Related Research Articles

Cluster sampling is a sampling plan used when mutually homogeneous yet internally heterogeneous groupings are evident in a statistical population. It is often used in marketing research. In this sampling plan, the total population is divided into these groups and a simple random sample of the groups is selected. The elements in each cluster are then sampled. If all elements in each sampled cluster are sampled, then this is referred to as a "one-stage" cluster sampling plan. If a simple random subsample of elements is selected within each of these groups, this is referred to as a "two-stage" cluster sampling plan. A common motivation for cluster sampling is to reduce the total number of interviews and costs given the desired accuracy. For a fixed sample size, the expected random error is smaller when most of the variation in the population is present internally within the groups, and not between the groups.
In statistics, an estimator is a rule for calculating an estimate of a given quantity based on observed data: thus the rule, the quantity of interest and its result are distinguished.
Econometrics is the application of statistical methods to economic data in order to give empirical content to economic relationships. More precisely, it is "the quantitative analysis of actual economic phenomena based on the concurrent development of theory and observation, related by appropriate methods of inference". An introductory economics textbook describes econometrics as allowing economists "to sift through mountains of data to extract simple relationships". The first known use of the term "econometrics" was by Polish economist Paweł Ciompa in 1910. Jan Tinbergen is considered by many to be one of the founding fathers of econometrics. Ragnar Frisch is credited with coining the term in the sense in which it is used today.

Statistics is the discipline that concerns the collection, organization, analysis, interpretation and presentation of data. In applying statistics to a scientific, industrial, or social problem, it is conventional to begin with a statistical population or a statistical model to be studied. Populations can be diverse groups of people or objects such as "all people living in a country" or "every atom composing a crystal". Statistics deals with every aspect of data, including the planning of data collection in terms of the design of surveys and experiments. See glossary of probability and statistics.

Statistical inference is the process of using data analysis to deduce properties of an underlying distribution of probability. Inferential statistical analysis infers properties of a population, for example by testing hypotheses and deriving estimates. It is assumed that the observed data set is sampled from a larger population.
In statistics, point estimation involves the use of sample data to calculate a single value which is to serve as a "best guess" or "best estimate" of an unknown population parameter. More formally, it is the application of a point estimator to the data to obtain a point estimate.
Survival analysis is a branch of statistics for analyzing the expected duration of time until one or more events happen, such as death in biological organisms and failure in mechanical systems. This topic is called reliability theory or reliability analysis in engineering, duration analysis or duration modelling in economics, and event history analysis in sociology. Survival analysis attempts to answer certain questions, such as what is the proportion of a population which will survive past a certain time? Of those that survive, at what rate will they die or fail? Can multiple causes of death or failure be taken into account? How do particular circumstances or characteristics increase or decrease the probability of survival?
In statistics, resampling is any of a variety of methods for doing one of the following:
- Estimating the precision of sample statistics by using subsets of available data (jackknifing) or drawing randomly with replacement from a set of data points (bootstrapping)
- Exchanging labels on data points when performing significance tests
- Validating models by using random subsets

