Related Research Articles
A pseudorandom number generator (PRNG), also known as a deterministic random bit generator (DRBG), is an algorithm for generating a sequence of numbers whose properties approximate the properties of sequences of random numbers. The PRNG-generated sequence is not truly random, because it is completely determined by an initial value, called the PRNG's seed. Although sequences that are closer to truly random can be generated using hardware random number generators, pseudorandom number generators are important in practice for their speed in number generation and their reproducibility.
A key in cryptography is a piece of information, usually a string of numbers or letters that are stored in a file, which, when processed through a cryptographic algorithm, can encode or decode cryptographic data. Based on the used method, the key can be different sizes and varieties, but in all cases, the strength of the encryption relies on the security of the key being maintained. A key's security strength is dependent on its algorithm, the size of the key, the generation of the key, and the process of key exchange.
Monte Carlo methods, or Monte Carlo experiments, are a broad class of computational algorithms that rely on repeated random sampling to obtain numerical results. The underlying concept is to use randomness to solve problems that might be deterministic in principle. They are often used in physical and mathematical problems and are most useful when it is difficult or impossible to use other approaches. Monte Carlo methods are mainly used in three problem classes: optimization, numerical integration, and generating draws from a probability distribution.
In statistics, Markov chain Monte Carlo (MCMC) methods comprise a class of algorithms for sampling from a probability distribution. By constructing a Markov chain that has the desired distribution as its equilibrium distribution, one can obtain a sample of the desired distribution by recording states from the chain. The more steps that are included, the more closely the distribution of the sample matches the actual desired distribution. Various algorithms exist for constructing chains, including the Metropolis–Hastings algorithm.
Noise reduction is the process of removing noise from a signal. Noise reduction techniques exist for audio and images. Noise reduction algorithms may distort the signal to some degree. Noise rejection is the ability of a circuit to isolate an undesired signal component from the desired signal component, as with common-mode rejection ratio.
In mathematics, discrepancy theory describes the deviation of a situation from the state one would like it to be in. It is also called the theory of irregularities of distribution. This refers to the theme of classical discrepancy theory, namely distributing points in some space such that they are evenly distributed with respect to some subsets. The discrepancy (irregularity) measures how far a given distribution deviates from an ideal one.
A random permutation is a random ordering of a set of objects, that is, a permutation-valued random variable. The use of random permutations is often fundamental to fields that use randomized algorithms such as coding theory, cryptography, and simulation. A good example of a random permutation is the shuffling of a deck of cards: this is ideally a random permutation of the 52 cards.
Algorithmic information theory (AIT) is a branch of theoretical computer science that concerns itself with the relationship between computation and information of computably generated objects (as opposed to stochastically generated), such as strings or any other data structure. In other words, it is shown within algorithmic information theory that computational incompressibility "mimics" (except for a constant that only depends on the chosen universal programming language) the relations or inequalities found in information theory. According to Gregory Chaitin, it is "the result of putting Shannon's information theory and Turing's computability theory into a cocktail shaker and shaking vigorously."
In statistics, resampling is the creation of new samples based on one observed sample. Resampling methods are:
- Permutation tests
- Bootstrapping
- Cross validation

The ziggurat algorithm is an algorithm for pseudo-random number sampling. Belonging to the class of rejection sampling algorithms, it relies on an underlying source of uniformly-distributed random numbers, typically from a pseudo-random number generator, as well as precomputed tables. The algorithm is used to generate values from a monotonically decreasing probability distribution. It can also be applied to symmetric unimodal distributions, such as the normal distribution, by choosing a value from one half of the distribution and then randomly choosing which half the value is considered to have been drawn from. It was developed by George Marsaglia and others in the 1960s.
In statistics and machine learning, ensemble methods use multiple learning algorithms to obtain better predictive performance than could be obtained from any of the constituent learning algorithms alone. Unlike a statistical ensemble in statistical mechanics, which is usually infinite, a machine learning ensemble consists of only a concrete finite set of alternative models, but typically allows for much more flexible structure to exist among those alternatives.
In statistics, a simple random sample is a subset of individuals chosen from a larger set in which a subset of individuals are chosen randomly, all with the same probability. It is a process of selecting a sample in a random way. In SRS, each subset of k individuals has the same probability of being chosen for the sample as any other subset of k individuals. Simple random sampling is a basic type of sampling and can be a component of other more complex sampling methods.
Random search (RS) is a family of numerical optimization methods that do not require the gradient of the problem to be optimized, and RS can hence be used on functions that are not continuous or differentiable. Such optimization methods are also known as direct-search, derivative-free, or black-box methods.

Julian Ernst Besag FRS was a British statistician known chiefly for his work in spatial statistics, and Bayesian inference.
In probability theory and statistics, the Poisson binomial distribution is the discrete probability distribution of a sum of independent Bernoulli trials that are not necessarily identically distributed. The concept is named after Siméon Denis Poisson.
Non-uniform random variate generation or pseudo-random number sampling is the numerical practice of generating pseudo-random numbers (PRN) that follow a given probability distribution. Methods are typically based on the availability of a uniformly distributed PRN generator. Computational algorithms are then used to manipulate a single random variate, X, or often several such variates, into a new random variate Y such that these values have the required distribution. The first methods were developed for Monte-Carlo simulations in the Manhattan project, published by John von Neumann in the early 1950s.
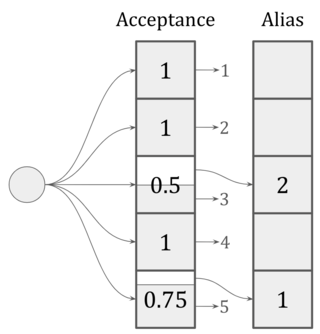
In computing, the alias method is a family of efficient algorithms for sampling from a discrete probability distribution, published in 1974 by A. J. Walker. That is, it returns integer values 1 ≤ i ≤ n according to some arbitrary probability distribution pi. The algorithms typically use O(n log n) or O(n) preprocessing time, after which random values can be drawn from the distribution in O(1) time.
In statistics, some Monte Carlo methods require independent observations in a sample to be drawn from a one-dimensional distribution in sorted order. In other words, all n order statistics are needed from the n observations in a sample. The naive method performs a sort and takes O(n log n) time. There are also O(n) algorithms which are better suited for large n. The special case of drawing n sorted observations from the uniform distribution on [0,1] is equivalent to drawing from the uniform distribution on an n-dimensional simplex; this task is a part of sequential importance resampling.
In quantum computing, quantum supremacy or quantum advantage is the goal of demonstrating that a programmable quantum computer can solve a problem that no classical computer can solve in any feasible amount of time, irrespective of the usefulness of the problem. The term was coined by John Preskill in 2012, but the concept dates back to Yuri Manin's 1980 and Richard Feynman's 1981 proposals of quantum computing.
Differentially private analysis of graphs studies algorithms for computing accurate graph statistics while preserving differential privacy. Such algorithms are used for data represented in the form of a graph where nodes correspond to individuals and edges correspond to relationships between them. For examples, edges could correspond to friendships, sexual relationships, or communication patterns. A party that collected sensitive graph data can process it using a differentially private algorithm and publish the output of the algorithm. The goal of differentially private analysis of graphs is to design algorithms that compute accurate global information about graphs while preserving privacy of individuals whose data is stored in the graph.