
In computing, a data warehouse, also known as an enterprise data warehouse (EDW), is a system used for reporting and data analysis and is a core component of business intelligence. Data warehouses are central repositories of data integrated from disparate sources. They store current and historical data organized so as to make it easy to create reports, query and get insights from the data. Unlike databases, they are intended to be used by analysts and managers to help make organizational decisions.
Denormalization is a strategy used on a previously-normalized database to increase performance. In computing, denormalization is the process of trying to improve the read performance of a database, at the expense of losing some write performance, by adding redundant copies of data or by grouping data. It is often motivated by performance or scalability in relational database software needing to carry out very large numbers of read operations. Denormalization differs from the unnormalized form in that denormalization benefits can only be fully realized on a data model that is otherwise normalized.

Db2 is a family of data management products, including database servers, developed by IBM. It initially supported the relational model, but was extended to support object–relational features and non-relational structures like JSON and XML. The brand name was originally styled as DB2 until 2017, when it changed to its present form.
In computing, online analytical processing, or OLAP, is an approach to quickly answer multi-dimensional analytical (MDA) queries. The term OLAP was created as a slight modification of the traditional database term online transaction processing (OLTP). OLAP is part of the broader category of business intelligence, which also encompasses relational databases, report writing and data mining. Typical applications of OLAP include business reporting for sales, marketing, management reporting, business process management (BPM), budgeting and forecasting, financial reporting and similar areas, with new applications emerging, such as agriculture.

Extract, transform, load (ETL) is a three-phase computing process where data is extracted from an input source, transformed, and loaded into an output data container. The data can be collated from one or more sources and it can also be output to one or more destinations. ETL processing is typically executed using software applications but it can also be done manually by system operators. ETL software typically automates the entire process and can be run manually or on recurring schedules either as single jobs or aggregated into a batch of jobs.
A data mart is a structure/access pattern specific to data warehouse environments. The data mart is a subset of the data warehouse and is usually oriented to a specific business line or team. Whereas data warehouses have an enterprise-wide depth, the information in data marts pertains to a single department. In some deployments, each department or business unit is considered the owner of its data mart including all the hardware, software and data. This enables each department to isolate the use, manipulation and development of their data. In other deployments where conformed dimensions are used, this business unit owner will not hold true for shared dimensions like customer, product, etc.

An OLAP cube is a multi-dimensional array of data. Online analytical processing (OLAP) is a computer-based technique of analyzing data to look for insights. The term cube here refers to a multi-dimensional dataset, which is also sometimes called a hypercube if the number of dimensions is greater than three.

In computing, the star schema or star model is the simplest style of data mart schema and is the approach most widely used to develop data warehouses and dimensional data marts. The star schema consists of one or more fact tables referencing any number of dimension tables. The star schema is an important special case of the snowflake schema, and is more effective for handling simpler queries.
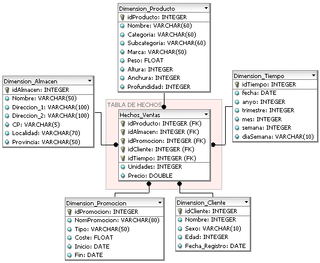
In data warehousing, a fact table consists of the measurements, metrics or facts of a business process. It is located at the center of a star schema or a snowflake schema surrounded by dimension tables. Where multiple fact tables are used, these are arranged as a fact constellation schema. A fact table typically has two types of columns: those that contain facts and those that are a foreign key to dimension tables. The primary key of a fact table is usually a composite key that is made up of all of its foreign keys. Fact tables contain the content of the data warehouse and store different types of measures like additive, non-additive, and semi-additive measures.

In computing, a snowflake schema or snowflake model is a logical arrangement of tables in a multidimensional database such that the entity relationship diagram resembles a snowflake shape. The snowflake schema is represented by centralized fact tables which are connected to multiple dimensions. "Snowflaking" is a method of normalizing the dimension tables in a star schema. When it is completely normalized along all the dimension tables, the resultant structure resembles a snowflake with the fact table in the middle. The principle behind snowflaking is normalization of the dimension tables by removing low cardinality attributes and forming separate tables.
Online transaction processing (OLTP) is a type of database system used in transaction-oriented applications, such as many operational systems. "Online" refers to the fact that such systems are expected to respond to user requests and process them in real-time. The term is contrasted with online analytical processing (OLAP) which instead focuses on data analysis.

A dimension is a structure that categorizes facts and measures in order to enable users to answer business questions. Commonly used dimensions are people, products, place and time.
According to Ralph Kimball, in a data warehouse, a degenerate dimension is a dimension key in the fact table that does not have its own dimension table, because all the interesting attributes have been placed in analytic dimensions. The term "degenerate dimension" was originated by Ralph Kimball.
In data management and data warehousing, a slowly changing dimension (SCD) is a dimension that stores data which, while generally stable, may change over time, often in an unpredictable manner. This contrasts with a rapidly changing dimension, such as transactional parameters like customer ID, product ID, quantity, and price, which undergo frequent updates. Common examples of SCDs include geographical locations, customer details, or product attributes.
Dimensional modeling (DM) is part of the Business Dimensional Lifecycle methodology developed by Ralph Kimball which includes a set of methods, techniques and concepts for use in data warehouse design. The approach focuses on identifying the key business processes within a business and modelling and implementing these first before adding additional business processes, as a bottom-up approach. An alternative approach from Inmon advocates a top down design of the model of all the enterprise data using tools such as entity-relationship modeling (ER).

A database model is a type of data model that determines the logical structure of a database. It fundamentally determines in which manner data can be stored, organized and manipulated. The most popular example of a database model is the relational model, which uses a table-based format.
The dimensional fact model (DFM) is an ad hoc and graphical formalism specifically devised to support the conceptual modeling phase in a data warehouse project. DFM can be used by analysts and non-technical users as well. A short-term working is sufficient to realize a clear and exhaustive representation of multidimensional concepts. It can be used from the initial data warehouse life-cycle steps, to rapidly devise a conceptual model to share with customers.

An aggregate is a type of summary used in dimensional models of data warehouses to shorten the time it takes to provide answers to typical queries on large sets of data. The reason why aggregates can make such a dramatic increase in the performance of a data warehouse is the reduction of the number of rows to be accessed when responding to a query.
The following is provided as an overview of and topical guide to databases:
The reverse star schema is a schema optimized for fast retrieval of large quantities of descriptive data. The design was derived from a warehouse star schema, and its adaptation for descriptive data required that certain key characteristics of the classic star schema be "reversed".