{kind=link}
Related Research Articles
In signal processing, data compression, source coding, or bit-rate reduction is the process of encoding information using fewer bits than the original representation. Any particular compression is either lossy or lossless. Lossless compression reduces bits by identifying and eliminating statistical redundancy. No information is lost in lossless compression. Lossy compression reduces bits by removing unnecessary or less important information. Typically, a device that performs data compression is referred to as an encoder, and one that performs the reversal of the process (decompression) as a decoder.
Digital video is an electronic representation of moving visual images (video) in the form of encoded digital data. This is in contrast to analog video, which represents moving visual images in the form of analog signals. Digital video comprises a series of digital images displayed in rapid succession.
Linear predictive coding (LPC) is a method used mostly in audio signal processing and speech processing for representing the spectral envelope of a digital signal of speech in compressed form, using the information of a linear predictive model.
Vector quantization (VQ) is a classical quantization technique from signal processing that allows the modeling of probability density functions by the distribution of prototype vectors. It was originally used for data compression. It works by dividing a large set of points (vectors) into groups having approximately the same number of points closest to them. Each group is represented by its centroid point, as in k-means and some other clustering algorithms.
A discrete cosine transform (DCT) expresses a finite sequence of data points in terms of a sum of cosine functions oscillating at different frequencies. The DCT, first proposed by Nasir Ahmed in 1972, is a widely used transformation technique in signal processing and data compression. It is used in most digital media, including digital images, digital video, digital audio, digital television, digital radio, and speech coding. DCTs are also important to numerous other applications in science and engineering, such as digital signal processing, telecommunication devices, reducing network bandwidth usage, and spectral methods for the numerical solution of partial differential equations.
Affective computing is the study and development of systems and devices that can recognize, interpret, process, and simulate human affects. It is an interdisciplinary field spanning computer science, psychology, and cognitive science. While some core ideas in the field may be traced as far back as to early philosophical inquiries into emotion, the more modern branch of computer science originated with Rosalind Picard's 1995 paper on affective computing and her book Affective Computing published by MIT Press. One of the motivations for the research is the ability to give machines emotional intelligence, including to simulate empathy. The machine should interpret the emotional state of humans and adapt its behavior to them, giving an appropriate response to those emotions.

Face detection is a computer technology being used in a variety of applications that identifies human faces in digital images. Face detection also refers to the psychological process by which humans locate and attend to faces in a visual scene.
FAP may refer to:

Gesture recognition is a topic in computer science and language technology with the goal of interpreting human gestures via mathematical algorithms. It is a subdiscipline of computer vision. Gestures can originate from any bodily motion or state but commonly originate from the face or hand. Current focuses in the field include emotion recognition from face and hand gesture recognition. Users can use simple gestures to control or interact with devices without physically touching them. Many approaches have been made using cameras and computer vision algorithms to interpret sign language. However, the identification and recognition of posture, gait, proxemics, and human behaviors is also the subject of gesture recognition techniques. Gesture recognition can be seen as a way for computers to begin to understand human body language, thus building a richer bridge between machines and humans than primitive text user interfaces or even GUIs, which still limit the majority of input to keyboard and mouse and interact naturally without any mechanical devices.
Computer facial animation is primarily an area of computer graphics that encapsulates methods and techniques for generating and animating images or models of a character face. The character can be a human, a humanoid, an animal, a legendary creature or character, etc. Due to its subject and output type, it is also related to many other scientific and artistic fields from psychology to traditional animation. The importance of human faces in verbal and non-verbal communication and advances in computer graphics hardware and software have caused considerable scientific, technological, and artistic interests in computer facial animation.

Thomas Shi-Tao Huang was a Chinese-born American computer scientist, electrical engineer, and writer. He was a researcher and professor emeritus at the University of Illinois at Urbana-Champaign (UIUC). Huang was one of the leading figures in computer vision, pattern recognition and human computer interaction.

Anastasios (Tas) Venetsanopoulos was a Professor of Electrical and Computer Engineering at Ryerson University in Toronto, Ontario and a Professor Emeritus with the Edward S. Rogers Department of Electrical and Computer Engineering at the University of Toronto. In October 2006, Professor Venetsanopoulos joined Ryerson University and served as the Founding Vice-President of Research and Innovation. His portfolio included oversight of the university's international activities, research ethics, Office of Research Services, and Office of Innovation and Commercialization. He retired from that position in 2010, but remained a distinguished advisor to the role. Tas Venetsanopoulos continued to actively supervise his research group at the University of Toronto, and was a highly sought-after consultant throughout his career.
Soft Biometrics traits are physical, behavioural or adhered human characteristics, classifiable in pre–defined human compliant categories. These categories are, unlike in the classical biometric case, established and time–proven by humans with the aim of differentiating individuals. In other words the soft biometric traits instances are created in a natural way, used by humans to distinguish their peers.
The Rich Representation Language, often abbreviated as RRL, is a computer animation language specifically designed to facilitate the interaction of two or more animated characters. The research effort was funded by the European Commission as part of the NECA Project. The NECA framework within which RRL was developed was not oriented towards the animation of movies, but the creation of intelligent "virtual characters" that interact within a virtual world and hold conversations with emotional content, coupled with suitable facial expressions.
A video coding format is a content representation format for storage or transmission of digital video content. It typically uses a standardized video compression algorithm, most commonly based on discrete cosine transform (DCT) coding and motion compensation. Examples of video coding formats include H.262, MPEG-4 Part 2, H.264, HEVC (H.265), Theora, RealVideo RV40, VP9, and AV1. A specific software or hardware implementation capable of compression or decompression to/from a specific video coding format is called a video codec; an example of a video codec is Xvid, which is one of several different codecs which implements encoding and decoding videos in the MPEG-4 Part 2 video coding format in software.

