
In algorithmic information theory, the Kolmogorov complexity of an object, such as a piece of text, is the length of a shortest computer program that produces the object as output. It is a measure of the computational resources needed to specify the object, and is also known as algorithmic complexity, Solomonoff–Kolmogorov–Chaitin complexity, program-size complexity, descriptive complexity, or algorithmic entropy. It is named after Andrey Kolmogorov, who first published on the subject in 1963.
In the computer science subfield of algorithmic information theory, a Chaitin constant or halting probability is a real number that, informally speaking, represents the probability that a randomly constructed program will halt. These numbers are formed from a construction due to Gregory Chaitin.

In information theory, the Hamming distance between two strings of equal length is the number of positions at which the corresponding symbols are different. In other words, it measures the minimum number of substitutions required to change one string into the other, or the minimum number of errors that could have transformed one string into the other. In a more general context, the Hamming distance is one of several string metrics for measuring the edit distance between two sequences. It is named after the American mathematician Richard Hamming.
In theoretical computer science, communication complexity studies the amount of communication required to solve a problem when the input to the problem is distributed among two or more parties. The study of communication complexity was first introduced by Andrew Yao in 1979, while studying the problem of computation distributed among several machines. The problem is usually stated as follows: two parties each receive a -bit string and . The goal is for Alice to compute the value of a certain function, , that depends on both and , with the least amount of communication between them.
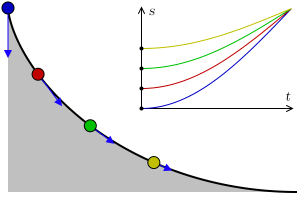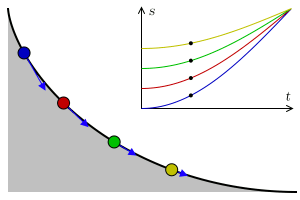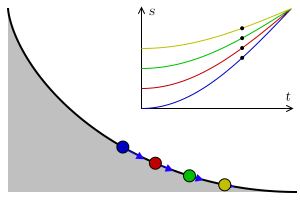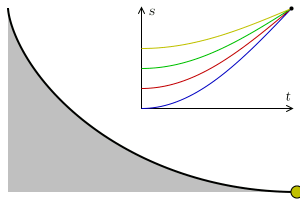
A tautochrone or isochrone curve is the curve for which the time taken by an object sliding without friction in uniform gravity to its lowest point is independent of its starting point on the curve. The curve is a cycloid, and the time is equal to π times the square root of the radius over the acceleration of gravity. The tautochrone curve is related to the brachistochrone curve, which is also a cycloid.
In information theory, linguistics and computer science, the Levenshtein distance is a string metric for measuring the difference between two sequences. Informally, the Levenshtein distance between two words is the minimum number of single-character edits required to change one word into the other. It is named after the Soviet mathematician Vladimir Levenshtein, who considered this distance in 1965.
In computational linguistics and computer science, edit distance is a way of quantifying how dissimilar two strings are to one another by counting the minimum number of operations required to transform one string into the other. Edit distances find applications in natural language processing, where automatic spelling correction can determine candidate corrections for a misspelled word by selecting words from a dictionary that have a low distance to the word in question. In bioinformatics, it can be used to quantify the similarity of DNA sequences, which can be viewed as strings of the letters A, C, G and T.
In computational complexity theory, an Arthur–Merlin protocol is an interactive proof system in which the verifier's coin tosses are constrained to be public. This notion was introduced by Babai (1985). Goldwasser & Sipser (1986) proved that all (formal) languages with interactive proofs of arbitrary length with private coins also have interactive proofs with public coins.
A Tsirelson bound is an upper limit to quantum mechanical correlations between distant events. Given that quantum mechanics is non-local, a natural question to ask is "how non-local can quantum mechanics be?", or, more precisely, by how much can the Bell inequality be violated. The answer is precisely the Tsirelson bound for the particular Bell inequality in question. In general, this bound is lower than what would be possible without signalling faster than light, and much research has been dedicated to the question of why this is the case.

In theoretical computer science, circuit complexity is a branch of computational complexity theory in which Boolean functions are classified according to the size or depth of the Boolean circuits that compute them. A related notion is the circuit complexity of a recursive language that is decided by a uniform family of circuits .
In theoretical physics, quantum nonlocality refers to the phenomenon by which the measurement statistics of a multipartite quantum system do not admit an interpretation in terms of a local realistic theory. Quantum nonlocality has been experimentally verified under different physical assumptions. Any physical theory that aims at superseding or replacing quantum theory should account for such experiments and therefore must also be nonlocal in this sense; quantum nonlocality is a property of the universe that is independent of our description of nature.
In coding theory, list decoding is an alternative to unique decoding of error-correcting codes for large error rates. The notion was proposed by Elias in the 1950s. The main idea behind list decoding is that the decoding algorithm instead of outputting a single possible message outputs a list of possibilities one of which is correct. This allows for handling a greater number of errors than that allowed by unique decoding.
In theoretical computer science, the Aanderaa–Karp–Rosenberg conjecture is a group of related conjectures about the number of questions of the form "Is there an edge between vertex u and vertex v?" that have to be answered to determine whether or not an undirected graph has a particular property such as planarity or bipartiteness. They are named after Stål Aanderaa, Richard M. Karp, and Arnold L. Rosenberg. According to the conjecture, for a wide class of properties, no algorithm can guarantee that it will be able to skip any questions: any algorithm for determining whether the graph has the property, no matter how clever, might need to examine every pair of vertices before it can give its answer. A property satisfying this conjecture is called evasive.
In computer science, streaming algorithms are algorithms for processing data streams in which the input is presented as a sequence of items and can be examined in only a few passes. In most models, these algorithms have access to limited memory. They may also have limited processing time per item.
Quantum complexity theory is the subfield of computational complexity theory that deals with complexity classes defined using quantum computers, a computational model based on quantum mechanics. It studies the hardness of computational problems in relation to these complexity classes, as well as the relationship between quantum complexity classes and classical complexity classes.
In probability theory, concentration inequalities provide bounds on how a random variable deviates from some value. The law of large numbers of classical probability theory states that sums of independent random variables are, under very mild conditions, close to their expectation with a large probability. Such sums are the most basic examples of random variables concentrated around their mean. Recent results show that such behavior is shared by other functions of independent random variables.
In computer science, the cell-probe model is a model of computation similar to the random-access machine, except that all operations are free except memory access. This model is useful for proving lower bounds of algorithms for data structure problems.
In the field of computational biology, a planted motif search (PMS) also known as a (l, d)-motif search (LDMS) is a method for identifying conserved motifs within a set of nucleic acid or peptide sequences.
In mathematics, the incompressibility method is a proof method like the probabilistic method, the counting method or the pigeonhole principle. To prove that an object in a certain class satisfies a certain property, select an object of that class which is incompressible. If it does not satisfy the property, it can be compressed by computable coding. Since it can be generally proven that almost all objects in a given class are incompressible, the argument demonstrates that almost all objects in the class have the property involved. To select an incompressible object is ineffective, and cannot be done by a computer program. However, a simple counting argument usually shows that almost all objects of a given class can be compressed by only a few bits.
The Hidden Matching Problem is a computation complexity problem that can be solved using quantum protocols: Let be a positive even integer. In the Hidden Matching Problem, Alice is given and Bob is given ( denotes the family of all possible perfect matchings on nodes). Their goal is to output a tuple such that the edge belongs to the matching and .












