A first-order fluid is another name for a power-law fluid with exponential dependence of viscosity on temperature.

where γ̇ is the shear rate, T is temperature and μ0, n and b are coefficients.
The model can be re-written as
A first-order fluid is another name for a power-law fluid with exponential dependence of viscosity on temperature.
where γ̇ is the shear rate, T is temperature and μ0, n and b are coefficients.
The model can be re-written as

The Pareto distribution, named after the Italian civil engineer, economist, and sociologist Vilfredo Pareto, is a power-law probability distribution that is used in description of social, quality control, scientific, geophysical, actuarial, and many other types of observable phenomena; the principle originally applied to describing the distribution of wealth in a society, fitting the trend that a large portion of wealth is held by a small fraction of the population. The Pareto principle or "80-20 rule" stating that 80% of outcomes are due to 20% of causes was named in honour of Pareto, but the concepts are distinct, and only Pareto distributions with shape value of log45 ≈ 1.16 precisely reflect it. Empirical observation has shown that this 80-20 distribution fits a wide range of cases, including natural phenomena and human activities.

In probability theory and statistics, the Gumbel distribution is used to model the distribution of the maximum of a number of samples of various distributions.

In thermodynamics, the Onsager reciprocal relations express the equality of certain ratios between flows and forces in thermodynamic systems out of equilibrium, but where a notion of local equilibrium exists.
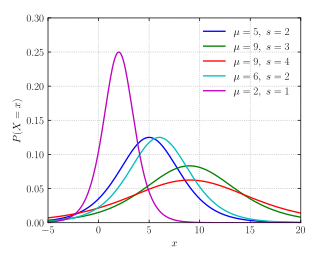
In probability theory and statistics, the logistic distribution is a continuous probability distribution. Its cumulative distribution function is the logistic function, which appears in logistic regression and feedforward neural networks. It resembles the normal distribution in shape but has heavier tails. The logistic distribution is a special case of the Tukey lambda distribution.
In thermodynamics, an activity coefficient is a factor used to account for deviation of a mixture of chemical substances from ideal behaviour. In an ideal mixture, the microscopic interactions between each pair of chemical species are the same and, as a result, properties of the mixtures can be expressed directly in terms of simple concentrations or partial pressures of the substances present e.g. Raoult's law. Deviations from ideality are accommodated by modifying the concentration by an activity coefficient. Analogously, expressions involving gases can be adjusted for non-ideality by scaling partial pressures by a fugacity coefficient.
In probability theory and statistics, the generalized extreme value (GEV) distribution is a family of continuous probability distributions developed within extreme value theory to combine the Gumbel, Fréchet and Weibull families also known as type I, II and III extreme value distributions. By the extreme value theorem the GEV distribution is the only possible limit distribution of properly normalized maxima of a sequence of independent and identically distributed random variables. Note that a limit distribution needs to exist, which requires regularity conditions on the tail of the distribution. Despite this, the GEV distribution is often used as an approximation to model the maxima of long (finite) sequences of random variables.
In statistics and information theory, a maximum entropy probability distribution has entropy that is at least as great as that of all other members of a specified class of probability distributions. According to the principle of maximum entropy, if nothing is known about a distribution except that it belongs to a certain class, then the distribution with the largest entropy should be chosen as the least-informative default. The motivation is twofold: first, maximizing entropy minimizes the amount of prior information built into the distribution; second, many physical systems tend to move towards maximal entropy configurations over time.

In probability theory and directional statistics, the von Mises distribution is a continuous probability distribution on the circle. It is a close approximation to the wrapped normal distribution, which is the circular analogue of the normal distribution. A freely diffusing angle on a circle is a wrapped normally distributed random variable with an unwrapped variance that grows linearly in time. On the other hand, the von Mises distribution is the stationary distribution of a drift and diffusion process on the circle in a harmonic potential, i.e. with a preferred orientation. The von Mises distribution is the maximum entropy distribution for circular data when the real and imaginary parts of the first circular moment are specified. The von Mises distribution is a special case of the von Mises–Fisher distribution on the N-dimensional sphere.

