaches to pattern recognition include the use of machine learning, due to the increased availability of big data and a new abundance of processing power.
Machine learning (ML) is a field of study in artificial intelligence concerned with the development and study of statistical algorithms that can learn from data and generalize to unseen data and thus perform tasks without explicit instructions. Recently, artificial neural networks have been able to surpass many previous approaches in performance.

In artificial intelligence, symbolic artificial intelligence is the term for the collection of all methods in artificial intelligence research that are based on high-level symbolic (human-readable) representations of problems, logic and search. Symbolic AI used tools such as logic programming, production rules, semantic nets and frames, and it developed applications such as knowledge-based systems, symbolic mathematics, automated theorem provers, ontologies, the semantic web, and automated planning and scheduling systems. The Symbolic AI paradigm led to seminal ideas in search, symbolic programming languages, agents, multi-agent systems, the semantic web, and the strengths and limitations of formal knowledge and reasoning systems.
Intelligent control is a class of control techniques that use various artificial intelligence computing approaches like neural networks, Bayesian probability, fuzzy logic, machine learning, reinforcement learning, evolutionary computation and genetic algorithms.
The expression computational intelligence (CI) usually refers to the ability of a computer to learn a specific task from data or experimental observation. Even though it is commonly considered a synonym of soft computing, there is still no commonly accepted definition of computational intelligence.
When classification is performed by a computer, statistical methods are normally used to develop the algorithm.
Vasant G. Honavar is an Indian-American computer scientist, and artificial intelligence, machine learning, big data, data science, causal inference, knowledge representation, bioinformatics and health informatics researcher and professor.
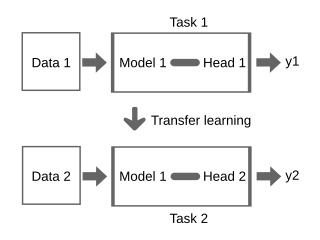
Transfer learning (TL) is a technique in machine learning (ML) in which knowledge learned from a task is re-used in order to boost performance on a related task. For example, for image classification, knowledge gained while learning to recognize cars could be applied when trying to recognize trucks. This topic is related to the psychological literature on transfer of learning, although practical ties between the two fields are limited. Reusing/transferring information from previously learned tasks to new tasks has the potential to significantly improve learning efficiency.
Statistical relational learning (SRL) is a subdiscipline of artificial intelligence and machine learning that is concerned with domain models that exhibit both uncertainty and complex, relational structure. Typically, the knowledge representation formalisms developed in SRL use first-order logic to describe relational properties of a domain in a general manner and draw upon probabilistic graphical models to model the uncertainty; some also build upon the methods of inductive logic programming. Significant contributions to the field have been made since the late 1990s.
In statistics and machine learning, ensemble methods use multiple learning algorithms to obtain better predictive performance than could be obtained from any of the constituent learning algorithms alone. Unlike a statistical ensemble in statistical mechanics, which is usually infinite, a machine learning ensemble consists of only a concrete finite set of alternative models, but typically allows for much more flexible structure to exist among those alternatives.
Fraud represents a significant problem for governments and businesses and specialized analysis techniques for discovering fraud using them are required. Some of these methods include knowledge discovery in databases (KDD), data mining, machine learning and statistics. They offer applicable and successful solutions in different areas of electronic fraud crimes.
There are many types of artificial neural networks (ANN).
In computer science, an evolving intelligent system is a fuzzy logic system which improves the own performance by evolving rules. The technique is known from machine learning, in which external patterns are learned by an algorithm. Fuzzy logic based machine learning works with neuro-fuzzy systems.
This glossary of artificial intelligence is a list of definitions of terms and concepts relevant to the study of artificial intelligence, its sub-disciplines, and related fields. Related glossaries include Glossary of computer science, Glossary of robotics, and Glossary of machine vision.
The following outline is provided as an overview of and topical guide to machine learning:
Machine learning in bioinformatics is the application of machine learning algorithms to bioinformatics, including genomics, proteomics, microarrays, systems biology, evolution, and text mining.
