Related Research Articles

In computational complexity theory, NP-hardness is the defining property of a class of problems that are informally "at least as hard as the hardest problems in NP". A simple example of an NP-hard problem is the subset sum problem.

Combinatorial optimization is a subfield of mathematical optimization that consists of finding an optimal object from a finite set of objects, where the set of feasible solutions is discrete or can be reduced to a discrete set. Typical combinatorial optimization problems are the travelling salesman problem ("TSP"), the minimum spanning tree problem ("MST"), and the knapsack problem. In many such problems, such as the ones previously mentioned, exhaustive search is not tractable, and so specialized algorithms that quickly rule out large parts of the search space or approximation algorithms must be resorted to instead.

In combinatorial mathematics, the Steiner tree problem, or minimum Steiner tree problem, named after Jakob Steiner, is an umbrella term for a class of problems in combinatorial optimization. While Steiner tree problems may be formulated in a number of settings, they all require an optimal interconnect for a given set of objects and a predefined objective function. One well-known variant, which is often used synonymously with the term Steiner tree problem, is the Steiner tree problem in graphs. Given an undirected graph with non-negative edge weights and a subset of vertices, usually referred to as terminals, the Steiner tree problem in graphs requires a tree of minimum weight that contains all terminals and minimizes the total weight of its edges. Further well-known variants are the Euclidean Steiner tree problem and the rectilinear minimum Steiner tree problem.

In graph theory, an independent set, stable set, coclique or anticlique is a set of vertices in a graph, no two of which are adjacent. That is, it is a set of vertices such that for every two vertices in , there is no edge connecting the two. Equivalently, each edge in the graph has at most one endpoint in . A set is independent if and only if it is a clique in the graph's complement. The size of an independent set is the number of vertices it contains. Independent sets have also been called "internally stable sets", of which "stable set" is a shortening.

In graph theory, a vertex cover of a graph is a set of vertices that includes at least one endpoint of every edge of the graph.
In computer science and operations research, approximation algorithms are efficient algorithms that find approximate solutions to optimization problems with provable guarantees on the distance of the returned solution to the optimal one. Approximation algorithms naturally arise in the field of theoretical computer science as a consequence of the widely believed P ≠ NP conjecture. Under this conjecture, a wide class of optimization problems cannot be solved exactly in polynomial time. The field of approximation algorithms, therefore, tries to understand how closely it is possible to approximate optimal solutions to such problems in polynomial time. In an overwhelming majority of the cases, the guarantee of such algorithms is a multiplicative one expressed as an approximation ratio or approximation factor i.e., the optimal solution is always guaranteed to be within a (predetermined) multiplicative factor of the returned solution. However, there are also many approximation algorithms that provide an additive guarantee on the quality of the returned solution. A notable example of an approximation algorithm that provides both is the classic approximation algorithm of Lenstra, Shmoys and Tardos for scheduling on unrelated parallel machines.
In computer science, a polynomial-time approximation scheme (PTAS) is a type of approximation algorithm for optimization problems.
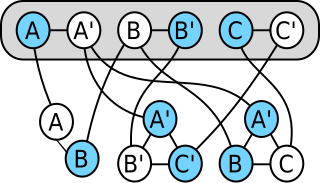
In computability theory and computational complexity theory, a reduction is an algorithm for transforming one problem into another problem. A sufficiently efficient reduction from one problem to another may be used to show that the second problem is at least as difficult as the first.

Professor Sartaj Kumar Sahni is a computer scientist based in the United States, and is one of the pioneers in the field of data structures. He is a distinguished professor in the Department of Computer and Information Science and Engineering at the University of Florida.
The set cover problem is a classical question in combinatorics, computer science, operations research, and complexity theory.

The k-minimum spanning tree problem, studied in theoretical computer science, asks for a tree of minimum cost that has exactly k vertices and forms a subgraph of a larger graph. It is also called the k-MST or edge-weighted k-cardinality tree. Finding this tree is NP-hard, but it can be approximated to within a constant approximation ratio in polynomial time.

In graph theory and graph algorithms, a feedback arc set or feedback edge set in a directed graph is a subset of the edges of the graph that contains at least one edge out of every cycle in the graph. Removing these edges from the graph breaks all of the cycles, producing an acyclic subgraph of the given graph, often called a directed acyclic graph. A feedback arc set with the fewest possible edges is a minimum feedback arc set and its removal leaves a maximum acyclic subgraph; weighted versions of these optimization problems are also used. If a feedback arc set is minimal, meaning that removing any edge from it produces a subset that is not a feedback arc set, then it has an additional property: reversing all of its edges, rather than removing them, produces a directed acyclic graph.
In computational complexity theory, the class APX is the set of NP optimization problems that allow polynomial-time approximation algorithms with approximation ratio bounded by a constant. In simple terms, problems in this class have efficient algorithms that can find an answer within some fixed multiplicative factor of the optimal answer.
In computational complexity theory, the PCP theorem states that every decision problem in the NP complexity class has probabilistically checkable proofs of constant query complexity and logarithmic randomness complexity.
MAX-3SAT is a problem in the computational complexity subfield of computer science. It generalises the Boolean satisfiability problem (SAT) which is a decision problem considered in complexity theory. It is defined as:
In number theory and computer science, the partition problem, or number partitioning, is the task of deciding whether a given multiset S of positive integers can be partitioned into two subsets S1 and S2 such that the sum of the numbers in S1 equals the sum of the numbers in S2. Although the partition problem is NP-complete, there is a pseudo-polynomial time dynamic programming solution, and there are heuristics that solve the problem in many instances, either optimally or approximately. For this reason, it has been called "the easiest hard problem".
Single-machine scheduling or single-resource scheduling is an optimization problem in computer science and operations research. We are given n jobs J1, J2, ..., Jn of varying processing times, which need to be scheduled on a single machine, in a way that optimizes a certain objective, such as the throughput.

In computational complexity theory, a problem is NP-complete when:
- It is a decision problem, meaning that for any input to the problem, the output is either "yes" or "no".
- When the answer is "yes", this can be demonstrated through the existence of a short solution.
- The correctness of each solution can be verified quickly and a brute-force search algorithm can find a solution by trying all possible solutions.
- The problem can be used to simulate every other problem for which we can verify quickly that a solution is correct. In this sense, NP-complete problems are the hardest of the problems to which solutions can be verified quickly. If we could find solutions of some NP-complete problem quickly, we could quickly find the solutions of every other problem to which a given solution can be easily verified.
The vertex k-center problem is a classical NP-hard problem in computer science. It has application in facility location and clustering. Basically, the vertex k-center problem models the following real problem: given a city with facilities, find the best facilities where to build fire stations. Since firemen must attend any emergency as quickly as possible, the distance from the farthest facility to its nearest fire station has to be as small as possible. In other words, the position of the fire stations must be such that every possible fire is attended as quickly as possible.
Identical-machines scheduling is an optimization problem in computer science and operations research. We are given n jobs J1, J2, ..., Jn of varying processing times, which need to be scheduled on m identical machines, such that a certain objective function is optimized, for example, the makespan is minimized.
References
- ↑ Sahni, Sartaj; Gonzalez, Teofilo (1976), "P-complete approximation problems", Journal of the ACM , 23 (3): 555–565, doi:10.1145/321958.321975, hdl: 10338.dmlcz/103883 , MR 0408313 .