In probability theory and statistics, the chi distribution is a continuous probability distribution over the non-negative real line. It is the distribution of the positive square root of a sum of squared independent Gaussian random variables. Equivalently, it is the distribution of the Euclidean distance between a multivariate Gaussian random variable and the origin. It is thus related to the chi-squared distribution by describing the distribution of the positive square roots of a variable obeying a chi-squared distribution.
A Cross fluid is a type of generalized Newtonian fluid whose viscosity depends upon shear rate according to the following equation:
Carreau fluid in physics is a type of generalized Newtonian fluid where viscosity, , depends upon the shear rate, , by the following equation:
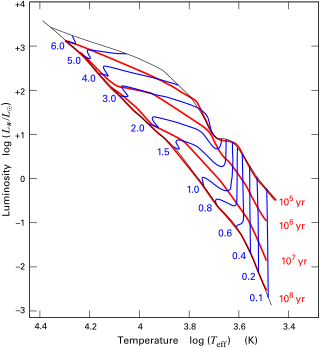
The Hayashi track is a luminosity–temperature relationship obeyed by infant stars of less than 3 M☉ in the pre-main-sequence phase of stellar evolution. It is named after Japanese astrophysicist Chushiro Hayashi. On the Hertzsprung–Russell diagram, which plots luminosity against temperature, the track is a nearly vertical curve. After a protostar ends its phase of rapid contraction and becomes a T Tauri star, it is extremely luminous. The star continues to contract, but much more slowly. While slowly contracting, the star follows the Hayashi track downwards, becoming several times less luminous but staying at roughly the same surface temperature, until either a radiative zone develops, at which point the star starts following the Henyey track, or nuclear fusion begins, marking its entry onto the main sequence.
In mathematics, Gaussian measure is a Borel measure on finite-dimensional Euclidean space , closely related to the normal distribution in statistics. There is also a generalization to infinite-dimensional spaces. Gaussian measures are named after the German mathematician Carl Friedrich Gauss. One reason why Gaussian measures are so ubiquitous in probability theory is the central limit theorem. Loosely speaking, it states that if a random variable is obtained by summing a large number of independent random variables with variance 1, then has variance and its law is approximately Gaussian.
Expected shortfall (ES) is a risk measure—a concept used in the field of financial risk measurement to evaluate the market risk or credit risk of a portfolio. The "expected shortfall at q% level" is the expected return on the portfolio in the worst of cases. ES is an alternative to value at risk that is more sensitive to the shape of the tail of the loss distribution.
In financial mathematics, tail value at risk (TVaR), also known as tail conditional expectation (TCE) or conditional tail expectation (CTE), is a risk measure associated with the more general value at risk. It quantifies the expected value of the loss given that an event outside a given probability level has occurred.

Viscoplasticity is a theory in continuum mechanics that describes the rate-dependent inelastic behavior of solids. Rate-dependence in this context means that the deformation of the material depends on the rate at which loads are applied. The inelastic behavior that is the subject of viscoplasticity is plastic deformation which means that the material undergoes unrecoverable deformations when a load level is reached. Rate-dependent plasticity is important for transient plasticity calculations. The main difference between rate-independent plastic and viscoplastic material models is that the latter exhibit not only permanent deformations after the application of loads but continue to undergo a creep flow as a function of time under the influence of the applied load.
The Herschel–Bulkley fluid is a generalized model of a non-Newtonian fluid, in which the strain experienced by the fluid is related to the stress in a complicated, non-linear way. Three parameters characterize this relationship: the consistency k, the flow index n, and the yield shear stress . The consistency is a simple constant of proportionality, while the flow index measures the degree to which the fluid is shear-thinning or shear-thickening. Ordinary paint is one example of a shear-thinning fluid, while oobleck provides one realization of a shear-thickening fluid. Finally, the yield stress quantifies the amount of stress that the fluid may experience before it yields and begins to flow.

The viscosity of a fluid is a measure of its resistance to deformation at a given rate. For liquids, it corresponds to the informal concept of "thickness": for example, syrup has a higher viscosity than water. Viscosity is defined scientifically as a force multiplied by a time divided by an area. Thus its SI units are newton-seconds per square meter, or pascal-seconds.
In probability theory, the family of complex normal distributions, denoted or , characterizes complex random variables whose real and imaginary parts are jointly normal. The complex normal family has three parameters: location parameter μ, covariance matrix , and the relation matrix . The standard complex normal is the univariate distribution with , , and .
In probability theory and statistics, the generalized multivariate log-gamma (G-MVLG) distribution is a multivariate distribution introduced by Demirhan and Hamurkaroglu in 2011. The G-MVLG is a flexible distribution. Skewness and kurtosis are well controlled by the parameters of the distribution. This enables one to control dispersion of the distribution. Because of this property, the distribution is effectively used as a joint prior distribution in Bayesian analysis, especially when the likelihood is not from the location-scale family of distributions such as normal distribution.
| | This physics-related article is a stub. You can help Wikipedia by expanding it. |