In statistics, generalized least squares (GLS) is a technique for estimating the unknown parameters in a linear regression model when there is a certain degree of correlation between the residuals in a regression model. In these cases, ordinary least squares and weighted least squares can be statistically inefficient, or even give misleading inferences. GLS was first described by Alexander Aitken in 1936.
Truncated regression models are a class of models in which the sample has been truncated for certain ranges of the dependent variable. That means observations with values in the dependent variable below or above certain thresholds are systematically excluded from the sample. Therefore, whole observations are missing, so that neither the dependent nor the independent variable is known. This is in contrast to censored regression models where only the value of the dependent variable is clustered at a lower threshold, an upper threshold, or both, while the value for independent variables is available.
Bootstrapping is any test or metric that uses random sampling with replacement, and falls under the broader class of resampling methods. Bootstrapping assigns measures of accuracy to sample estimates. This technique allows estimation of the sampling distribution of almost any statistic using random sampling methods.
The Nelson–Aalen estimator is a non-parametric estimator of the cumulative hazard rate function in case of censored data or incomplete data. It is used in survival theory, reliability engineering and life insurance to estimate the cumulative number of expected events. An "event" can be the failure of a non-repairable component, the death of a human being, or any occurrence for which the experimental unit remains in the "failed" state from the point at which it changed on. The estimator is given by
In statistics, errors-in-variables models or measurement error models are regression models that account for measurement errors in the independent variables. In contrast, standard regression models assume that those regressors have been measured exactly, or observed without error; as such, those models account only for errors in the dependent variables, or responses.
In economic theory and econometrics, the term heterogeneity refers to differences across the units being studied. For example, a macroeconomic model in which consumers are assumed to differ from one another is said to have heterogeneous agents.
In applied statistics, fractional models are, to some extent, related to binary response models. However, instead of estimating the probability of being in one bin of a dichotomous variable, the fractional model typically deals with variables that take on all possible values in the unit interval. One can easily generalize this model to take on values on any other interval by appropriate transformations. Examples range from participation rates in 401(k) plans to television ratings of NBA games.
Issues of heterogeneity in duration models can take on different forms. On the one hand, unobserved heterogeneity can play a crucial role when it comes to different sampling methods, such as stock or flow sampling. On the other hand, duration models have also been extended to allow for different subpopulations, with a strong link to mixture models. Many of these models impose the assumptions that heterogeneity is independent of the observed covariates, it has a distribution that depends on a finite number of parameters only, and it enters the hazard function multiplicatively.
Grouped duration data are widespread in many applications. Unemployment durations are typically measured over weeks or months and these time intervals may be considered too large for continuous approximations to hold. In this case, we will typically have grouping points , where . Models allow for time-invariant and time-variant covariates, but the latter require stronger assumptions in terms of exogeneity. The discrete-time hazard function can be written as:
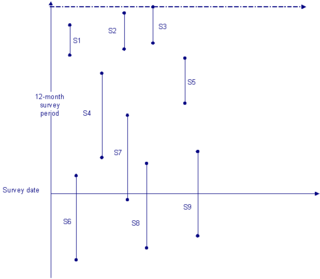
Stock sampling is sampling people in a certain state at the time of the survey. This is in contrast to flow sampling, where the relationship of interest deals with duration or survival analysis. In stock sampling, rather than focusing on transitions within a certain time interval, we only have observations at a certain point in time. This can lead to both left and right censoring. Imposing the same model on data that have been generated under the two different sampling regimes can lead to research reaching fundamentally different conclusions if the joint distribution across the flow and stock samples differ sufficiently.
Xiaohong Chen is a Chinese economist who currently serves as the Malcolm K. Brachman Professor of Economics at Yale University. She is a fellow of the Econometric Society and a laureate of the China Economics Prize. As one of the leading experts in econometrics, her researches focus on econometric theory, Semi/nonparametric estimation and inference methods, Sieve methods, Nonlinear time series, and Semi/nonparametric models. She was elected to the American Academy of Arts and Sciences in 2019.
References
- 1 2 Cameron A. C. and P. K. Trivedi (2005): Microeconometrics: Methods and Applications. Cambridge University Press, New York.
- 1 2 Salant, S. (1977): Search Theory and Duration Data: A Theory of Sorts. The Quarterly Journal of Economics, 91(1), pp. 39–57.
- ↑ Chesher, A. and T. Lancaster (1981): Stock and Flow Sampling. Economics Letters 8(1), pp. 63–65.
- ↑ Wooldridge, J. (2002): Econometric Analysis of Cross Section and Panel Data, MIT Press, Cambridge, Mass.
- ↑ Lancaster, T. (1979): Econometric Methods for the Duration of Unemployment. Econometrica 47(4), pp. 939–956.
- ↑ Hausman, J. A. and T. Woutersen (2014), Estimating a semi-parametric duration model without specifying heterogeneity. Journal of Econometrics 178(1), pp. 114–131.