Related Research Articles
Computational linguistics is an interdisciplinary field concerned with the computational modelling of natural language, as well as the study of appropriate computational approaches to linguistic questions. In general, computational linguistics draws upon linguistics, computer science, artificial intelligence, mathematics, logic, philosophy, cognitive science, cognitive psychology, psycholinguistics, anthropology and neuroscience, among others.
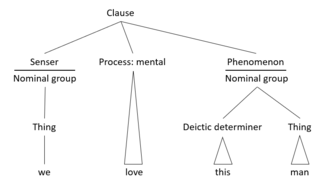
Functional linguistics is an approach to the study of language characterized by taking systematically into account the speaker's and the hearer's side, and the communicative needs of the speaker and of the given language community. Linguistic functionalism spawned in the 1920s to 1930s from Ferdinand de Saussure's systematic structuralist approach to language (1916).
In linguistics, syntax is the study of how words and morphemes combine to form larger units such as phrases and sentences. Central concerns of syntax include word order, grammatical relations, hierarchical sentence structure (constituency), agreement, the nature of crosslinguistic variation, and the relationship between form and meaning (semantics). There are numerous approaches to syntax that differ in their central assumptions and goals.
Phrase structure rules are a type of rewrite rule used to describe a given language's syntax and are closely associated with the early stages of transformational grammar, proposed by Noam Chomsky in 1957. They are used to break down a natural language sentence into its constituent parts, also known as syntactic categories, including both lexical categories and phrasal categories. A grammar that uses phrase structure rules is a type of phrase structure grammar. Phrase structure rules as they are commonly employed operate according to the constituency relation, and a grammar that employs phrase structure rules is therefore a constituency grammar; as such, it stands in contrast to dependency grammars, which are based on the dependency relation.

A parse tree or parsing tree or derivation tree or concrete syntax tree is an ordered, rooted tree that represents the syntactic structure of a string according to some context-free grammar. The term parse tree itself is used primarily in computational linguistics; in theoretical syntax, the term syntax tree is more common.
Head-driven phrase structure grammar (HPSG) is a highly lexicalized, constraint-based grammar developed by Carl Pollard and Ivan Sag. It is a type of phrase structure grammar, as opposed to a dependency grammar, and it is the immediate successor to generalized phrase structure grammar. HPSG draws from other fields such as computer science and uses Ferdinand de Saussure's notion of the sign. It uses a uniform formalism and is organized in a modular way which makes it attractive for natural language processing.
Parsing, syntax analysis, or syntactic analysis is the process of analyzing a string of symbols, either in natural language, computer languages or data structures, conforming to the rules of a formal grammar. The term parsing comes from Latin pars (orationis), meaning part.
Link grammar (LG) is a theory of syntax by Davy Temperley and Daniel Sleator which builds relations between pairs of words, rather than constructing constituents in a phrase structure hierarchy. Link grammar is similar to dependency grammar, but dependency grammar includes a head-dependent relationship, whereas link grammar makes the head-dependent relationship optional. Colored Multiplanar Link Grammar (CMLG) is an extension of LG allowing crossing relations between pairs of words. The relationship between words is indicated with link types, thus making the Link grammar closely related to certain categorial grammars.
In linguistics, the topic, or theme, of a sentence is what is being talked about, and the comment is what is being said about the topic. This division into old vs. new content is called information structure. It is generally agreed that clauses are divided into topic vs. comment, but in certain cases the boundary between them depends on which specific grammatical theory is being used to analyze the sentence.
Dependency grammar (DG) is a class of modern grammatical theories that are all based on the dependency relation and that can be traced back primarily to the work of Lucien Tesnière. Dependency is the notion that linguistic units, e.g. words, are connected to each other by directed links. The (finite) verb is taken to be the structural center of clause structure. All other syntactic units (words) are either directly or indirectly connected to the verb in terms of the directed links, which are called dependencies. Dependency grammar differs from phrase structure grammar in that while it can identify phrases it tends to overlook phrasal nodes. A dependency structure is determined by the relation between a word and its dependents. Dependency structures are flatter than phrase structures in part because they lack a finite verb phrase constituent, and they are thus well suited for the analysis of languages with free word order, such as Czech or Warlpiri.
The term phrase structure grammar was originally introduced by Noam Chomsky as the term for grammar studied previously by Emil Post and Axel Thue. Some authors, however, reserve the term for more restricted grammars in the Chomsky hierarchy: context-sensitive grammars or context-free grammars. In a broader sense, phrase structure grammars are also known as constituency grammars. The defining trait of phrase structure grammars is thus their adherence to the constituency relation, as opposed to the dependency relation of dependency grammars.

