Related Research Articles

In computing, floating-point arithmetic (FP) is arithmetic using formulaic representation of real numbers as an approximation to support a trade-off between range and precision. For this reason, floating-point computation is often used in systems with very small and very large real numbers that require fast processing times. In general, a floating-point number is represented approximately with a fixed number of significant digits and scaled using an exponent in some fixed base; the base for the scaling is normally two, ten, or sixteen. A number that can be represented exactly is of the following form:

Loss of significance is an undesirable effect in calculations using finite-precision arithmetic such as floating-point arithmetic. It occurs when an operation on two numbers increases relative error substantially more than it increases absolute error, for example in subtracting two nearly equal numbers. The effect is that the number of significant digits in the result is reduced unacceptably. Ways to avoid this effect are studied in numerical analysis.

In mathematics, tables of trigonometric functions are useful in a number of areas. Before the existence of pocket calculators, trigonometric tables were essential for navigation, science and engineering. The calculation of mathematical tables was an important area of study, which led to the development of the first mechanical computing devices.
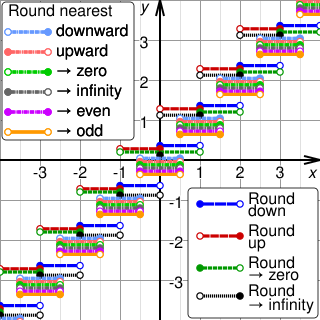
Rounding means replacing a number with an approximate value that has a shorter, simpler, or more explicit representation. For example, replacing $23.4476 with $23.45, the fraction 312/937 with 1/3, or the expression √2 with 1.414.
In computer science, a lookup table is an array that replaces runtime computation with a simpler array indexing operation. The savings in processing time can be significant, because retrieving a value from memory is often faster than carrying out an "expensive" computation or input/output operation. The tables may be precalculated and stored in static program storage, calculated as part of a program's initialization phase (memoization), or even stored in hardware in application-specific platforms. Lookup tables are also used extensively to validate input values by matching against a list of valid items in an array and, in some programming languages, may include pointer functions to process the matching input. FPGAs also make extensive use of reconfigurable, hardware-implemented, lookup tables to provide programmable hardware functionality.
In numerical analysis, the Kahan summation algorithm, also known as compensated summation, significantly reduces the numerical error in the total obtained by adding a sequence of finite-precision floating-point numbers, compared to the obvious approach. This is done by keeping a separate running compensation.
In computing, especially digital signal processing, the multiply–accumulate operation is a common step that computes the product of two numbers and adds that product to an accumulator. The hardware unit that performs the operation is known as a multiplier–accumulator ; the operation itself is also often called a MAC or a MAC operation. The MAC operation modifies an accumulator a:
The IEEE Standard for Floating-Point Arithmetic is a technical standard for floating-point arithmetic established in 1985 by the Institute of Electrical and Electronics Engineers (IEEE). The standard addressed many problems found in the diverse floating-point implementations that made them difficult to use reliably and portably. Many hardware floating-point units use the IEEE 754 standard.
CORDIC, also known as Volder's algorithm, or: Digit-by-digit methodCircular CORDIC, Linear CORDIC, Hyperbolic CORDIC, and Generalized Hyperbolic CORDIC, is a simple and efficient algorithm to calculate trigonometric functions, hyperbolic functions, square roots, multiplications, divisions, and exponentials and logarithms with arbitrary base, typically converging with one digit per iteration. CORDIC is therefore also an example of digit-by-digit algorithms. CORDIC and closely related methods known as pseudo-multiplication and pseudo-division or factor combining are commonly used when no hardware multiplier is available, as the only operations it requires are additions, subtractions, bitshift and lookup tables. As such, they all belong to the class of shift-and-add algorithms. In computer science, CORDIC is often used to implement floating-point arithmetic when the target platform lacks hardware multiply for cost or space reasons.
In computer science and numerical analysis, unit in the last place or unit of least precision (ULP) is the spacing between two consecutive floating-point numbers, i.e., the value the least significant digit represents if it is 1. It is used as a measure of accuracy in numeric calculations.
Machine epsilon gives an upper bound on the relative error due to rounding in floating point arithmetic. This value characterizes computer arithmetic in the field of numerical analysis, and by extension in the subject of computational science. The quantity is also called macheps or unit roundoff, and it has the symbols Greek epsilon or bold Roman u, respectively.
A division algorithm is an algorithm which, given two integers N and D, computes their quotient and/or remainder, the result of Euclidean division. Some are applied by hand, while others are employed by digital circuit designs and software.
Extended precision refers to floating-point number formats that provide greater precision than the basic floating-point formats. Extended precision formats support a basic format by minimizing roundoff and overflow errors in intermediate values of expressions on the base format. In contrast to extended precision, arbitrary-precision arithmetic refers to implementations of much larger numeric types using special software.
The BKM algorithm is a shift-and-add algorithm for computing elementary functions, first published in 1994 by Jean-Claude Bajard, Sylvanus Kla, and Jean-Michel Muller. BKM is based on computing complex logarithms (L-mode) and exponentials (E-mode) using a method similar to the algorithm Henry Briggs used to compute logarithms. By using a precomputed table of logarithms of negative powers of two, the BKM algorithm computes elementary functions using only integer add, shift, and compare operations.