A biometric device is a security identification and authentication device. Such devices use automated methods of verifying or recognising the identity of a living person based on a physiological or behavioral characteristic. These characteristics include fingerprints, facial images, iris and voice recognition.
visage|SDK is a multiplatform software development kit (SDK) created by Visage Technologies AB. visage|SDK allows software programmers to build a wide variety of face and head tracking and eye tracking applications for various operating systems, mobile and tablet environments, and embedded systems, using computer vision and machine learning algorithms.
Visage Technologies AB is a private company that produces computer vision software for face tracking and face analysis, along with a special business unit in automotive industry. The primary product of Visage Technologies is a multiplatform software development kit visageSDK.
Emotion recognition is the process of identifying human emotion. People vary widely in their accuracy at recognizing the emotions of others. Use of technology to help people with emotion recognition is a relatively nascent research area. Generally, the technology works best if it uses multiple modalities in context. To date, the most work has been conducted on automating the recognition of facial expressions from video, spoken expressions from audio, written expressions from text, and physiology as measured by wearables.
Mark S. Nixon is an author, researcher, editor and an academic. He is the former president of IEEE Biometrics Council, and former vice-Chair of IEEE PSPB. He retired from his position as Professor of Electronics and Computer Science at University of Southampton in 2019.
References
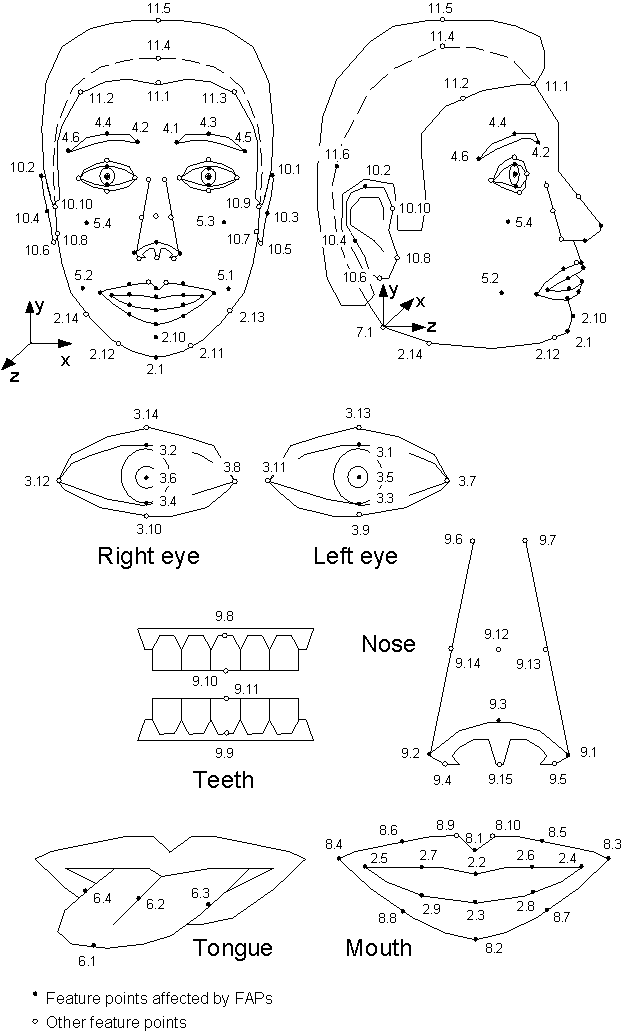
- 1 2 Ostermann, Jörn (August 2002). "Chapter 2: Face Animation in MPEG-4". In Pandzic, Igor; Forchheimer, Robert (eds.). MPEG-4 Facial Animation: The Standard, Implementation and Applications . Wiley. pp. 17–55. ISBN 978-0-470-84465-6.
- ↑ Tao, Hai; Chen, H.H.; Wu, Wei; Huang, T.S. (1999). "Compression of MPEG-4 facial animation parameters for transmission of talking heads". IEEE Transactions on Circuits and Systems for Video Technology. IEEE Press. 9 (3): 264–276. doi:10.1109/76.752094.
- ↑ Petajan, Eric (September 2005). "MPEG-4 Face and Body Animation Coding Applied to HCI". In Kisačanin, B.; Pavlović, V.; Wang, T.S. (eds.). Real-time vision for human-computer interaction . Springer. pp. 249–268. ISBN 0387276971.
- ↑ Petajan, Eric (January 1, 2009). "Chapter 4: Visual Speech and Gesture Coding Using the MPEG-4 Face and Body Animation Standard". In Wee-Chung Liew, Alan (ed.). Visual Speech Recognition: Lip Segmentation and Mapping. IGI Global. pp. 128–148. ISBN 9781605661872.
- ↑ Aleksic, P.S.; Katsaggelos, A.K. (November 2006). "Audio-Visual Biometrics". Proceedings of the IEEE. IEEE Press. 94 (11): 2025–2044. doi:10.1109/JPROC.2006.886017.