In linguistics, a treebank is a parsed text corpus that annotates syntactic or semantic sentence structure. The construction of parsed corpora in the early 1990s revolutionized computational linguistics, which benefitted from large-scale empirical data.
Constraint grammar (CG) is a methodological paradigm for natural language processing (NLP). Linguist-written, context-dependent rules are compiled into a grammar that assigns grammatical tags ("readings") to words or other tokens in running text. Typical tags address lemmatisation, inflexion, derivation, syntactic function, dependency, valency, case roles, semantic type etc. Each rule either adds, removes, selects or replaces a tag or a set of grammatical tags in a given sentence context. Context conditions can be linked to any tag or tag set of any word anywhere in the sentence, either locally or globally. Context conditions in the same rule may be linked, i.e. conditioned upon each other, negated, or blocked by interfering words or tags. Typical CGs consist of thousands of rules, that are applied set-wise in progressive steps, covering ever more advanced levels of analysis. Within each level, safe rules are used before heuristic rules, and no rule is allowed to remove the last reading of a given kind, thus providing a high degree of robustness.
Petr Sgall was a Czech linguist. He specialized in dependency grammar, topic–focus articulation and Common Czech.
Linguistic categories include
The International Corpus of English (ICE) is a set of text corpora representing varieties of English from around the world. Over twenty countries or groups of countries where English is the first language or an official second language are included.
Combinatory categorial grammar (CCG) is an efficiently parsable, yet linguistically expressive grammar formalism. It has a transparent interface between surface syntax and underlying semantic representation, including predicate–argument structure, quantification and information structure. The formalism generates constituency-based structures and is therefore a type of phrase structure grammar.

In linguistics, the term formalism is used in a variety of meanings which relate to formal linguistics in different ways. In common usage, it is merely synonymous with a grammatical model or a syntactic model: a method for analyzing sentence structures. Such formalisms include different methodologies of generative grammar which are especially designed to produce grammatically correct strings of words; or the likes of Functional Discourse Grammar which builds on predicate logic.
Universal Dependencies, frequently abbreviated as UD, is an international cooperative project to create treebanks of the world's languages. These treebanks are openly accessible and available. Core applications are automated text processing in the field of natural language processing (NLP) and research into natural language syntax and grammar, especially within linguistic typology. The project's primary aim is to achieve cross-linguistic consistency of annotation, while still permitting language-specific extensions when necessary. The annotation scheme has it roots in three related projects: Stanford Dependencies, Google universal part-of-speech tags, and the Interset interlingua for morphosyntactic tagsets. The UD annotation scheme uses a representation in the form of dependency trees as opposed to a phrase structure trees. At the present time, there are just over 200 treebanks of more than 100 languages available in the UD inventory.
Syntactic parsing is the automatic analysis of syntactic structure of natural language, especially syntactic relations and labelling spans of constituents. It is motivated by the problem of structural ambiguity in natural language: a sentence can be assigned multiple grammatical parses, so some kind of knowledge beyond computational grammar rules is needed to tell which parse is intended. Syntactic parsing is one of the important tasks in computational linguistics and natural language processing, and has been a subject of research since the mid-20th century with the advent of computers.
References
- Sgall, P., Hajičová, E., Panevová, J. (1986). The Meaning of the Sentence in Its Semantic and Pragmatic Aspects. Dordrecht: D. Reidel Publishing Company. ISBN 90-277-1838-5.