Fast inverse square root, sometimes referred to as Fast InvSqrt or by the hexadecimal constant 0x5F3759DF, is an algorithm that estimates 1⁄√x, the reciprocal of the square root of a 32-bit floating-point number x in IEEE 754 floating-point format. This operation is used in digital signal processing to normalize a vector, i.e., scale it to length 1. For example, computer graphics programs use inverse square roots to compute angles of incidence and reflection for lighting and shading. The algorithm is best known for its implementation in 1999 in the source code of Quake III Arena, a first-person shooter video game that made heavy use of 3D graphics. The algorithm only started appearing on public forums such as Usenet in 2002 or 2003. At the time, it was generally computationally expensive to compute the reciprocal of a floating-point number, especially on a large scale; the fast inverse square root bypassed this step.
In computing, quadruple precision is a binary floating point–based computer number format that occupies 16 bytes with precision at least twice the 53-bit double precision.
As with other spreadsheets, Microsoft Excel works only to limited accuracy because it retains only a certain number of figures to describe numbers. With some exceptions regarding erroneous values, infinities, and denormalized numbers, Excel calculates in double-precision floating-point format from the IEEE 754 specification. Although Excel can display 30 decimal places, its precision for a specified number is confined to 15 significant figures, and calculations may have an accuracy that is even less due to five issues: round off, truncation, and binary storage, accumulation of the deviations of the operands in calculations, and worst: cancellation at subtractions resp. 'Catastrophic cancellation' at subtraction of values with similar magnitude.
Unums are a family of formats and arithmetic, similar to floating point, proposed by John L. Gustafson. They are designed as an alternative to the ubiquitous IEEE 754 floating-point standard and the latest version can be used as a drop-in replacement for programs which do not depend on specific features of IEEE 754.
In computing, tapered floating point (TFP) is a format similar to floating point, but with variable-sized entries for the significand and exponent instead of the fixed-length entries found in normal floating-point formats. In addition to this, tapered floating-point formats provide a fixed-size pointer entry indicating the number of digits in the exponent entry. The number of digits of the significand entry results from the difference of the fixed total length minus the length of the exponent and pointer entries.
In floating-point arithmetic, the Sterbenz lemma or Sterbenz' lemma is a theorem giving conditions under which floating-point differences are computed exactly. It is named after Pat H. Sterbenz, who published it as Theorem 4.3.1 in his 1974 book Floating-Point Computation.
References
- Gal, Shmuel (1986). "Computing elementary functions: A new approach for achieving high accuracy and good performance". In Miranker, Willard L.; Toupin, Richard A. (eds.). Accurate Scientific Computations (1 ed.). Proceedings of Computations, Symposium, Bad Neuenahr, Federal Republic of Germany, March 12-14, 1985: Springer-Verlag Berlin Heidelberg. p. 1–16. ISBN 978-3-540-16798-3.CS1 maint: location (link)
- Gal, Shmuel; Bachelis, Boris (1991). "An accurate elementary mathematical library for the IEEE floating point standard". ACM Transactions on Mathematical Software .
- Muller, Jean-Michel (2006). Elementary Functions: Algorithms and Implementation (2 ed.). Boston, MA, USA: Birkhäuser. ISBN 978-0-8176-4372-0. LCCN 2005048094.
- Muller, Jean-Michel (2016-12-12). Elementary Functions: Algorithms and Implementation (3 ed.). Boston, MA, USA: Birkhäuser. ISBN 978-1-4899-7981-0.
- Stehlé, Damien; Zimmermann, Paul (2005). "Gal's Accurate Tables Method Revisited" (PDF). 17th IEEE Symposium on Computer Arithmetic (ARITH'05). pp. 257–264. doi:10.1109/ARITH.2005.24. ISBN 0-7695-2366-8. Archived (PDF) from the original on 2018-01-15. Retrieved 2018-01-15.