Related Research Articles
Computational linguistics is an interdisciplinary field concerned with the computational modelling of natural language, as well as the study of appropriate computational approaches to linguistic questions. In general, computational linguistics draws upon linguistics, computer science, artificial intelligence, mathematics, logic, philosophy, cognitive science, cognitive psychology, psycholinguistics, anthropology and neuroscience, among others.
Natural language processing (NLP) is an interdisciplinary subfield of computer science - specifically Artificial Intelligence - and linguistics. It is primarily concerned with providing computers the ability to process data encoded in natural language, typically collected in text corpora, using either rule-based, statistical or neural-based approaches of machine learning and deep learning.
Speech recognition is an interdisciplinary subfield of computer science and computational linguistics that develops methodologies and technologies that enable the recognition and translation of spoken language into text by computers. It is also known as automatic speech recognition (ASR), computer speech recognition or speech-to-text (STT). It incorporates knowledge and research in the computer science, linguistics and computer engineering fields. The reverse process is speech synthesis.
In linguistics and related fields, pragmatics is the study of how context contributes to meaning. The field of study evaluates how human language is utilized in social interactions, as well as the relationship between the interpreter and the interpreted. Linguists who specialize in pragmatics are called pragmaticians. The field has been represented since 1986 by the International Pragmatics Association (IPrA).
In the philosophy of language and linguistics, speech act is something expressed by an individual that not only presents information but performs an action as well. For example, the phrase "I would like the kimchi; could you please pass it to me?" is considered a speech act as it expresses the speaker's desire to acquire the kimchi, as well as presenting a request that someone pass the kimchi to them.

In spoken language analysis, an utterance is a continuous piece of speech, by one person, before or after which there is silence on the part of the person. In the case of oral languages, it is generally, but not always, bounded by silence. Utterances do not exist in written language; only their representations do. They can be represented and delineated in written language in many ways.
Question answering (QA) is a computer science discipline within the fields of information retrieval and natural language processing (NLP) that is concerned with building systems that automatically answer questions that are posed by humans in a natural language.

Argumentation theory is the interdisciplinary study of how conclusions can be supported or undermined by premises through logical reasoning. With historical origins in logic, dialectic, and rhetoric, argumentation theory includes the arts and sciences of civil debate, dialogue, conversation, and persuasion. It studies rules of inference, logic, and procedural rules in both artificial and real-world settings.