Soft computing is an umbrella term used to describe types of algorithms that produce approximate solutions to unsolvable high-level problems in computer science. Typically, traditional hard-computing algorithms heavily rely on concrete data and mathematical models to produce solutions to problems. Soft computing was coined in the late 20th century. During this period, revolutionary research in three fields greatly impacted soft computing. Fuzzy logic is a computational paradigm that entertains the uncertainties in data by using levels of truth rather than rigid 0s and 1s in binary. Next, neural networks which are computational models influenced by human brain functions. Finally, evolutionary computation is a term to describe groups of algorithm that mimic natural processes such as evolution and natural selection.
Nikola Kirilov Kasabov also known as Nikola Kirilov Kassabov is a Bulgarian and New Zealand computer scientist, academic and author. He is a professor emeritus of Knowledge Engineering at Auckland University of Technology, Founding Director of the Knowledge Engineering and Discovery Research Institute (KEDRI), George Moore Chair of Data Analytics at Ulster University, as well as visiting professor at both the Institute for Information and Communication Technologies (IICT) at the Bulgarian Academy of Sciences and Dalian University in China. He is also the Founder and Director of Knowledge Engineering Consulting.
References
- ↑ David, A., Freedman. (2006). On The So-Called “Huber Sandwich Estimator” and “Robust Standard Errors”. The American Statistician, 60(4):299-302. doi : 10.1198/000313006X152207
- ↑ Richard, O., Duda., Peter, E., Hart. (1973). Pattern classification and scene analysis.
- ↑ J., A., Goguen. (1973). Zadeh L. A.. Fuzzy sets. Information and control, vol. 8 (1965), pp. 338–353. Zadeh L. A.. Similarity relations and fuzzy orderings. Information sciences, vol. 3 (1971), pp. 177–200.. Journal of Symbolic Logic, 38(4):656-657. doi : 10.2307/2272014
- ↑ Simon, Haykin. (2009). Neural Networks and Learning Machines 3rd Edition : Simon Haykin.
- ↑ David, E., Goldberg. (1988). Genetic algorithms in search, optimization, and machine learning. University of Alabama.
- ↑ Vapnik, V. (1995). The nature of statistical learning theory. Springer.
- ↑ Paul, Hewson. (2015). Bayesian Data Analysis 3rd edn A. Gelman, J. B. Carlin, H. S. Stern, D. B. Dunson, A. Vehtari and D. B. Rubin, 2013 Boca Raton, Chapman and Hall–CRC 676 pp., ISBN 1-4398-4095-4. Journal of The Royal Statistical Society Series A-statistics in Society, 178(1):301-301. doi : 10.1111/J.1467-985X.2014.12096_1.X
- ↑ Usama, M., Fayyad., Gregory, Piatetsky-Shapiro., Padhraic, Smyth. (1996). From Data Mining to Knowledge Discovery in Databases. Ai Magazine, 17(3):37-54. doi : 10.1609/AIMAG.V17I3.1230
- ↑ Mitchell, T. M. (1997). Machine learning. McGraw Hill Series in Computer Science.
- ↑ Alpaydin, E. (2020). Introduction to machine learning. MIT Press. ISBN 978-0-262-01243-0
- ↑ Robert, J., Abrahart., Linda, M., See., Dimitri, Solomatine. (2008). Practical hydroinformatics : computational intelligence and technological developments in water applications.
- ↑ G.A., Corzo, Perez. (2009). Hybrid models for Hydrological Forecasting: integration of data-driven and conceptual modelling techniques.
- ↑ Foster, Provost., Tom, Fawcett. (2013). Data Science for Business: What You Need to Know about Data Mining and Data-Analytic Thinking.
- ↑ M., Cheng., Fangxin, Fang., Christopher, C., Pain., Ionel, Michael, Navon. (2020). Data-driven modelling of nonlinear spatio-temporal fluid flows using a deep convolutional generative adversarial network. Computer Methods in Applied Mechanics and Engineering, 365:113000-. doi : 10.1016/J.CMA.2020.113000