A dialogue system, or conversational agent (CA), is a computer system intended to converse with a human. Dialogue systems employed one or more of text, speech, graphics, haptics, gestures, and other modes for communication on both the input and output channel.
In linguistics, an adjacency pair is an example of conversational turn-taking. An adjacency pair is composed of two utterances by two speakers, one after the other. The speaking of the first utterance provokes a responding utterance. Adjacency pairs are a component of pragmatic variation in the study of linguistics, and are considered primarily to be evident in the "interactional" function of pragmatics. Adjacency pairs exist in every language and vary in context and content among each, based on the cultural values held by speakers of the respective language. Oftentimes, they are contributed by speakers in an unconscious way, as they are an intrinsic part of the language spoken at-hand and are therefore embedded in speakers' understanding and use of the language. Thus, adjacency pairs may present their challenges when a person begins learning a language not native to them, as the cultural context and significance behind the adjacency pairs may not be evident to a speaker outside of the primary culture associated with the language.
A speech corpus is a database of speech audio files and text transcriptions. In speech technology, speech corpora are used, among other things, to create acoustic models. In linguistics, spoken corpora are used to do research into phonetic, conversation analysis, dialectology and other fields.
A spoken dialog system (SDS) is a computer system able to converse with a human with voice. It has two essential components that do not exist in a written text dialog system: a speech recognizer and a text-to-speech module. It can be further distinguished from command and control speech systems that can respond to requests but do not attempt to maintain continuity over time.
AutoTutor is an intelligent tutoring system developed by researchers at the Institute for Intelligent Systems at the University of Memphis, including Arthur C. Graesser that helps students learn Newtonian physics, computer literacy, and critical thinking topics through tutorial dialogue in natural language. AutoTutor differs from other popular intelligent tutoring systems such as the Cognitive Tutor, in that it focuses on natural language dialog. This means that the tutoring occurs in the form of an ongoing conversation, with human input presented using either voice or free text input. To handle this input, AutoTutor uses computational linguistics algorithms including latent semantic analysis, regular expression matching, and speech act classifiers. These complementary techniques focus on the general meaning of the input, precise phrasing or keywords, and functional purpose of the expression, respectively. In addition to natural language input, AutoTutor can also accept ad hoc events such as mouse clicks, learner emotions inferred from emotion sensors, and estimates of prior knowledge from a student model. Based on these inputs, the computer tutor determine when to reply and what speech acts to reply with. This process is driven by a "script" that includes a set of dialog-specific production rules.
Natural-language user interface is a type of computer human interface where linguistic phenomena such as verbs, phrases and clauses act as UI controls for creating, selecting and modifying data in software applications.
Error-driven learning is a type of reinforcement learning method. This method tweaks a model’s parameters based on the difference between the proposed and actual results. These models stand out as they depend on environmental feedback instead of explicit labels or categories. They are based on the idea that language acquisition involves the minimization of the prediction error (MPSE). By leveraging these prediction errors, the models consistently refine expectations and decrease computational complexity. Typically, these algorithms are operated by the GeneRec algorithm.
The following outline is provided as an overview of and topical guide to natural-language processing:
Emotion recognition is the process of identifying human emotion. People vary widely in their accuracy at recognizing the emotions of others. Use of technology to help people with emotion recognition is a relatively nascent research area. Generally, the technology works best if it uses multiple modalities in context. To date, the most work has been conducted on automating the recognition of facial expressions from video, spoken expressions from audio, written expressions from text, and physiology as measured by wearables.
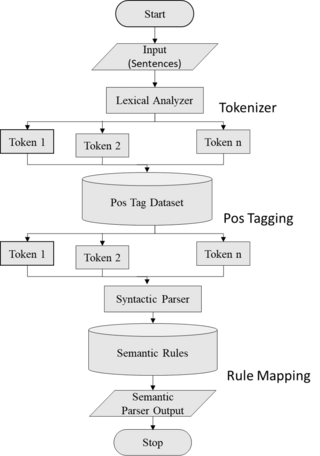
Semantic parsing is the task of converting a natural language utterance to a logical form: a machine-understandable representation of its meaning. Semantic parsing can thus be understood as extracting the precise meaning of an utterance. Applications of semantic parsing include machine translation, question answering, ontology induction, automated reasoning, and code generation. The phrase was first used in the 1970s by Yorick Wilks as the basis for machine translation programs working with only semantic representations. Semantic parsing is one of the important tasks in computational linguistics and natural language processing.
Bidirectional Encoder Representations from Transformers (BERT) is a language model based on the transformer architecture, notable for its dramatic improvement over previous state of the art models. It was introduced in October 2018 by researchers at Google. A 2020 literature survey concluded that "in a little over a year, BERT has become a ubiquitous baseline in Natural Language Processing (NLP) experiments counting over 150 research publications analyzing and improving the model."
Emotion recognition in conversation (ERC) is a sub-field of emotion recognition, that focuses on mining human emotions from conversations or dialogues having two or more interlocutors. The datasets in this field are usually derived from social platforms that allow free and plenty of samples, often containing multimodal data. Self- and inter-personal influences play critical role in identifying some basic emotions, such as, fear, anger, joy, surprise, etc. The more fine grained the emotion labels are the harder it is to detect the correct emotion. ERC poses a number of challenges, such as, conversational-context modeling, speaker-state modeling, presence of sarcasm in conversation, emotion shift across consecutive utterances of the same interlocutor.
References
- ↑ Żelasko, Piotr; Pappagari, Raghavendra; Dehak, Najim (2021). "What Helps Transformers Recognize Conversational Structure? Importance of Context, Punctuation, and Labels in Dialog Act Recognition". Transactions of the Association for Computational Linguistics. 9: 1163–1179. arXiv: 2107.02294 . doi:10.1162/tacl_a_00420. ISSN 2307-387X.
- 1 2 McTear, Michael; Callejas, Zoraida; Griol, David (2016). The Conversational Interface: Talking to Smart Devices. Springer. pp. 162–166. ISBN 9783319329673 . Retrieved 31 May 2018.
- ↑ Stolcke, Andreas; Ries, Klaus; Coccaro, Noah; Shriberg, Elizabeth; Bates, Rebecca; Jurafsky, Daniel; Taylor, Paul; Martin, Rachel; et al. (2000), "Dialogue Act Modeling for Automatic Tagging and Recognition of Conversational Speech" (PDF), Computational Linguistics, 26 (3): 339, arXiv: cs/0006023 , doi:10.1162/089120100561737, S2CID 215825908
| | This sociolinguistics article is a stub. You can help Wikipedia by expanding it. |
| | This pragmatics-related article is a stub. You can help Wikipedia by expanding it. |